Data Engineering with Solr and Spark
15 likes11,559 views

Grant Ingersoll presented on using Apache Solr and Apache Spark for data engineering. He discussed how Solr can be used for indexing and searching large amounts of data, while Spark enables large-scale processing on the indexed data. Lucidworks' Fusion product combines Solr and Spark capabilities to allow search-driven applications and machine learning on indexed content.















































![Streaming Expression Response
{"responseHeader":
{"status":
0,
"QTime":
1},
"tuples":
{
"numFound":
-‐1,
"start":
-‐1,
"docs":
[
{"id":
"doc1",
"field_i":
1},
{"id":
"doc2",
"field_i":
2},
{"EOF":
true}]
}}](https://image.slidesharecdn.com/gwo-2016-160318151847/85/Data-Engineering-with-Solr-and-Spark-49-320.jpg)




Data Engineering with Solr and Spark
- 2. Wifi •GTVisitor •hotel/guest •pass: 76FCE
- 3. Data Engineering with Solr and Spark Grant Ingersoll @gsingers CTO, Lucidworks
- 4. Lucidworks Fusion Is Search-‐Driven Everything •Drive next genera=on relevance via Content, Collabora=on and Context •Harness best in class Open Source: Apache Solr + Spark •Simplify applica=on development and reduce ongoing maintenance Fusion is built on three core principles:
- 5. Fusion Architecture RESTAPI Worker Worker Cluster Mgr. Apache Spark Shards Shards Apache Solr HDFS(Optional) Shared Config Mgmt Leader Election Load Balancing ZK 1 Apache Zookeeper ZK N DATABASEWEBFILELOGSHADOOP CLOUD Connectors Aler=ng/Messaging NLP Pipelines Blob Storage Scheduling Recommenders/Signals … Core Services Admin UI SECURITY BUILT-‐IN
- 8. • Why Search for Data Engineering? • Quick intro to Solr • Quick intro to Spark • Solr + Spark • Relevance 101 • Machine learning with Spark and Solr • What’s next? Let’s Do This Examples throughout!
- 9. The Importance of Importance
- 10. Search-‐Driven Everything Customer Service Customer Insights Fraud Surveillance Research Portal Online Retail Digital Content
- 11. • Data Engineering, esp. with text, is a strange and magical world filled with… – Evil villains – Jesters – Wizards – Unicorns – Heroes! • In other words, no system will be perfect Caveat Emptor: Data Engineering EdiLon
- 12. • You will spend most of your time in data engineering, search, machine learning and NLP doing “grunt” work nicely labeled as: – Preprocessing – Feature Selection – Sampling – Validation/testing/etc. – Content extraction – ETL • Corollary: Start with simple, tried and true algorithms, then iterate
- 13. Why do data engineering with Solr and Spark? Solr Spark • Data exploration and visualization • Easy ingestion and feature selection • Powerful ranking features • Quick and dirty classification and clustering • Simple operation and scaling • Stats and math built in • Advanced machine learning: MLLib, Mahout, Deep Learning4j • Fast, large scale iterative algorithms • General purpose batch/streaming compute engine Whole collection analysis! • Lots of integrations with other big data systems
- 14. • Apache Lucene • Grouping and Joins • Stats, expressions, transformations and more • Lang. Detection • Extensible • Massive Scale/Fault tolerance Solr Key Features • Full text search (Info Retr.) • Facets/Guided Nav galore! • Lots of data types • Spelling, auto-complete, highlighting • Cursors • More Like This • De-duplication
- 15. Lucene for the Win! • Vector Space or Probabilistic, it’s your choice! • Killer FST • Wicked fast • Pluggable compression, queries, indexing and more • Advanced Similarity Models • Lang. Modeling, Divergence from Random, more • Easy to plug-in ranking
- 16. Solr and Your Tools • Data ingest: • JSON, CSV, XML, Rich types (PDF, etc.), custom • Clients for Python, R, Java, .NET and more • http://cran.r-project.org/web/packages/solr/index.html, amongst others • Output formats: JSON, CSV, XML, custom
