Data Integration through Data Virtualization (SQL Server Konferenz 2019)
9 likes3,095 views

Data Integration through Data Virtualization - PolyBase and new SQL Server 2019 Features (Presented at SQL Server Konferenz 2019 on February 21st, 2019)












































































![Create External Table
CREATE EXTERNAL TABLE [SchemaName].[TableName] (
[ColumnName] INT NOT NULL
) WITH (
LOCATION = <FileName>',
DATA_SOURCE = <DataSourceName>,
FILE_FORMAT = <FileFormatName>
)](https://image.slidesharecdn.com/sqlkonferenz-cathrinewilhelmsen-datavirtualization-190221100634/85/Data-Integration-through-Data-Virtualization-SQL-Server-Konferenz-2019-78-320.jpg)













![Unexpected error encountered filling record
reader buffer: HadoopExecutionException:
Too long string in column [-1]:
Actual len = [4242]. MaxLEN=[4000]](https://image.slidesharecdn.com/sqlkonferenz-cathrinewilhelmsen-datavirtualization-190221100634/85/Data-Integration-through-Data-Virtualization-SQL-Server-Konferenz-2019-92-320.jpg)
















































































Ad
More Related Content
What's hot (20)
Similar to Data Integration through Data Virtualization (SQL Server Konferenz 2019) (20)


















Ad
More from Cathrine Wilhelmsen (20)




















Ad
Recently uploaded (20)




















