Data Architectures for Robust Decision Making
Download as PPTX, PDF71 likes13,265 views

The document discusses designing robust data architectures for decision making. It advocates for building architectures that can easily add new data sources, improve and expand analytics, standardize metadata and storage for easy data access, discover and recover from mistakes. The key aspects discussed are using Kafka as a data bus to decouple pipelines, retaining all data for recovery and experimentation, treating the filesystem as a database by storing intermediate data, leveraging Spark and Spark Streaming for batch and stream processing, and maintaining schemas for integration and evolution of the system.




































errCountStream.foreachRDD(rdd => {
System.out.println("Errors this minute:%d".format(rdd.first()._2))
})
Click to enter confidentiality information](https://image.slidesharecdn.com/stratasj-robustdecisionmaking-150221002740-conversion-gate01/85/Data-Architectures-for-Robust-Decision-Making-36-320.jpg)















































Ad
More Related Content
What's hot (20)
Viewers also liked (6)




Ad
Similar to Data Architectures for Robust Decision Making (20)




















Ad
More from Gwen (Chen) Shapira (20)




















Recently uploaded (20)




















Data Architectures for Robust Decision Making
- 1. Designing Data Architectures for Robust Decision Making Gwen Shapira / Software Engineer
- 2. 2©2014 Cloudera, Inc. All rights reserved. • 15 years of moving data around • Formerly consultant • Now Cloudera Engineer: – Sqoop Committer – Kafka – Flume • @gwenshap About Me
- 3. 3©2014 Cloudera, Inc. All rights reserved. There’s a book on that!
- 4. 4 About you: You know Hadoop
- 5. “Big Data” is stuck at The Lab.
- 6. 6 We want to move to The Factory
- 7. 7Click to enter confidentiality information
- 8. 8 What does it mean to “Systemize”? • Ability to easily add new data sources • Easily improve and expend analytics • Ease data access by standardizing metadata and storage • Ability to discover mistakes and to recover from them • Ability to safely experiment with new approaches Click to enter confidentiality information
- 9. 9 We will discuss: • Actual decision making • Data Science • Machine learning • Algorithms Click to enter confidentiality information We will not discuss: • Architectures • Patterns • Ingest • Storage • Schemas • Metadata • Streaming • Experimenting • Recovery
- 10. 10 So how do we build real data architectures? Click to enter confidentiality information
- 11. 11 The Data Bus
- 12. 1212 Client Source Data Pipelines Start like this.
- 13. 1313 Client Source Client Client Client Then we reuse them
- 14. 1414 Client Backend Client Client Client Then we add consumers to the existing sources Another Backend
- 15. 1515 Client Backend Client Client Client Then it starts to look like this Another Backend Another Backend Another Backend
- 16. 1616 Client Backend Client Client Client With maybe some of this Another Backend Another Backend Another Backend
- 17. 17 Adding applications should be easier We need: • Shared infrastructure for sending records • Infrastructure must scale • Set of agreed-upon record schemas
- 18. 18 Kafka Based Ingest Architecture 18 Source System Source System Source System Source System Kafka decouples Data Pipelines Hadoop Security Systems Real-time monitoring Data Warehouse Kafka Producer s Brokers Consume rs Kafka decouples Data Pipelines
- 19. 19 Retain All Data Click to enter confidentiality information
- 20. 20 Data Pipeline – Traditional View Raw data Raw data Clean data Aggregated dataClean data Enriched data Input Output Waste of diskspace
- 21. 21©2014 Cloudera, Inc. All rights reserved. It is all valuable data Raw data Raw data Clean data Aggregated dataClean data Enriched data Filtered data Dash board Report Data scientis t Alerts OMG
- 22. 22 Hadoop Based ETL – The FileSystem is the DB /user/… /user/gshapira/testdata/orders /data/<database>/<table>/<partition> /data/<biz unit>/<app>/<dataset>/partition /data/pharmacy/fraud/orders/date=20131101 /etl/<biz unit>/<app>/<dataset>/<stage> /etl/pharmacy/fraud/orders/validated
- 23. 23 Store intermediate data /etl/<biz unit>/<app>/<dataset>/<stage>/<dataset_id> /etl/pharmacy/fraud/orders/raw/date=20131101 /etl/pharmacy/fraud/orders/deduped/date=20131101 /etl/pharmacy/fraud/orders/validated/date=20131101 /etl/pharmacy/fraud/orders_labs/merged/date=20131101 /etl/pharmacy/fraud/orders_labs/aggregated/date=20131101 /etl/pharmacy/fraud/orders_labs/ranked/date=20131101 Click to enter confidentiality information
- 24. 24 Batch ETL is old news Click to enter confidentiality information
