






























































































![Instacart_Presentation[1]](https://cdn.slidesharecdn.com/ss_thumbnails/d49bb9f3-ce45-452e-a8c2-b91747921356-150620044625-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)

Ad
More Related Content
What's hot (20)
Viewers also liked (10)








Ad
Similar to Data Science @ Instacart (20)



















Ad
Recently uploaded (19)



















Data Science @ Instacart
- 1. Data Science @ Instacart Sharath Rao Data Scientist / Manager Search and Discovery Collaborators: Angadh Singh and Shishir Prasad
- 2. v The Instacart Value Proposition Groceries from stores you love delivered to your doorstep in as little as an hour + + + =
- 3. v Customer Experience Select a Store Shop for Groceries Checkout Select Delivery Time Delivered to Doorstep
- 4. v Shopper Experience Accept Order Find the Groceries Out for Delivery Delivered to Doorstep Scan Barcode
- 5. v Four Sided Marketplace Customers Shoppers Products (Advertisers) Search Advertising Shopping Delivery Customer Service Inventory Picking Loyalty Stores (Retailers)
- 6. v Two topics today A Recommendation System for Discovery Using Data Science for out of stock mitigation
- 7. v Online grocery vs Traditional e-commerce Week 3Week 2 Online Grocery Week 1 Traditional e-commerce
- 8. v Grocery Shopping in “Low Dimensional Space” Search Restock Explore + + =
- 9. v Why personalization at Instacart Your storeEverybody’s store
- 10. v Repeat purchases increase LTV of recommendations $5.49 $549 Today A year later 1 +….+ 100 $549 $549
- 11. vDifferent recommendation systems address different needs
- 12. v Personalized Top N recommendations Promote broad-based discovery in a dynamic catalog Including from stores customers may have never shopped
- 13. v Run out of X? Rank products by repurchase probability
- 14. v Personalized recommendations of new products when customers seek out what is new out there Also addresses product cold start problems
- 15. v Replacement Product Recommendations Mitigate adverse impact of last-minute out of stocks
- 16. v “Frequently bought with” Recommendations Not necessarily consumed together Help customers shop for complementary products and try alternatives Probably consumed together
- 17. vPersonalized Top N Recommendations
- 18. v Learning from feedback Traditionally collaborative filtering used explicit feedback to predict ratings There may still bias in whether the user chooses to rate Explicit Feedback Implicit Feedback
- 19. v Learning from Explicit Feedback • Explicit feedback may be more reliable but there is much less of it • Less reliable if users rate based on aspirations instead of true preferences vs
- 20. v Implicit Feedback - trade-off quality and quantity Strengthofevidence Number of Events
- 21. v Architecture Event Data Score and Select Top N (Spark/EMR) User/Product Factors Event Data Run-time ranking for diversity Candidate Selection ALS (Spark/EMR) Generate User-Product Matrix
- 22. v A Matrix Factorization Formulation for Implicit Feedback N Products MUsers 1 - - 9 - - - 3 20 User Product Matrix R; (M x N) 1 0 0 1 0 0 0 1 1binary preferences Preference Matrix R; (M x N) “Collaborative Filtering for Implicit Feedback” - Hu et. al
- 23. v A Matrix Factorization Formulation for Implicit Feedback ~ Y XT Product Factors (k x N) User Factors (M x k) 1 0 0 1 0 0 0 1 1 x Preference Matrix R; (M x N)
- 24. v Matrix Factorization from Implicit Feedback - The Intuition #Purchases Preference p Confidence c 0 0 Low 1 1 Low >>1 1 High • Confidence increases linearly with purchases r • c = 1 + alpha * r • alpha controls the marginal rate of learning from user purchases • Key questions • How should the unobserved events be treated • How should one trade-off observed and the unobserved
- 25. v Regularized Weighted Squared Loss Confidence User Factors Matrix Product Factors Matrix Preference Matrix Regularization Solve using Alternating Least Squares
- 26. v Architecture Generate User-Product Matrix ALS (Spark/EMR) Score and Select Top N (Spark/EMR) User/Product Factors Run-time ranking for diversity Candidate Selection Event Data Event Data
- 27. v Spark ALS Hyper-parameter Tuning • rank k - diminishing returns after 150 • alpha - controls rate of learning from observed events • iterations - ALS tends to converge within 5, seldom more than 10 • lambda - regularization parameter
- 28. v Architecture Generate User-Product Matrix ALS Matrix Factorization (Spark/EMR) Candidate Selection Score and Select Top N (Spark/EMR) User/Product Factors Run-time ranking for diversity Event Data Event Data
- 29. v Scoring user and products With millions of products and users, scoring every (user, product) pair is prohibitive Two goals in selecting products to score • Long tail which have not been discovered • Products that have an a priori high purchase rate (popular) ~
- 30. v Trade-off popularity and discovery in the tail We start with simple stratified sampling For each user, score N products Sample h products from Head Sample t products from tail N ~ 10000 h ~ 3000 t ~7000
- 31. v Tuning Spark For ALS Understanding Spark execution model and its implementation of ALS helps • Training is communication heavy1 , set partitions <= #CPU cores • Scoring is memory intensive • Broad guidelines2 • Limit executor memory to 64GB • 5 cores per executor • Set executors based on data size 1 - http://apache-spark-user-list.1001560.n3.nabble.com/Error-No-space-left-on-device-tp9887p9896.html 2 - http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-1/
- 32. v A/B Test Setup Generate User-Product Matrix ALS (Spark/EMR) Score and Select Top N (Spark/EMR) User/Product Factors Run-time diversity ranking Candidate Selection Event Data Event Data Weekly for past N months data Weekly for users with recent activity
- 33. v A/B Test Results • Statistically significant increases • Items per order • GMV per order • Total product sales spread over more categories
- 34. v Ok, we have a recommendation system Where do we go from here?
- 35. v What else do you do with user and product factors? Score (user, product) pair on demand Get Top N similar users Get Top N similar product As features in other models
