Data Structure (Dynamic Array and Linked List)
Download as PPSX, PDF6 likes933 views

The document discusses dynamic arrays and linked lists, explaining their definitions and memory management functions such as allocation and deallocation. It also covers types of linked lists, operations such as insertion and deletion, and procedures for managing linked list nodes. Additionally, it includes examples and algorithms for various linked list operations like front, back, and middle insertions and deletions.




































































Data Structure (Dynamic Array and Linked List)
- 1. Dynamic Array and Linked List Adam M.B.
- 4. Array which can be managed dynamically in memory (its size). To order the place in memory, it uses POINTER. Description
- 5. Declaration Type Pengenal = ↑Simpul Simpul = TipeData Atau NamaVariabel : ↑TipeData
- 6. Example (1) Kamus: Bilangan : ↑integer Nama : ↑string
- 7. Example (2) Kamus: Type Point = ↑Data Data = Record < Nim : integer, Nama : string, Nilai : real > EndRecord DataMhs : point
- 9. Definition • Alloc is statement that can be used to order place in memory while program is running. • Dealloc is statement that can be used to delete place which had been ordered while program is running.
- 10. Ilustration in Memory Alloc(DataMhs) Still Empty DataMhs Nil
- 11. OPERATION
- 12. Case Kamus: Type Point = ↑Data Data = Record < NamaMhs : string, Jurusan : string > EndRecord T1,T2: point
- 14. Copy Pointer (Cont’d) T1.NamaMhs ‘Adam’ T1.Jurusan ‘Teknik Informatika’ T2 T1
- 15. Copy Pointer (Cont’d) T2 T1 T2 T1
- 16. Copy Value T1 T2 T1 T2
- 18. LINKED LIST
- 19. DEFINITION
- 20. Data structure that is prepared sequentially, dynamically, and infinite. Linked list is connected by pointer. Description
- 21. Array VS Linked List ARRAY LINKED LIST Static Dynamic Insert and Delete are finite Insert and Delete are infinite Random Access Sequential Access Delete element is only delete value Delete element is truly delete space
- 22. • Single Linked List • Double Linked List • Circular Linked List Types of Linked List
- 24. Linked list that its node consists of one link/pointer that refers to another node. Ilustration of node: Description Info Field (Info) Connection Field (Next)
- 25. Declaration Kamus: Type NamaPointer = ↑Simpul Simpul = Record < InfoField : TipeData, ConnectionField : NamaPointer > EndRecord NamaVarPointer : NamaPointer
- 26. Example Kamus: Type Point = ↑Simpul Simpul = Record < Info : integer, Next : Point > EndRecord Awal,Akhir : Point
- 27. OPERATION
- 28. • Creation • Insertion • Delete • Traversal • Searching • Sorting • Destroy
- 29. Pointer (awal and akhir) is given nil as their value. Creation awal akhir awal nil akhir nil
- 30. • If list is empty (awal = nil). Front Insertion baru baru 1 baru 1 awal akhir alloc(baru) baru.next nil baru.info 1 awal baru akhir baru
- 31. • If list isn’t empty (awal ≠ nil). For example, there is list that has two nodes: Front Insertion (cont’d) akhirawal 2 3 One node will be inserted in front of list: 1baru alloc(baru) baru.info 1
- 32. New node will be inserted before the node that was refered by awal. Front Insertion (cont’d) baru 1 awal 2 akhir 3 baru↑.next awal
- 33. After new node was inserted, move awal to new node. Front Insertion (cont’d) awal 2 3 baru 1 akhir awal baru
- 34. The last result for front insertion if linked list wasn’t empty: Front Insertion (cont’d) baru 1 awal 2 3 akhir
- 35. Procedure SisipDepanSingle(Input elemen : tipedata, I/O awal, akhir : nama_pointer) {I.S. : data yang akan disisipkan (elemen), pointer penunjuk awal dan pointer penunjuk akhir sudah terdifinisi} {F.S. : menghasilkan satu simpul yang disisipkan di depan pada single linked list} Kamus : baru : nama_pointer Algoritma : alloc(baru) baru↑.info elemen If (awal = nil) Then baru↑.next nil akhir baru Else baru↑.next awal EndIf awal baru EndProcedure
