Data engineering and analytics using python
Download as PPTX, PDF2 likes1,365 views

This document provides an overview of data engineering and analytics using Python. It discusses Jupyter notebooks and commonly used Python modules for data science like Pandas, NumPy, SciPy, Matplotlib and Seaborn. It describes Anaconda distribution and the key features of Pandas including data loading, structures like DataFrames and Series, and core operations like filtering, mapping, joining, sorting, cleaning and grouping. It also demonstrates data visualization using Seaborn and a machine learning example of linear regression.













































![Introduction to Pandas and Time Series Analysis [PyCon DE]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysispyconde-170617163724-thumbnail.jpg?width=560&fit=bounds)


















Ad
More Related Content
What's hot (20)
Similar to Data engineering and analytics using python (20)


















Ad
Recently uploaded (20)




















Ad
Data engineering and analytics using python
- 1. Data Engineering and Analytics using Python PURNA CHANDER RAO. KATHULA
- 2. Talking Topics Jupyter notebook About me Python modules for Data Science Anaconda Pandas About pandas Data Munging / Data Preparation. Demo Seaborn About seaborn Machine Learning Linear Regression.
- 3. About me.. Job Title = Architect QA Build Tools using Python for QA automation testing . Currently Learning
- 4. Python modules for Data Science Packages used for Data Analysis and Analytics Jupyter Notebook Pandas Numpy Scipy Matplotlib Seaborn Scikitlearn
- 5. Anaconda
- 7. What is Anaconda ? Essentially a Large ( ~ 400 MB ) Python Installation. But Contains Everything you need for Data Analysis Unless you have a special reason not to , you should just install and use this.
- 8. Pandas
- 9. About Pandas What is Pandas ? Pandas is a Python library for data analysis and data manipulation. A python version of the R data.frame library. Key Features of Pandas It has API’s for loading data from different file formats into memory. ( exel, tsv, csv, db and etc). Data is structured in the form of Rows and Columns. Retrieval of data is similar as SQL, can perform all the operations such as Groupby, Joins, Views and etc.. Merging of data from multiple datasets. Does support much of DataTime series functionality, Timezone, Business Days, Holidays and etc.. Boolean Indexing Fancy Indexing
- 10. Core DataStructures of Pandas DataFrames Series Core Operations Create Select Insert Map Join Sort Clean ApplyMap View Update Filter Append Group Summarize Confirm Rotate
- 11. Create ( Creating a DataFrame) View ( Viewing the rows and columns)
- 12. View ( Viewing the rows and columns)
- 13. Insert ( Adding a new column to dataframe)
- 14. Filter ( Slicing and dicing the datframe)
- 15. Map ( Map() and Apply map())
- 16. Append (Joining the dataframes based on x-axis=0 )
- 17. Concat (Joining the dataframes on Axis = 0 or 1)
- 18. Join ( Inner , Left, Right , Outer)
- 19. Join ( Inner )
- 20. Join ( Outer)
- 21. Join ( Left)
- 22. Join ( Right)
- 24. Sort (by columns ascending True or False)
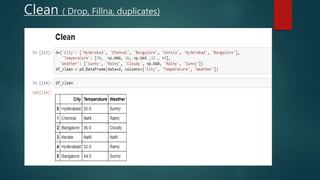
- 25. Clean ( Drop, Fillna, duplicates)
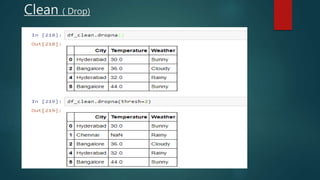
- 26. Clean ( Drop)
- 27. Clean ( Fillna ( method=‘ffill / bfill’)
- 28. Conform ( reindex() / resample, dropping / NAN as needed)
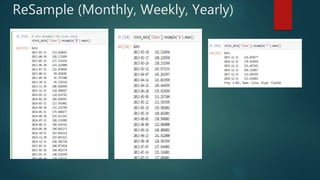
- 29. ReSample ()
- 30. ReSample (Monthly, Weekly, Yearly)
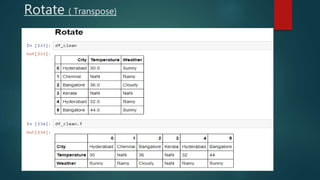
- 33. Rotate ( Stack)
- 36. What is Seaborn? Seaborn provides a high-level interface to matplotlib. It provides a high level interface for drawing attractive statistical graphs.
- 37. Demo ( Restaurant Dataset visualization)
- 38. Machine Learning ( Linear Regression) DEMO