Data Science
0 likes•949 views

The document discusses various aspects of data science, including fault tolerance, scalability, and high availability in systems design. It highlights the importance of distributed computing frameworks like MapReduce and Spark for processing large datasets, and it covers applications in machine learning and recommendation systems at organizations like LinkedIn. Additionally, it touches on ongoing projects within a data science team that focus on scalable analytics and computational advertising.








































![SQL
Queries
SELECT [GROUP_BY_COLUMN], COUNT(*)
FROM lineitem GROUP BY [GROUP_BY_COLUMN]
SELECT * from lineitem l join supplier s
ON l.L_SUPPKEY = s.S_SUPPKEY
WHERE SOME_UDF(s.S_ADDRESS)](https://image.slidesharecdn.com/argelatalk-131028131446-phpapp02/85/Data-Science-43-320.jpg)


![Machine
Learning
def logRegress(points: RDD[Point]): Vector {
var w = Vector(D, _ => 2 * rand.nextDouble - 1)
for (i <- 1 to ITERATIONS) {
val gradient = points.map
{
p => val denom = 1 + exp(-p.y * (w dot p.x)) (1 / denom - 1) * p.y * p.x
}.reduce(_ + _)
w -= gradient
}
w
}
val users = sql2rdd("SELECT * FROM user u JOIN comment c ON c.uid=u.uid")
val features = users.mapRows { row =>
new Vector(extractFeature1(row.getInt("age")), extractFeature2(row.getStr("country")),
...)}
val trainedVector = logRegress(features.cache())](https://image.slidesharecdn.com/argelatalk-131028131446-phpapp02/85/Data-Science-46-320.jpg)










