Spark + Cassandra = Real Time Analytics on Operational Data
Download as PPTX, PDF17 likes10,048 views

This document discusses using Apache Spark and Cassandra together for real-time analytics on transactional data. It provides an overview of Cassandra and how it can be used for operational applications like recommendations, fraud detection, and messaging. It then discusses how the Spark Cassandra Connector allows reading and writing Cassandra data from Spark, enabling real-time analytics on streaming and batch data using Spark SQL, MLlib, and Spark Streaming. It also covers some DataStax Enterprise features for high availability and integration of Spark and Cassandra.

















![DSE Spark Interactive Shell
$ dse spark
...
Spark context available as sc.
HiveSQLContext available as hc.
CassandraSQLContext available as csc.
scala> sc.cassandraTable("test", "kv")
res5: com.datastax.spark.connector.rdd.CassandraRDD
[com.datastax.spark.connector.CassandraRow] =
CassandraRDD[2] at RDD at CassandraRDD.scala:48
scala> sc.cassandraTable("test", "kv").collect
res6: Array[com.datastax.spark.connector.CassandraRow] =
Array(CassandraRow{k: 1, v: foo})
cqlsh> select * from
test.kv;
k | v
---+-----
1 | foo
(1 rows)](https://image.slidesharecdn.com/datastaxcassandra-spark-150219162427-conversion-gate02/85/Spark-Cassandra-Real-Time-Analytics-on-Operational-Data-19-320.jpg)


.select("user_name", "message")
.where("user_name = ?", "ewa")
row
representation keyspace table
server side column
and row selection](https://image.slidesharecdn.com/datastaxcassandra-spark-150219162427-conversion-gate02/85/Spark-Cassandra-Real-Time-Analytics-on-Operational-Data-21-320.jpg)

.toArray
//Array(Vehicle(KF334L, Ford Mondeo, Petrol, 2009),
// Vehicle(MT8787, Hyundai x35, Diesel, 2011)
* Mapping rows to Scala Case Classes
* CQL underscore case column mapped to Scala camel case property
* Custom mapping functions (see docs)](https://image.slidesharecdn.com/datastaxcassandra-spark-150219162427-conversion-gate02/85/Spark-Cassandra-Real-Time-Analytics-on-Operational-Data-23-320.jpg)






![Python API
$ dse pyspark
Python 2.7.8 (default, Oct 20 2014, 15:05:19)
[GCC 4.9.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 1.1.0
/_/
Using Python version 2.7.8 (default, Oct 20 2014 15:05:19)
SparkContext available as sc.
>>> sc.cassandraTable("test", "kv").collect()
[Row(k=1, v=u'foo')]](https://image.slidesharecdn.com/datastaxcassandra-spark-150219162427-conversion-gate02/85/Spark-Cassandra-Real-Time-Analytics-on-Operational-Data-30-320.jpg)








Spark + Cassandra = Real Time Analytics on Operational Data
- 1. Analytique temps réel sur des données transactionnelles = Cassandra + Spark 20/02/15 Victor Coustenoble Ingénieur Solutions [email protected] @vizanalytics
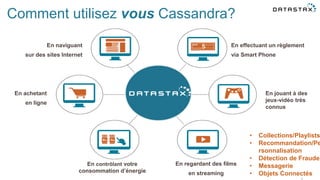
- 3. Comment utilisez vous Cassandra? En contrôlant votre consommation d’énergie En regardant des films en streaming En naviguant sur des sites Internet En achetant en ligne En effectuant un règlement via Smart Phone En jouant à des jeux-vidéo très connus • Collections/Playlists • Recommandation/Pe rsonnalisation • Détection de Fraude • Messagerie • Objets Connectés
- 4. Aperçu Fondé en avril 2010 ~35 500+ Santa Clara, Austin, New York, London, Paris, Sydney 400+ Employés Pourcent Clients 4
- 5. Straightening the road RELATIONAL DATABASES CQL SQL OpsCenter / DevCenter Management tools DSE for search & analytics Integration Security Security Support, consulting & training 30 years ecosystem