Data Integration through Data Virtualization (SQL Server Konferenz 2019)
- 1. Data Integration through Data Virtualization Cathrine Wilhelmsen, Inmeta @cathrinew | cathrinew.net February 21st 2019
- 2. Abstract Data virtualization is an alternative to Extract, Transform and Load (ETL) processes. It handles the complexity of integrating different data sources and formats without requiring you to replicate or move the data itself. Save time, minimize effort, and eliminate duplicate data by creating a virtual data layer using PolyBase in SQL Server. In this session, we will first go through fundamental PolyBase concepts such as external data sources and external tables. Then, we will look at the PolyBase improvements in SQL Server 2019. Finally, we will create a virtual data layer that accesses and integrates both structured and unstructured data from different sources. Along the way, we will cover lessons learned, best practices, and known limitations.
- 4. …the next 60 minutes… PolyBase Virtual Data Layer Data Virtualization Data Integration
- 6. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 7. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 8. Combine Data Extract Transform Load Extract Load Transform Data Ingestion Data Preparation Data Wrangling
- 9. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 11. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 12. Separate Sources SQL Server Oracle Teradata MongoDB Hadoop Azure Blob Storage Azure Data-Lake Local File System
- 13. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 15. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 16. Valuable Information What you need Answer questions Solve problems Timesaving Reduce effort Improve efficiency
- 17. Combine Data in Different Formats from Separate Sources into Useful and Valuable Information
- 20. ETL – Extract Transform Load ELT – Extract Load Transform
- 21. ETL – Extract Transform Load ELT – Extract Load Transform = data movement
- 22. Data Movement: Costs Duplicated storage costs Need resources to build and maintain
- 23. Data Movement: Speed Takes time to build and maintain Delays before data can be used
- 24. Data Movement: Security Increased attack surface area Inconsistent security models
- 25. Data Movement: Data Quality More storage layers and pipelines Higher complexity
- 26. Data movement is a barrier to faster insights - Microsoft
- 28. Data Virtualization Logical Layers and Abstractions (Near) Real-Time View of Data Store in separate locations View in one location
- 29. Data Virtualization: Costs Lower storage costs Fewer resources to build and maintain
- 30. Data Virtualization: Speed No data latency Rapid iterations and prototypes
- 31. Data Virtualization: Security Smaller attack surface area Consistent security models
- 32. Data Virtualization: Data Quality Fewer storage layers and pipelines Less complexity
- 33. Data virtualization creates solutions - Microsoft
- 34. Data Movement = Bad ? Data Virtualization = Good ?
- 35. Data Movement = Bad ? Data Virtualization = Good ? no, just different use cases!
- 36. PolyBase
- 37. PolyBase Feature in SQL Server 2016 and later Query tables and files using T-SQL Used to query, import, and export data
- 39. PolyBase in SQL Server 2016 / 2017 Hadoop Azure Blob Storage Azure Data Lake
- 40. PolyBase in SQL Server 2019 Hadoop Azure Blob Storage Azure Data Lake SQL Server Oracle Teradata MongoDB
- 41. ODBC NoSQL Relational Databases Big Data PolyBase
- 42. How to use PolyBase? 1. Install PolyPase 2. Configure PolyBase Connectivity 3. Create Database Master Key 4. Create Database Scoped Credential 5. ...
- 43. How to use PolyBase? 4. ... 5. Create External Data Sources 6. Create External File Formats 7. Create External Tables 8. Create Statistics
- 44. Install PolyBase
- 45. 1. Install Prerequisites Microsoft .NET Framework 4.5 Oracle Java SE Runtime Environment (JRE) 7 or 8 2. Install PolyBase Single Node or Scale-Out Group 3. Enable PolyBase
- 46. Install Prerequisites Microsoft .NET Framework 4.5 https://www.microsoft.com/nl-nl/download/details.aspx?id=30653 Oracle Java SE Runtime Environment (JRE) 7 or 8 https://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
- 47. Install PolyBase Note: PolyBase can be installed on only one SQL Server instance per machine. Note: After you install PolyBase either standalone or in a scale-out group, you have to uninstall and reinstall to change it. . . . Ask me how I know : )
- 48. Enable PolyBase sp_configure 'polybase enabled', 1; RECONFIGURE;
- 51. 1. Configure PolyBase Connectivity 2. Restart Services SQL Server SQL Server PolyBase Engine SQL Server PolyBase Data Movement
- 52. Configure PolyBase Connectivity sp_configure 'hadoop connectivity', 7; RECONFIGURE;
- 53. Configure PolyBase Connectivity Hadoop Connectivity: • Specify type of data source • Values: 0-7 • 1, 4, 7: Multiple Data Sources
- 56. Restart Services
- 57. Restart Services
- 59. Create Database Master Key CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