- 17. Basics of Solr Requests • Querying: • Simple: term, phrases, boolean, wildcards, weights • Advanced: query parsers, spatial, etc. • Facets: term, query, range, pivot, stats • Highlighting • Spell checking
- 18. Solr Basics
- 19. Spark Key Features • General purpose, high powered cluster computing system • Modern, faster alternative to MapReduce • 3x faster w/ 10x less hardware for Terasort • Great for iterative algorithms • APIs for Java, Scala, Python and R • Rich set of add-on libraries for machine learning, graph processing, integrations with SQL and other systems • Deploys: Standalone, Hadoop YARN, Mesos
- 20. Spark Basics • Resilient Distributed Datasets • Spark SQL provides a Data Source, which provides a DataFrame • DataFrames — a DSL for distributed data manipulation • Seamless integration with other Spark tech: SparkR, Python
- 21. Spark Components Spark Core Spark SQL Spark Streaming MLlib (machine learning) GraphX (BSP) Hadoop YARN Mesos Standalone HDFS Execution Model The Shuffle Caching components engine cluster mgmt Tachyon languages Scala Java Python R shared memory
- 22. Why Spark for Solr? • Build the index very, very quickly! • Aggregations • Boosts, stats, iterative computations • Offline compute to update index with additional info (e.g. PageRank, popularity) • Whole corpus analytics, clustering, classification • Joins with other storage (Cassandra, HDFS, DB, HBase)
- 23. Why Solr for Spark? • Massive simplification of operations! • Non “dumb” distributed, resilient storage • Random access with smart queries • Table scans • Advanced filtering, feature selection • Schemaless when you want, predefined when you don’t • Spatial, columnar, sparse
- 24. Spark + Solr in Anger http://github.com/lucidworks/spark-solr Map<String, String> options = new HashMap<String, String>(); options.put("zkhost", zkHost); options.put("collection”, "tweets"); DataFrame df = sqlContext.read().format("solr").options(options).load(); count = df.filter(df.col("type_s").equalTo(“echo")).count();
- 25. Spark Shell in a Nutshell • Common commands • Solr in Spark: queries, filters and other requests • See commands.md in the Github repo
- 27. But is it relevant?
- 30. • Wing it • Ask — Caveat Emptor • Log analysis • Experimentation: A/B (A/A) testing Approaches
- 31. • Precision/Recall (also, Mean Avg. Precision) • Mean Reciprocal Rank (MRR) • Number of {Zero|Embarrassing} Results • Inter-Annotator Agreement • Normalized Discounted Cumulative Gain (NDCG) Common Metrics
- 32. Tips and Traps
- 33. Algorithms Collective Intelligence Editors/Rules The mainstay of any approach: leverages Lucene/Solr’s built in similarity engine, function queries and other capabilities to determine importance based on core index Especially effective for curating the long tail, feedback from users and other systems provide key insights into importance. Can also be used to inform the business about trends and interests. Should be used sparingly to handle key situations such as promotions and edge cases. Review often. Encourage experimentation instead. Works well for landing pages, boosts and blocks where you know the answers. Not to be confused with curating content. Big Picture on Relevance
- 34. • Similarity Models Default, BM25F, others • Function Queries, Reranking, Boosts • Phrases are almost always a win (edismax does most of this for you) e.g.: (exact match terms)^100 AND (“termA termB…”~10)^50 AND (termA AND termB…)^10 AND (termA OR termB) • Mind your analysis Algorithms
- 35. • UI, UI, UI! • 1000’s of rules • Second is the first loser • Local minimum • Pet peeve queries • Oprah effect • Assumptions It’s a trap!