- 6. Apache Cassandra™ • Apache Cassandra™ est une base de données NoSQL, Open Source, Distribuée et créée pour les applications en ligne, modernes, critiques et avec des montée en charge massive. • Java , hybride entre Amazon Dynamo et Google BigTable • Sans Maître-Esclave (peer-to-peer), sans Point Unique de Défaillance (No SPOF) • Distribuée avec la possibilité de Data Center • 100% Disponible • Massivement scalable • Montée en charge linéaire • Haute Performance (lecture ET écriture) • Multi Data Center • Simple à Exploiter • Language CQL (comme SQL) • Outils OpsCenter / DevCenter 6 Dynamo BigTable BigTable: http://research.google.com/archive/bigtable-osdi06.pdf Dynamo: http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf Node 1 Node 2 Node 3Node 4 Node 5
- 7. Haute Disponibilité et Cohérence • La défaillance d’un seul noeud ne doit pas entraîner de défaillance du système • Cohérence choisie au niveau du client • Facteur de Réplication (RF) + Niveau de Cohérence (CL) = Succès • Exemple: • RF = 3 • CL = QUORUM (= 51% des replicas) ©2014 DataStax Confidential. Do not distribute without consent. 7 Node 1 1st copy Node 4 Node 5 Node 2 2nd copy Node 3 3rd copy Parallel Write Write CL=QUORUM 5 μs ack 12 μs ack 12 μs ack > 51% de réponses – donc la requête est réussie CL(Read) + CL(Write) > RF => Cohérence Immédiate/Forte
- 8. DataStax Enterprise Cassandra Certifié, Prêt pour l’Entreprise 8 Security Analytics Search Visual Monitoring Management Services In-Memory Dev.IDE& Drivers Professional Services Support& Training Confiance d’utilisation Fonctionnalités d’Entreprise
- 9. DataStax Enterprise - Analytique • Conçu pour faire des analyses sur des données Cassandra • Il y a 4 façons de faire de l’Analytique sur des données Cassandra: 1. Recherche (Solr) 2. Analytique en mode Batch (Hadoop) 3. Analytique en mode Batch avec des outils Externe (Cloudera, Hortonworks) 4. Analytique Temps Réel ©2014 DataStax Confidential. Do not distribute without consent.
- 10. Partenariat ©2014 DataStax Confidential. Do not distribute without consent. 10
- 11. Why Spark on Cassandra? • Analytics on transactional data and operational applications • Data model independent queries • Cross-table operations (JOIN, UNION, etc.) • Complex analytics (e.g. machine learning) • Data transformation, aggregation, etc. • Stream processing • Better performances than Hadoop Map/Reduce
- 12. Real-time Big Data ©2014 DataStax Confidential. Do not distribute without consent. 12 Data Enrichment Batch Processing Machine Learning Pre-computed aggregates Data NO ETL
- 13. Real-Time Big Data Use Cases • Recommendation Engine • Internet of Things • Fraud Detection • Risk Analysis • Buyer Behaviour Analytics • Telematics, Logistics • Business Intelligence • Infrastructure Monitoring • … ©2014 DataStax Confidential. Do not distribute without consent. 13
- 14. Composants Sparks Shark or Spark SQL Structured Spark Streaming Real-time MLlib Machine learning Spark (General execution engine) GraphX Graph Cassandra Compatible
- 16. Cassandra Executor ExecutorSpark Worker (JVM) Cassandra Executor ExecutorSpark Worker (JVM) DSE Spark Integration Architecture Node 1 Node 2 Node 3 Node 4 Cassandra Executor ExecutorSpark Worker (JVM) Cassandra Executor ExecutorSpark Worker (JVM) Spark Master (JVM) App Driver
- 17. Spark Cassandra Connector C* C* C*C* Spark Executor C* Java Driver Spark-Cassandra Connector User Application Cassandra
- 18. Cassandra Spark Driver •Cassandra tables exposed as Spark RDDs •Load data from Cassandra to Spark •Write data from Spark to Cassandra •Object mapper : Mapping of C* tables and rows to Scala objects •Type conversions : All Cassandra types supported and converted to Scala types •Server side data selection •Virtual Nodes support •Scala and Java APIs