- 25. 25 Small Problem! • HDFS is optimized for large chunks of data • Don’t write individual events of micro-batches • Think 100M-2G batches • What do we do with small events? Click to enter confidentiality information
- 26. 26 Well, we have this data bus… Click to enter confidentiality information 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 0 1 2 3 4 5 6 7 8 9 1 0 1 1 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 Partition 1 Partition 2 Partition 3 Writes Old New
- 27. 27 Kafka has topics How about? <biz unit>.<app>.<dataset>.<stage> pharmacy.fraud.orders.raw pharmacy.fraud.orders.deduped pharmacy.fraud.orders.validated pharmacy.fraud.orders_labs.merged Click to enter confidentiality information
- 28. 28©2014 Cloudera, Inc. All rights reserved. It’s (almost) all topics Raw data Raw data Clean data Aggregated dataClean data Filtered data Dash board Report Data scientis t Alerts OMG Enriched Data
- 29. 29 Benefits • Recover from accidents • Debug suspicious results • Fix algorithm errors • Experiment with new algorithms • Expend pipelines • Jump-start expended pipelines Click to enter confidentiality information
- 30. 30 Kinda Lambda
- 31. 31 Lambda Architecture • Immutable events • Store intermediate stages • Combine Batches and Streams • Reprocessing Click to enter confidentiality information
- 32. 32 What we don’t like Maintaining two applications Often in two languages That do the same thing Click to enter confidentiality information
- 33. 33 Pain Avoidance #1 – Use Spark + SparkStreaming • Spark is awesome for batch, so why not? – The New Kid that isn’t that New Anymore – Easily 10x less code – Extremely Easy and Powerful API – Very good for machine learning – Scala, Java, and Python – RDDs – DAG Engine Click to enter confidentiality information
- 34. 34 Spark Streaming • Calling Spark in a Loop • Extends RDDs with DStream • Very Little Code Changes from ETL to Streaming Confidentiality Information Goes Here
- 35. 35 Spark Streaming Confidentiality Information Goes Here Single Pass Source Receiver RDD Source Receiver RDD RDD Filter Count Print Source Receiver RDD RDD RDD Single Pass Filter Count Print Pre-first Batch First Batch Second Batch
- 36. 36 Small Example val sparkConf = new SparkConf() .setMaster(args(0)).setAppName(this.getClass.getCanonicalName) val ssc = new StreamingContext(sparkConf, Seconds(10)) // Create the DStream from data sent over the network val dStream = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_AND_DISK_SER) // Counting the errors in each RDD in the stream val errCountStream = dStream.transform(rdd => ErrorCount.countErrors(rdd)) val stateStream = errCountStream.updateStateByKey[Int](updateFunc) errCountStream.foreachRDD(rdd => { System.out.println("Errors this minute:%d".format(rdd.first()._2)) }) Click to enter confidentiality information
- 37. 37 Pain Avoidance #2 – Split the Stream Why do we even need stream + batch? • Batch efficiencies • Re-process to fix errors • Re-process after delayed arrival What if we could re-play data? Click to enter confidentiality information
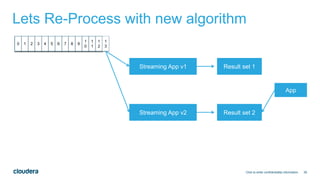
- 38. 38 Lets Re-Process with new algorithm Click to enter confidentiality information 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 Streaming App v1 Streaming App v2 Result set 1 Result set 2 App
- 39. 39 Lets Re-Process with new algorithm Click to enter confidentiality information 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 Streaming App v1 Streaming App v2 Result set 1 Result set 2 App
- 40. 40 Oh no, we just got a bunch of data for yesterday! Click to enter confidentiality information 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 Streaming App Streaming App Today Yesterday
- 41. 41 Note: No need to choose between the approaches. There are good reasons to do both. Click to enter confidentiality information
- 42. 42 Prediction: Batch vs. Streaming distinction is going away. Click to enter confidentiality information
- 43. 43 Yes, you really need a Schema Click to enter confidentiality information
- 44. 44 Schema is a MUST HAVE for data integration Click to enter confidentiality information
- 46. 46 Remember that we want this? 46 Source System Source System Source System Source System Hadoop Security Systems Real-time monitoring Data Warehouse Kafka Producer s Brokers Consume rs
- 47. 47 This means we need this: Click to enter confidentiality information Source System Source System Source System Source System Hadoop Security Systems Real-time monitoring Data Warehouse Kafka Schema Repository
- 48. 48 We can do it in few ways • People go around asking each other: “So, what does the 5th field of the messages in topic Blah contain?” • There’s utility code for reading/writing messages that everyone reuses • Schema embedded in the message • A centralized repository for schemas – Each message has Schema ID – Each topic has Schema ID Click to enter confidentiality information