- 36. Level up
- 37. • Spark ships with good out of the box machine learning capabilities • Spark-Solr brings enhanced feature selection tools via Lucene analyzers • Examples k-means word2vec Find synonyms Machine Learning at Work
- 38. Sneak Peek
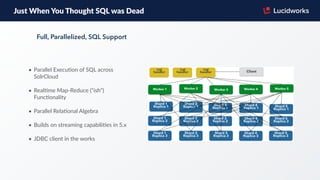
- 39. • Parallel Execu=on of SQL across SolrCloud • Real=me Map-‐Reduce (“ish”) Func=onality • Parallel Rela=onal Algebra • Builds on streaming capabili=es in 5.x • JDBC client in the works Just When You Thought SQL was Dead Full, Parallelized, SQL Support
- 40. • Lots of Func=ons: • Search, Merge, Group, Unique, Parallel, Select, Reduce, Select, innerJoin, hashJoin, Top, Rollup, Facet, Stats, Update, JDBC, Intersect, Complement, Logit • Composable Streams • Query op=miza=on built in SQL Guts Example select str_s, count(*), sum(field_i), min(field_i), max(field_i), avg(field_i) from collection1 where text=’XXXX’ group by str_s rollup( search(collection1, q=”(text:XXXX)”, qt=”/export”, fl=”str_s,field_i”, partitionKeys=str_s, sort=”str_s asc”, zkHost=”localhost:9989/solr”), over=str_s, count(*), sum(field_i), min(field_i), max(field_i), avg(field_i)
- 41. • Provides replica=on between two or more SolrCloud clusters located in two or more data centers • Uses exis=ng transac=on logs • Asynchronous indexing • No Single Point of Failure or boglenecks • Leader-‐to-‐leader communica=on to ensure updates are only sent once Never Go Down, or at least Recover Quickly! Cross Data Center Replication
- 42. • Graph Traversal • Find all tweets men=oning “Solr” by me or people I follow • Find all drah blog posts about “Parallel SQL” wrigen by a developer • Find 3-‐star hotels in NYC my friends stayed in last year • BM25F Default Similarity • Geo3D search Make ConnecLons, Get BeXer Results
- 43. • Jegy 9.3 and hgp2 (6.x) • Fully mul=plexed over a single connec=on • Reduced chance of distributed deadlock • Backup/Restore API • Op=miza=ons to distributed search algorithm • AngularJS-‐based UI But Wait! There’s More!
- 45. Resources • This code: https://github.com/Lucidworks/fusion- examples/tree/master/great-wide-open-2016 • Company: http://www.lucidworks.com • Our blog: http://www.lucidworks.com/blog • Book: http://www.manning.com/ingersoll • Solr: http://lucene.apache.org/solr • Fusion: http://www.lucidworks.com/products/fusion • Twitter: @gsingers
- 46. Appendix A: SQL details
- 47. Streaming API & Expressions ●API ○ Java API to provide programming framework ○ Returns tuples as a JSON stream ○ org.apache.solr.client.solrj.io ●Expressions ○ String Query Language ○ Serialization format ○ Allows non-Java programmers to access Streaming API DocValues must be enabled for any field to be returned
- 48. Streaming Expression Request curl -‐-‐data-‐urlencode 'stream=search(sample, q="*:*", fl="id,field_i", sort="field_i asc")' http://localhost:8901/solr/sample/stream
- 49. Streaming Expression Response {"responseHeader": {"status": 0, "QTime": 1}, "tuples": { "numFound": -‐1, "start": -‐1, "docs": [ {"id": "doc1", "field_i": 1}, {"id": "doc2", "field_i": 2}, {"EOF": true}] }}
- 50. Architecture ●MapReduce-ish ○ Borrows Shuffling concept from M/R ●Logical tiers for performing the query ○ SQL tier: translates SQL to streaming expressions for parallel query plan, selects worker nodes, merges results ○ Worker tier: executes parallel query plan, streams tuples from data tables back ○ Data Table tier: queries SolrCloud collections, performs initial sort and partitioning of results for worker nodes
- 51. JDBC Client ●Parallel SQL includes a “thin” JDBC client ●Expanded to include SQL Clients such as DbVisualizer (SOLR-8502) ●Client only works with Parallel SQL features
- 52. Learning More Joel Bernstein’s presentation at Lucene Revolution: ●https://www.youtube.com/watch?v=baWQfHWozXc Apache Solr Reference Guide: ●https://cwiki.apache.org/confluence/display/solr/ Streaming+Expressions ●https://cwiki.apache.org/confluence/display/solr/Parallel +SQL+Interface
- 53. Spark Architecture Spark Master (daemon) Spark Slave (daemon) my-spark-job.jar (w/ shaded deps) My Spark App SparkContext (driver) • Keeps track of live workers • Web UI on port 8080 • Task Scheduler • Restart failed tasks Spark Executor (JVM process) Tasks Executor runs in separate process than slave daemon Spark Worker Node (1...N of these) Each task works on some partition of a data set to apply a transformation or action Cache Losing a master prevents new applications from being executed Can achieve HA using ZooKeeper and multiple master nodes Tasks are assigned based on data-locality When selecting which node to execute a task on, the master takes into account data locality • RDD Graph • DAG Scheduler • Block tracker • Shuffle tracker