- 19. DSE Spark Interactive Shell $ dse spark ... Spark context available as sc. HiveSQLContext available as hc. CassandraSQLContext available as csc. scala> sc.cassandraTable("test", "kv") res5: com.datastax.spark.connector.rdd.CassandraRDD [com.datastax.spark.connector.CassandraRow] = CassandraRDD[2] at RDD at CassandraRDD.scala:48 scala> sc.cassandraTable("test", "kv").collect res6: Array[com.datastax.spark.connector.CassandraRow] = Array(CassandraRow{k: 1, v: foo}) cqlsh> select * from test.kv; k | v ---+----- 1 | foo (1 rows)
- 20. Connecting to Cassandra // Import Cassandra-specific functions on SparkContext and RDD objects import com.datastax.driver.spark._ // Spark connection options val conf = new SparkConf(true) .setMaster("spark://192.168.123.10:7077") .setAppName("cassandra-demo") .set("cassandra.connection.host", "192.168.123.10") // initial contact .set("cassandra.username", "cassandra") .set("cassandra.password", "cassandra") val sc = new SparkContext(conf)
- 21. Reading Data val table = sc .cassandraTable[CassandraRow]("db", "tweets") .select("user_name", "message") .where("user_name = ?", "ewa") row representation keyspace table server side column and row selection
- 22. Writing Data CREATE TABLE test.words(word TEXT PRIMARY KEY, count INT); val collection = sc.parallelize(Seq(("foo", 2), ("bar", 5))) collection.saveToCassandra("test", "words", SomeColumns("word", "count")) cqlsh:test> select * from words; word | count ------+------- bar | 5 foo | 2 (2 rows)
- 23. Mapping Rows to Objects CREATE TABLE test.cars ( id text PRIMARY KEY, model text, fuel_type text, year int ); case class Vehicle( id: String, model: String, fuelType: String, year: Int ) sc.cassandraTable[Vehicle]("test", "cars").toArray //Array(Vehicle(KF334L, Ford Mondeo, Petrol, 2009), // Vehicle(MT8787, Hyundai x35, Diesel, 2011) * Mapping rows to Scala Case Classes * CQL underscore case column mapped to Scala camel case property * Custom mapping functions (see docs)
- 24. Type Mapping CQL Type Scala Type ascii String bigint Long boolean Boolean counter Long decimal BigDecimal, java.math.BigDecimal double Double float Float inet java.net.InetAddress int Int list Vector, List, Iterable, Seq, IndexedSeq, java.util.List map Map, TreeMap, java.util.HashMap set Set, TreeSet, java.util.HashSet text, varchar String timestamp Long, java.util.Date, java.sql.Date, org.joda.time.DateTime timeuuid java.util.UUID uuid java.util.UUID varint BigInt, java.math.BigInteger *nullable values Option
- 25. Shark • SQL query engine on top of Spark • Not part of Apache Spark • Hive compatible (JDBC, UDFs, types, metadata, etc.) • Supports in-memory tables • Available as a part of DataStax Enterprise
- 26. Spark SQL • Spark SQL supports a subset of SQL-92 language • Spark SQL optimized for Spark internals (e.g. RDDs) , better performances than Shark • Support for in-memory computation
- 27. •From Spark command line •Mapping of Cassandra keyspaces and tables •Read and write on Cassandra tables Usage of Spark SQL & HiveQL query import com.datastax.spark.connector._ // Connect to the Spark cluster val conf = new SparkConf(true)... val sc = new SparkContext(conf) // Create Cassandra SQL context val cc = new CassandraSQLContext(sc) // Execute SQL query val rdd = cc.sql("INSERT INTO ks.t1 SELECT c1,c2 FROM ks.t2") // Execute HQL query val rdd = cc.hql("SELECT * FROM keyspace.table JOIN ... WHERE ...")