- 36. • If list is empty (awal = nil) the process is same as front insertion if linked list is empty. Back Insertion
- 37. • If list isn’t empty (awal ≠ nil). For example, there is list that has two nodes: Back Insertion (cont’d) awal 3 2 akhir New node that will be inserted: baru 1 alloc(baru) baru.next nil baru.info 1
- 38. New node will be inserted after the node that was refered by akhir. Back Insertion (cont’d) baru 1 akhirawal 3 2 akhir.next baru
- 39. Move akhir to new node. Back Insertion (cont’d) akhir baru akhirawal 3 2 baru 1
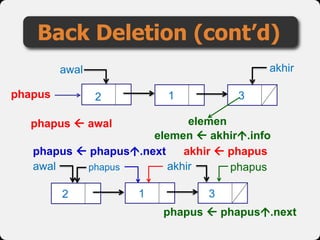
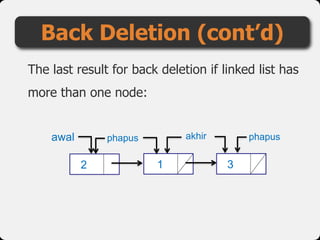
- 40. The last result for back insertion if linked list wasn’t empty: Back Insertion (cont’d) awal 3 2 baru 1 akhir
- 41. Procedure SisipBelakangSingle(Input elemen : tipedata, I/O awal, akhir : nama_pointer) {I.S. : data yang akan disisipkan (elemen), pointer penunjuk awal dan pointer penunjuk akhir sudah terdifinisi} {F.S. : menghasilkan satu simpul yang disisipkan di belakang pada single linked list} Kamus : baru : nama_pointer Algoritma : alloc(baru) baru↑.info elemen baru↑.next nil If (awal = nil) Then awal baru Else akhir↑.next baru EndIf akhir baru EndProcedure
- 42. • If list is empty (awal = nil) the process is same as front insertion if linked list is empty. Middle Insertion
- 43. • If list isn’t empty (awal ≠ nil). Middle Insertion (cont’d) awal 2 54 akhir 3 New node that will be inserted after 4: baru 1 alloc(baru) baru.info 1
- 44. Search node 4 using sequential search and bantu pointer. Middle Insertion (cont’d) bantu baru 1 awal 2 54 akhir 3 bantu
- 45. Connect the connection field from new node to the neighbour node of node that was refered by bantu. Middle Insertion (cont’d) baru.next bantu↑.next baru 1 awal 2 54 akhir 3 bantu
- 46. After new node was connected with node 4 then refer the connection field of node that was refered by bantu to new node. Middle Insertion (cont’d) bantu.next baru bantuawal 2 baru 1 4 akhir 3 5
- 47. The last result for middle insertion if linked list wasn’t empty: Middle Insertion (cont’d) bantu baru 1 2 akhir 5 awal 43
- 48. Procedure SisipTengahSingle(Input elemen : tipedata, I/O awal, akhir : nama_pointer) {I.S. : data yang akan disisipkan (elemen), pointer penunjuk awal dan pointer penunjuk akhir sudah terdifinisi} {F.S. : menghasilkan satu simpul yang disisipkan di tengah pada single linked list} Kamus : baru,bantu : nama_pointer ketemu : boolean datasisip : tipedata Algoritma : If (awal = nil) Then alloc(baru) baru↑.info elemen baru↑.next nil
- 49. awal baru akhir baru Else Input(datasisip) bantu awal ketemu false While (not ketemu and bantu ≠ nil) do If (datasisip = bantu↑.info) Then ketemu true Else bantu bantu↑.next EndIf EndWhile
- 50. If (ketemu) Then alloc(baru) baru↑.info elemen If (bantu = akhir) Then sisip_belakang_single(elemen,awal,akhir) Else baru↑.next bantu↑.next bantu↑.next baru EndIf Else Output(“Data yang akan disisipkan tidak ada”); EndIf EndIf EndProcedure
- 51. • Delete one node in beggining of linked list if linked list has only one node (awal = akhir). Front Deletion awal akhir 1
- 52. If deletion happens in linked list with one node then linked list will be empty. Front Deletion (cont’d) awal akhir phapus elemen 1phapus phapus awal elemen phapus .info dealloc(phapus) awal nil akhir nil 1 awal akhir
- 53. • If linked list has more than one node (awal ≠ akhir). For example, linked list has two nodes. Front Deletion (cont’d) awal 2 3 akhir
- 54. Front Deletion (cont’d) phapus awal 2 3 akhir elemen awal 2 3phapus akhir phapus awal elemen phapus.info awal awal.next dealloc(phapus)
- 55. The last result for front deletion if linked list has more than one node: Front Deletion (cont’d) phapus awal 3 akhir 2