- 61. Create Database Scoped Credential CREATE DATABASE SCOPED CREDENTIAL <CredentialName> WITH IDENTITY = '<identity>', SECRET = '<secret>';
- 63. Create External Data Source
- 64. Create External Data Source
- 65. Create External Data Source
- 66. Create External Data Source CREATE EXTERNAL DATA SOURCE <HadoopName> WITH ( TYPE = HADOOP, LOCATION ='<hdfs://...>', CREDENTIAL = <CredentialName>, RESOURCE_MANAGER_LOCATION = '<ip>' );
- 67. Create External Data Source CREATE EXTERNAL DATA SOURCE <AzureBlobName> WITH ( TYPE = HADOOP, LOCATION ='<wasbs://...>', CREDENTIAL = <CredentialName> );
- 68. Create External Data Source CREATE EXTERNAL DATA SOURCE <OracleName> WITH ( LOCATION ='<oracle://...>', CREDENTIAL = <CredentialName> );
- 70. Create External File Format
- 71. Create External File Format
- 72. Create External File Format
- 73. Create External File Format CREATE EXTERNAL FILE FORMAT <FileFormatName> WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ';', USE_TYPE_DEFAULT = TRUE ) );
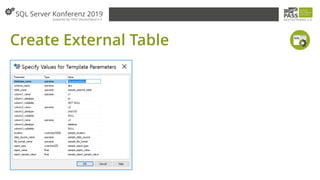
- 78. Create External Table CREATE EXTERNAL TABLE [SchemaName].[TableName] ( [ColumnName] INT NOT NULL ) WITH ( LOCATION = <FileName>', DATA_SOURCE = <DataSourceName>, FILE_FORMAT = <FileFormatName> )
- 80. Create Statistics Note: To create statistics, SQL Server imports the external data into temp table first. Remember to choose sampling or full scan. Note: Updating statistics is not supported. Drop and re-create instead.
- 81. Create Statistics CREATE STATISTICS <StatName> ON <TableName>(<ColumnName>); CREATE STATISTICS <StatName> ON <TableName>(<ColumnName>) WITH FULLSCAN;
- 82. All Done
- 83. Verify using Catalog Views SELECT * FROM sys.external_data_sources SELECT * FROM sys.external_file_formats; SELECT * FROM sys.external_tables;
- 84. T-SQL All The Things :)
- 85. …or…?
- 86. PolyBase can be grumpy :(
- 87. Unexpected error encountered filling record reader buffer: HadoopExecutionException: Not enough columns in this line.
- 88. Unexpected error encountered filling record reader buffer: HadoopExecutionException: Too many columns in the line.
- 89. Unexpected error encountered filling record reader buffer: HadoopExecutionException: Could not find a delimiter after string delimiter.
- 90. Unexpected error encountered filling record reader buffer: HadoopExecutionException: Error converting data type NVARCHAR to INT.
- 91. Unexpected error encountered filling record reader buffer: HadoopExecutionException: Conversion failed when converting the NVARCHAR value '"0"' to data type BIT.
- 92. Unexpected error encountered filling record reader buffer: HadoopExecutionException: Too long string in column [-1]: Actual len = [4242]. MaxLEN=[4000]
- 93. Msg 46518, Level 16, State 12, Line 1: The type 'nvarchar(max)' is not supported with external tables.
- 94. Msg 2717, Level 16, State 2, Line 1: The size (10000) given to the parameter exceeds the maximum allowed (4000).
- 95. Msg 131, Level 15, State 2, Line 1: The size (10000) given to the column exceeds the maximum allowed for any data type (8000).
- 96. = Know your data :)
- 97. SQL Server 2019 Big Data Clusters
- 98. SQL Server 2019 Big Data Clusters SQL Server, Spark, and HDFS Scalable clusters of containers Runs on Kubernetes
- 99. Kubernetes Pod Kubernetes Pod Kubernetes Pod Kubernetes Pod SQL Server Master Instance SQL Server HDFS Data Node SparkSQL Server HDFS Data Node Spark SQL Server HDFS Data Node Spark SQL Server HDFS Data Node Spark
- 101. Build Virtual Data Layer Scenarios: 1. Text Files in Azure Blob Storage 2. Tables in Oracle Database
- 102. Text Files in Azure Blob Storage
- 103. Tables in Oracle Database
- 104. DEMO Build Virtual Data Layer in SSMS
- 105. It's as easy as 1, 2, 3!
- 106. …4, 5, 6, 7, 8, 9, 10…
- 107. Is there an easier way?
- 109. Biml 💚 PolyBase Ben Weissman: Using Biml to automagically keep your external polybase tables in sync! https://www.solisyon.de/biml-polybase-external-tables/
- 111. Azure Data Studio 1. Install Azure Data Studio docs.microsoft.com/en-us/sql/azure-data-studio/download 2. Install Extension: SQL Server 2019 (Preview) docs.microsoft.com/en-us/sql/azure-data-studio/sql-server-2019-extension
- 112. Extension: SQL Server 2019 (Preview)
- 113. Extension: SQL Server 2019 (Preview) Double-clicking the .vsix file doesn't work…
- 114. Extension: SQL Server 2019 (Preview) …install preview extensions from Azure Data Studio
- 116. Azure Data Studio Wizard: CSV Files
- 124. Azure Data Studio Wizard: Oracle
- 134. DEMO Build Virtual Data Layer in ADS
- 135. Next Steps
- 136. Where can I learn more? Microsoft SQL Docs: docs.microsoft.com/sql
- 137. Where can I learn more? Kevin Feasel: 36chambers.wordpress.com/polybase
- 138. How can I try PolyBase? Microsoft Hands-on Labs: microsoft.com/handsonlabs
- 139. How can I try SQL Server 2019? For Windows, Linux, and containers: aka.ms/trysqlserver2019
- 140. How can I try Big Data Clusters? SQL Server 2019 Early Adoption Program: aka.ms/eapsignup
- 142. Thank you very much for your attention. Vielen Dank für Eure Aufmerksamkeit.