- 28. Spark Streaming • For real time analytics • Push or pull model • Stream TO and FROM Cassandra • Micro batching (each batch represented as RDD) • Fault tolerant • Data processed in small batches • Exactly-once processing • Unified stream and batch processing framework • Supports Kafka, Flume, ZeroMQ, Kinesis, MQTT producers
- 29. Usage of Spark Streaming • Due to the unifying Spark architecture, portions of batch and streaming development can be reused • Given that Spark Streaming is backed by Cassandra, no need to depend upon solutions like Apache Zookeeper ™ in production import com.datastax.spark.connector.streaming._ // Spark connection options val conf = new SparkConf(true)... // streaming with 1 second batch window val ssc = new StreamingContext(conf, Seconds(1)) // stream input val lines = ssc.socketTextStream(serverIP, serverPort) // count words val wordCounts = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) // stream output wordCounts.saveToCassandra("test", "words") // start processing ssc.start() ssc.awaitTermination()
- 30. Python API $ dse pyspark Python 2.7.8 (default, Oct 20 2014, 15:05:19) [GCC 4.9.1] on linux2 Type "help", "copyright", "credits" or "license" for more information. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /__ / .__/_,_/_/ /_/_ version 1.1.0 /_/ Using Python version 2.7.8 (default, Oct 20 2014 15:05:19) SparkContext available as sc. >>> sc.cassandraTable("test", "kv").collect() [Row(k=1, v=u'foo')]
- 31. DataStax Enterprise + Spark Special Features •Easy setup and config • no need to setup a separate Spark cluster • no need to tweak classpaths or config files •High availability of Spark Master •Enterprise security • Password / Kerberos / LDAP authentication • SSL for all Spark to Cassandra connections •CFS integration (no SPOF distributed file system) •Cassandra access through Spark Python API •Certified and Supported on Cassandra •Shark availability
- 32. DataStax Enterprise - High Availability • All nodes are Spark Workers • By default resilient to Worker failures • First Spark node promoted as Spark Master (state saved in CFS, no SPOF) • Standby Master promoted on failure (New Spark Master reconnects to Workers and the driver app and continues the job)
- 33. Without DataStax Enterprise 33 C* SparkM SparkW C* SparkW C* SparkWC* SparkW C* SparkW
- 34. With DataStax Enterprise 34 C* SparkM SparkW C* SparkW* C* SparkWC* SparkW C* SparkW Master state in C* Spare master for H/A
- 35. Spark Use Cases 35 Load data from various sources Analytics (join, aggregate, transform, …) Sanitize, validate, normalize data Schema migration, Data conversion
- 36. DataStax Enterprise © 2014 DataStax, All Rights Reserved. Company Confidential External Hadoop Distribution Cloudera, Hortonworks OpsCenter Services Hadoop Monitoring Operations Operational Application Real Time Search Real Time Analytics Batch Analytics SGBDR Analytics Transformation s 36 Cassandra Cluster – Nodes Ring – Column Family Storage High Performance – Alway Available – Massive Scalability Advanced Security In-Memory
- 37. How to Spark on Cassandra? DataStax Cassandra Spark driver https://github.com/datastax/cassandra-driver-spark Compatible with •Spark 1.2 •Cassandra 2.0.x and 2.1.x •DataStax Enterprise 4.5 et 4.6 DataStax Enterprise 4.6 = Cassandra 2.0 + Driver + Spark 1.1 Spark 1.2 in next DSE 4.7 version (March)
- 38. Merci Questions ? We power the big data apps that transform business. ©2013 DataStax Confidential. Do not distribute without consent. [email protected] @vizanalytics
Editor's Notes
- #4: Qui nous connait parmi vous. En fait dans votre vie quotienne, vous utilisez la technologie DataStax sans le savoir : ebay pour les recommandations produit, bientot NetFlix pour visonner des films en streaming, un achat par SmartSphone grace à nouveau un service offert par un grande banque mutualiste, un échange de de message instantanée avec un service du plus gros opérateur de téléphonie en France etc… Finallement vous utilisez dans votre vie de tous les jours les différents types d’applications proposées par nos 500 clients et qui s’appuie sur notre technologie de base de données We are growing so fast, and in so many ways, I'm willing to bet you’ve used our technology several times in just the past few days and don’t even realize it. Whether you did some online banking, browsed news sites, did a bit of retail shopping, filled a few prescriptions, or watched movies online -- basically, if you lived your life -- you used the kinds of applications that we power for over 400 customers, including over 20 of the Fortune 100.