- 36. v Products similar to “Haigs Spicy Hummus" More “Spicy Hummus” Spicy Salsas Generated using Approximate Nearest Neighbor (“annoy” from Spotify)
- 37. v What next • Make recommendations more contextual • Explain recommendations (“Because you did X”)
- 38. vMitigating the effect of out of stocks
- 39. v • what are out of stocks • why do they happen • how data science helps mitigate effects
- 40. v Out of stocks - Customer Context “Deliver Ice Cream from Whole Foods Market SOMA at 8 pm tomorrow”
- 42. v Traditional E-commerce • Manage inventory in warehouses optimized for quick fulfillment • Customers only specify the “What” • Disallow users from ordering out of stock products • Set expectations • “3 day shipping” but will ship in 10 business days
- 43. v On-demand delivery from local retailers • Shoppers navigate a complex environment where products • may have run out • may be misplaced • may be damaged • Customers specify “What”, “When” and “Where from” • Improvise under uncertainty
- 44. v Customers Advertisers (brands) Stores (Retailers) lose revenue and trust of customers Everybody loses when out of stocks happen • don’t get exactly what they want • must contemplate and/or communicate replacements lose revenue and trust of customers • waste time searching for items that aren’t in store • context switch to searching and communicating replacements Shoppers
- 45. v Out of stock rate - an illustration
- 46. v
- 47. v A probable solution Do not show or allow customers to order items that are currently out of stock
- 48. v A probable (but terrible) solution • Customers really know these stores • “Missing” items is seen as a sign of an unreliable catalog/service • May have been out of stock this morning but could be available when the order is fulfilled • Sets up negative spirals “I was there over the weekend. Please check behind the cheeses aisle” “Are you telling me they don’t carry strawberries?”
- 49. v Solution that works reasonably well • Shoppers can see Instacart recommended replacements while shopping in the store • Customers may also specify or choose from recommended replacements • Relatively more flexibility with groceries • Some services offer to cancel the order if an item isn’t available
- 50. v Instacart Recommended Replacements Flavor PackingSizeBrand Price • Several product attributes matter • Context matters, might benefit from personalization • Must scale to millions of products • Not always symmetric • May be ok to replace X with gluten free X but not the other way around Diet Info
- 51. v • Shoppers are trained to pick replacements • But shoppers can benefit from algorithmic suggestions • Many unfamiliar products in a vast catalog • Validation for common products • Finding replacements fast improves operational efficiency Replacement Recommendations for Shoppers
- 52. v • Customers can specify replacements while placing the order • Can choose to communicate with the shopper in store to verify Replacement Recommendations for Customers
- 53. v What could we do if could predict item availability? Customer location Nearest store Farther, but better availability Controlling for retailer and quality, customer is indifferent to physical location
- 54. v The Item Availability Prediction Probability( Item in store | time, context) What is probability that an item will be at the store when the shopper shows up to look for it?
- 55. v Item Availability as a Classification Problem TIMESTAMP, ITEM IDENTIFIED, IN STORE? • Millions of examples from historical data • Feature Engineering • historical availability at multiple resolutions • Eg: time since last “not found” event • Item attributes • Eg: perishables restocked differently than personal care • Temporal Features
- 56. v Training and Scoring Feature Extraction XGBoost Training Scoring Feature Extraction Event Data Event Data Model Store Weekly with over 2 months of training data Cache availability scores Score tens of millions of items every hour
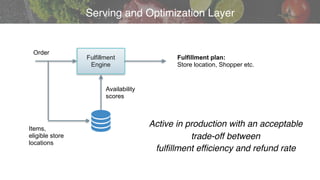
- 57. v Serving and Optimization Layer Fulfillment Engine Order Fulfillment plan: Store location, Shopper etc. Items, eligible store locations Availability scores Active in production with an acceptable trade-off between fulfillment efficiency and refund rate
- 58. v Whats next • Leverage model predictions for other features/data products • Avoid negative feedback loops! • Biased training data • only have access to what is ordered through Instacart • Tighter integrations with retailer data • Scaling: continue to score a growing catalog at tight SLAs
- 60. v Appendix
- 61. v Offline evaluation • Ideally we want to evaluate user response to recommendations • But we will only know this from an live A/B test • Recall based metrics are an offline proxy (albeit not the best) • Recall: “Fraction of purchased products covered among Top N recommendations” • We only use this for hyper parameter tuning
- 62. v Ensembles Use different types of evidence and/or product metadata to easily create ensembles User x Products Purchased User x Products Viewed User x Brands Purchased Model or Linear Combination …
- 63. v What better promotes broad-based discovery vs
- 64. v Online ranking for diversity “Diversity within sessions, Novelty across sessions” “Establish trust in a fresh and comprehensive catalog” “Less is more” Cached list of ~1000 products per user Final list of <100 products promote diversity
- 65. v Diversity Top K products - ranked by score Rank product categories by their median product score > > >
- 66. v Weighted sampling for diversity Sample category in proportion to score Within category, sample in proportion to product score
- 67. v Architecture Generate User-Product Matrix ALS (Spark/EMR) Score and Select Top N (Spark/EMR) User/Product Factors Run-time diversity ranking Candidate Selection Event Data Event Data
- 68. v Out of stocks happen due to uncertainty in several places Order fulfillment in (distant) future Cannot hold inventory Real-time inventory tracking across thousands of locations isn’t perfect (yet) Customer might reschedule delivery