Data Science
- 1. Data Science Dr. Ahmet Bulut [email protected] Oct 4 / 2013, İstanbul
- 2. Available, Fault-‐Tolerant, and Scalable • High Availability (HA): service availability, can we incur no down9me? • Fault Tolerance: tolerate failures, and recover from failures, e.g, so?ware, hardware, and other. • Scalability: going from 1 to 1,000,000,000,000 comfortably.
- 5. 1,000 Users Website Load Balancer App Server 1 App Server 2 DB
- 6. 1,000 Users Website Load Balancer App Server 1 Hardware Failure App Server 2 DB 1
- 7. 2 1,000 Users Website Load Balancer App Server 1 App Server 2 New Hardware DB 45 mins
- 8. 1,000,000 Users Website Load Balancer 1 App Server 1 Master DB Load Balancer 2 App Server 2 Copy App Server N Slave DB
- 9. 1,000,000 Users Website Load Balancer 1 App Server 1 Hardware Failure Ana DB Load Balancer 2 App Server 2 Txn Log File Ship 1 App Server N Slave DB
- 10. 1,000,000 Users Website Load Balancer 1 App Server 1 Load Balancer 2 App Server 2 2 Mins 2 App Server N Promo9on Master DB
- 11. 1,000,000 Users Website Load Balancer 1 App Server 1 Slave DB Load Balancer 2 App Server 2 Copy Backup normal 3 App Server N Master DB 10 mins
- 12. 2 mins? %99.99 = 4.32 mins of down9me in a month! %99.999 = 5.26 mins of down9me in a year!
- 13. 100,000,000 Users RAM 1 RAM 2 RAM 3 RAM ... RAM N-1 Big DB Server RAM N Clustered Cache
- 15. 100,000,000 Users RAM 1 0 mins RAM 2 RAM 3 RAM ... RAM N-1 RAM N Clustered Cache So?ware Upgrade
- 16. Clustered Cache
- 17. Clustered Cache
- 18. Clustered Cache
- 20. Distributed File System My Precious!!!
- 22. Army of machines logging
- 23. A simple sum over the incoming web requests... •Query: Find the most issued web request! •How would you compute?
- 24. What about recommending items? •Collabora9ve Filtering. •Easy, hard, XXL-‐hard?
- 25. Extract Transform and Load (ETL) App Server 1 App Server 2 DB
- 26. Extract Transform and Load (ETL) App Server 1099 App Server 77 App Server 657 App Server 45 App Server 1 App Server 2 DB
- 27. Working with data small | big | extra big •Business Opera9ons: DBMS. •Business Analy9cs: Data Warehouse. •I want interac9vity... I get Data Cubes! •I want the most recent news... •How recent, how o?en? •Real 9me? •Near real 9me?
- 28. Sooo? •Things are looking good except that we have: •DONT-‐WANT-‐SO-‐MANY database objects. •Database objects such as •tables, •indices, •views, •logs.
- 29. Ship it! •Tradi9onal approach has been to ship data to where the queries will be issued. •The new world order demands us to ship “compute logic” to where data is.
- 30. Ship the compute-‐logic App Server 77 App Server 77 App Server 77 App Server 77 App Server 77 App Server 77
- 32. What does M/R give me? •Fine-‐grained fault tolerance. •Fine-‐grained determinis9c task model. •Mul9-‐tenancy. •Elas9city.
- 33. M/R based plajorms •Hadoop. •Hive, Pig. •Spark, Shark. •... (many others).
- 35. Spark Parallel Operations Resilient Distributed Datasets
- 36. Resilient Distributed Dataset (RDD) •Read-‐only collec9on of objects par99oned across a set of machines that can be re-‐built if a par99on is lost. •RDDs can always be re-‐constructed in the face of node failures. Parallel Operations Resilient Distributed Datasets
- 37. Resilient Distributed Dataset (RDD) •RDDs can be constructed by: •From a file in DFS, e.g., Hadoop-‐DFS (HDFS). •Slicing a collec9on (an array) into mul9ple pieces through parallelizaAon. • Transforming an exis9ng RDD. An RDD with elements of type A being mapped to an RDD with elements of type B. •Persis9ng an exis9ng RDD through cache and save opera9ons.
- 38. Parallel Opera9ons •reduce: combining data elements using an associa9ve func9on to produce a result at the driver. •collect: sends all elements of the dataset to the driver. •foreach: pass each data element through a UDF. Parallel Operations Resilient Distributed Datasets
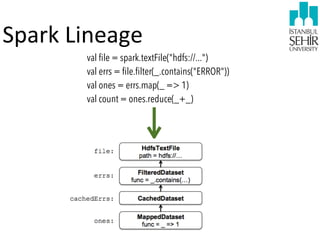
- 39. Spark •Let’s count the lines containing errors in a large log file stored in HDFS: val file = spark.textFile("hdfs://...") val errs = file.filter(_.contains("ERROR")) val ones = errs.map(_ => 1) val count = ones.reduce(_+_)
- 40. Spark Lineage val file = spark.textFile("hdfs://...") val errs = file.filter(_.contains("ERROR")) val ones = errs.map(_ => 1) val count = ones.reduce(_+_)
- 43. SQL Queries SELECT [GROUP_BY_COLUMN], COUNT(*) FROM lineitem GROUP BY [GROUP_BY_COLUMN] SELECT * from lineitem l join supplier s ON l.L_SUPPKEY = s.S_SUPPKEY WHERE SOME_UDF(s.S_ADDRESS)
- 44. SQL Queries •Data Size: 2.1 TB Data •Selec9vity: 2.5 million of dis9nct groups! Time: 2.5 mins
- 45. Machine Learning •LogisHc Regression: Search for a hyperplane w that best separates two sets of points (e.g., spammers and non-‐ spammers). •The algorithm applies gradient descent op9miza9on by star9ng with a randomized vector w. •The algorithm updates w itera9vely by moving along gradients towards the op9mal w’’.
- 46. Machine Learning def logRegress(points: RDD[Point]): Vector { var w = Vector(D, _ => 2 * rand.nextDouble - 1) for (i <- 1 to ITERATIONS) { val gradient = points.map { p => val denom = 1 + exp(-p.y * (w dot p.x)) (1 / denom - 1) * p.y * p.x }.reduce(_ + _) w -= gradient } w } val users = sql2rdd("SELECT * FROM user u JOIN comment c ON c.uid=u.uid") val features = users.mapRows { row => new Vector(extractFeature1(row.getInt("age")), extractFeature2(row.getStr("country")), ...)} val trainedVector = logRegress(features.cache())
- 47. Batch and/or Real-‐Hme Data Processing
- 48. History
- 49. LinkedIn Recommenda9ons •Core matching algorithm uses Lucene (customized). •Hadoop is used for a variety of needs: •Compu9ng collabora9ve filtering features, •Building Lucene indices offline, •Doing quality analysis of recommenda9on. •Lucene does not provide fast real-‐9me indexing. •To keep indices up-‐to date, a real-‐9me indexing library on top of Lucene called Zoie is used.
- 50. LinkedIn Recommenda9ons •Facets are provided to members for drilling down and exploring recommenda9on results. •Face9ng Search library is called Bobo. •For storing features and for caching recommenda9on results, a key-‐value store Voldemort is used. •For analyzing tracking and repor9ng data, a distributed messaging system called Ka3a is used.
- 51. LinkedIn Recommenda9ons •Bobo, Zoie, Voldemort and Kara are developed at LinkedIn and are open sourced. •Kara is an apache incubator project. •Historically, they used R for model training. Now experimen9ng with Mahout for model training. •All the above technologies, combined with great engineers powers LinkedIn’s Recommenda9on plajorm.
- 52. Live and Batch Affair •Using Hadoop: 1. Take a snapshot of data (member profiles) in produc9on. 2. Move it to HDFS. 3. Grandfather members with <ADDED-‐VALUE> in a mawer of hours in the cemetery (Hadoop). 4. Copy this data back online for live servers (ResurrecHon).
- 53. Who we are? •We are Data Scien9sts.
- 54. Our Culture •Our work culture relies heavily on Cloud Compu9ng. •Cloud Compu9ng is a perspec9ve for us, not a technology!
- 55. What we do? •Distributed Data Mining. •Computa9onal Adver9sing. •Natural Language Processing. •Scalable Data Analy9cs. •Data Visualiza9on. •Probabilis9c Inference.
- 56. Ongoing projects •Data Science Team: 3 Faculty; 1 Doctoral, 6 Masters, and 6 Undergraduate Students. •Vista Team: Me, 2 Masters & 4 Undergraduate Students. •Türk Telekom funded project (T2C2): Scalable Analy9cs. •Tübitak 1001 funded project: Computa9onal Adver9sing. •Tübitak 1005 (submi7ed): Computa9onal Adver9sing, NLP. •Tübitak 1003 (in prepera:on): Online Learning.