- #5: Key Takeaway- Introduce the company, our incredible growth and global presence, that we are in about 25% of the FORTUNE 100, and the fact that many of the online and mobile applications you already use every day are actually built on DataStax. Talk Track- DataStax, the leading distributed database technology, delivers Apache Cassandra to the world’s most innovative companies such as Netflix, Rackspace, Pearson Education and Constant Contact. DataStax is built to be agile, always-on, and predictably scalable to any size. We were founded in April 2010, so we are a little over 4 years old. We are headquartered in Santa Clara, California and have offices in Austin TX, New York, London, England and Sydney Australia. We now have over 330 employees; this number will reach well over 400 by the end of our fiscal year (Jan 31 2015) and double by the end of FY16. Currently 25% of the Fortune 100 use us, and our success has been built on our customers success and today and we have over 500 customers worldwide, in over 40 countries. The logos you see here are ones that you are already using every day. These applications are all built on DataStax and Apache Cassandra. So how have we come so far in such a short time…..?
- #6: En fait la mission de DataStax est de vos libérer de ces incertitudes et vous faciliter la route sur cette nouvelle voie. A cette fin, nous vous offrons un DML DDL appelé CQL très proche du SQL maitrisé par vos équipes, des outils complets d’administration et de monitoring, So, What DataStax is doing is trying to straightened that bend in the road. We are providing things like CQL, and management tools called DevCenter and OpsCenter. DataStax Enterprise provides integration into analytics and search capabilities and we do it all within a secure environment. We also provide consultants and training courses, including free virtual training to help get you up to speed.
- #7: Cassandra is designed to handle big data workloads across multiple data centers with no single point of failure, providing enterprises with continuous availability without compromising performance. It uses aspects of Dynamos partitioning and replication and a log-structured data model similar to Bigtable’s. It takes its distribution algorithm from Dynamo and its data model from Bigtable. Cassandra is a reinvented database which is lightening fast and always on ideal for todays online applications where relational databases like Oracle can’t keep up. This means that in todays world, cassandra stores and processes real time information at fast, predictive performance and built in fault tolerance
- #9: Key Takeaway- DataStax Enterprise delivers the commercial confidence and the additional enterprise functionality that you need to support your online business applications. Talk Track- DataStax takes the latest version of open source Apache Cassandra, certifies and prepares it for bullet-proof enterprise deployment. We deliver commercial confidence in the form of training and support, development tools and drivers and professional implementation services to ensure that you have everything you need to successfully deploy Cassandra on support of your mainstream business applications. We also offer additional functionality such as Management Services, that allow you to automatically manage administration and performance Security and encryption to ensure that your data remains perfectly safe and free from corruption In-Memory option that allows you to deliver online applications with lightening fast response times Analytics that allow you to gain valuable insights into data center performance Search which easily allows you search you database, and Visual Monitoring, our Ops Center product that allows you to easily manage and monitor data center performance from anywhere, and on any device
- #11: Databricks is the company behind Apache Spark.
- #13: Predictive analytics Does this simple architecture look familiar to you? Lambda Nathan Marz
- #15: Shark is hive compatible – you can run the same application on Shark Shark integration is only on DSE, otherwise you have to wait for Spark SQL Separate projects – Spark is totally different project Spark SQL has borrowed from Spark Both promising to be Hive compatible
- #16: Cassandra spark driver will NOT connect to remote DC Different nodes, profile etc..
- #33: Master HA out of the box with DSE A Spark Master controls the workflow, and a Spark Worker launches executors responsible for executing part of the job submitted to the Spark master.
- #36: DUYHAI