- 56. Procedure HapusDepanSingle(Output elemen : tipedata, I/O awal, akhir : nama_pointer) {I.S. : pointer penunjuk awal dan pointer penunjuk akhir sudah terdifinisi} {F.S. : menghasilkan single linked list yang sudah dihapus satu simpul di depan} Kamus : phapus : nama_pointer Algoritma : phapus awal elemen baru↑.info If (awal = akhir) Then awal nil akhir nil Else awal awal ↑.next EndIf dealloc(phapus) EndProcedure
- 57. • Delete one node in back of linked list if linked list has only one node (awal = akhir). This process is same as front deletion if linked list has only one node. Back Deletion
- 58. • If linked list has more than one node (awal ≠ akhir). For example, linked list has three nodes. Back Deletion (cont’d) awal 1 32 akhir
- 59. Back Deletion (cont’d) phapus awal 1 3 akhir 2 elemen phapus phapusakhirawal 1 32 phapus awal elemen akhir.info phapus phapus.next phapus phapus.next akhir phapus
- 60. Back Deletion (cont’d) awal 1 3 phapus 2 akhir akhir.next nil dealloc(phapus)
- 61. The last result for back deletion if linked list has more than one node: Back Deletion (cont’d) phapus phapusakhir 3 awal 12
- 62. Procedure HapusBelakangSingle(Output elemen : tipedata, I/O awal, akhir : nama_pointer) {I.S. : pointer penunjuk awal dan pointer penunjuk akhir sudah terdifinisi} {F.S. : menghasilkan single linked list yang sudah dihapus satu simpul di belakang} Kamus : phapus : nama_pointer Algoritma : phapus awal elemen baru↑.info If (awal = akhir) Then awal nil akhir nil
- 63. Else while (phapus↑.next ≠ akhir) do phapus phapus↑.next endwhile akhir phapus phapus phapus↑.next akhir↑.next nil EndIf dealloc(phapus) EndProcedure
- 64. • Delete one node in middle of linked list if linked list has only one node (awal = akhir). This process is same as front deletion if linked list has only one node. Middle Deletion
- 65. • If linked list has more than one node (awal ≠ akhir). For example, linked list has four nodes and user want to delete third node. Middle Deletion (cont’d) awal 2 54 akhir 3
- 66. Search the third node start from the first node. If node is found then save the info of this node to the variable elemen. Middle Deletion (cont’d) phapus posisihapus=2awal 2 54 akhir 3 posisihapus=1 posisihapus=3 phapus elemen elemenphapus.info
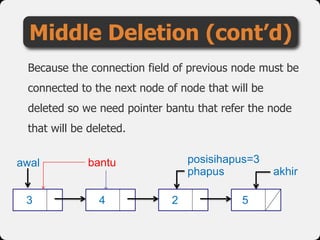
- 67. Because the connection field of previous node must be connected to the next node of node that will be deleted so we need pointer bantu that refer the node that will be deleted. Middle Deletion (cont’d) bantuawal 2 54 phapus akhir 3 posisihapus=3
- 68. Connect the connection field of the node that was referred by pointer bantu to the neighbour node. Delete the node that was referred by pointer phapus. Middle Deletion (cont’d) awal 2 54 phapus akhir 3 posisihapus=3bantu bantu.next phapus.next dealloc(phapus)
- 69. The last result for middle deletion if linked list has more than one node: Middle Deletion (cont’d) 5 akhir 2 phapus posisihapus=1posisihapus=2 posisihapus=3 phapus bantuawal 43 43 5 akhir awal
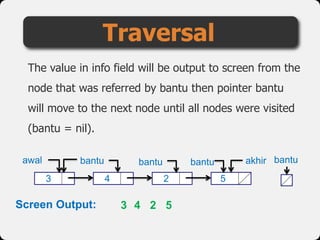
- 70. Operation that visiting all nodes in linked list start from the first node until last node. Traversal awal 2 54 akhir 3 For example, shown the process to output data: • Place one pointer bantu in the first node awa l 2 54 akhir 3 bantu
- 71. The value in info field will be output to screen from the node that was referred by bantu then pointer bantu will move to the next node until all nodes were visited (bantu = nil). Traversal awal 2 54 akhir 3 bantu bantu bantu bantu 3 4 2 5Screen Output:
- 72. Contact Person: Adam Mukharil Bachtiar Informatics Engineering UNIKOM Jalan Dipati Ukur Nomor. 112-114 Bandung 40132 Email: [email protected] Blog: http://adfbipotter.wordpress.com Copyright © Adam Mukharil Bachtiar 2012