- 49. 49 I Avro • Define Schema • Generate code for objects • Serialize / Deserialize into Bytes or JSON • Embed schema in files / records… or not • Support for our favorite languages… Except Go. • Schema Evolution – Add and remove fields without breaking anything Click to enter confidentiality information
- 50. 50 Schemas are Agile • Leave out MySQL and your favorite DBA for a second • Schemas allow adding readers and writers easily • Schemas allow modifying readers and writers independently • Schemas can evolve as the system grows • Allows validating data soon after its written – No need to throw away data that doesn’t fit! Click to enter confidentiality information
- 51. 51Click to enter confidentiality information
- 52. 52 Woah, that was lots of stuff! Click to enter confidentiality information
- 53. 53 Recap – if you remember nothing else… • After the POC, its time for production • Goal: Evolve fast without breaking things For this you need: • Keep all data • Design pipeline for error recovery – batch or stream • Integrate with a data bus • And Schemas
- 54. Thank you
Editor's Notes
- #3: This gives me a lot of perspective regarding the use of Hadoop
- #6: Not everyone, obviously. But I see a lot of “POC” type use-cases. 1 use case, maybe 3 data sources, 2 interesting insights from analysis. Everything requires lots of manual labor.
- #8: Shikumika means “systemize.” This is the step that is crucial to improvement at any large entity. Shikumika means creating a base on which you can continue the improvement process. Because at an individual level, the original three steps are sufficient: build a hypothesis; act on it; and verify the results. If the validation proves the hypothesis to be the right one, you can simply continue acting on it. But for an entire organization, that’s not enough. The steps could end up as a hollow slogan. From the viewpoint of an organization, the cycle of hypothesizing, practicing and validating, conducted by an employee or a department, is a small experiment. If a hypothesis holds true in a small experiment, we can run with that hypothesis on a larger, organization-wide scale.
- #9: We are looking for AGILE. The ability to expend, grow and evolve. To be flexible without adding tons of risk and overhead.
- #14: Then we end up adding clients to use that source.
- #15: But as we start to deploy our applications we realizet hat clients need data from a number of sources. So we add them as needed.
- #17: But over time, particularly if we are segmenting services by function, we have stuff all over the place, and the dependencies are a nightmare. This makes for a fragile system.
- #19: Kafka is a pub/sub messaging system that can decouple your data pipelines. Most of you are probably familiar with it’s history at LinkedIn and they use it as a high throughput relatively low latency commit log. It allows sources to push data without worrying about what clients are reading it. Note that producer push, and consumers pull. Kafka itself is a cluster of brokers, which handles both persisting data to disk and serving that data to consumer requests.
- #42: Approach #1 – easier to develop and deploy in production. Doesn’t require a set of “spare” servers for the second stream Approach #2 – allows for real-time experiments
- #43: There will be tools and patterns to move seamlessly between the two. Perhaps you won’t even need to care – just say how often you want the data refreshed – every day? Hour? 5 minutes? 5 seconds? 5 milliseconds?
- #45: Sorry, but “Schema on Read” is kind of B.S. We admit that there is a schema, but we want to “ingest fast”, so we shift the burden to the readers. But the data is written once and read many many times by many different people. They each need to figure this out on their own? This makes no sense. Also, how are you going to validate the data without a schema?
- #46: But over time, particularly if we are segmenting services by function, we have stuff all over the place, and the dependencies are a nightmare. This makes for a fragile system.
- #47: Kafka is a pub/sub messaging system that can decouple your data pipelines. Most of you are probably familiar with it’s history at LinkedIn and they use it as a high throughput relatively low latency commit log. It allows sources to push data without worrying about what clients are reading it. Note that producer push, and consumers pull. Kafka itself is a cluster of brokers, which handles both persisting data to disk and serving that data to consumer requests.
- #49: https://github.com/schema-repo/schema-repo