



































































































Ad
More Related Content
What's hot (20)
Similar to Data warehousing with Hadoop (20)


















Ad
More from hadooparchbook (20)




















Ad
Recently uploaded (20)




















Data warehousing with Hadoop
- 1. REMINDER Check in on the COLLABORATE mobile app Architectural Considerations for Data Warehousing with Hadoop Prepared by: Mark Grover, Software Engineer Jonathan Seidman, Solutions Architect Cloudera, Inc. github.com/hadooparchitecturebook/h adoop-arch-book/tree/master/ch11- data-warehousing Session ID#: 10251 @mark_grover @jseidman
- 2. About Us ■ Mark ▪ Software Engineer at Cloudera ▪ Committer on Apache Bigtop, PMC member on Apache Sentry (incubating) ▪ Contributor to Apache Hadoop, Spark, Hive, Sqoop, Pig and Flume ■ Jonathan ▪ Senior Solutions Architect/Partner Engineering at Cloudera ▪ Previously, Technical Lead on the big data team at Orbitz Worldwide ▪ Co-founder of the Chicago Hadoop User Group and Chicago Big Data
- 3. About the Book ■ @hadooparchbook ■ hadooparchitecturebook.com ■ github.com/hadooparchitectur ebook ■ slideshare.com/hadooparchbo ok
- 4. Agenda ■ Typical data warehouse architecture. ■ Challenges with the existing data warehouse architecture. ■ How Hadoop complements an existing data warehouse architecture. ■ (Very) Brief intro to Hadoop. ■ Example use case. ■ Walkthrough of example use case implementation.
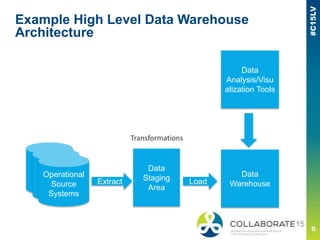
- 6. Example High Level Data Warehouse Architecture Extract Data Staging Area Operational Source Systems Load Data Warehouse Data Analysis/Visu alization Tools Transformations
- 7. Challenges with the Data Warehouse Architecture
- 8. Challenge – ETL/ELT Processing OLTP Enterprise Applications ODS Data Warehouse QueryExtract Transform Load Business Intelligence Transform
- 9. Challenges – ETL/ELT Processing OLTP Enterprise Applications ODS Data Warehouse QueryExtract Transform Load Business Intelligence Transform 1 Slow Data Transformations = Missed ETL SLAs. 2 Slow Queries = Frustrated Business Users. 1 2 1
- 10. Challenges – Data Archiving Data Warehouse Tape Archive ■ Full-fidelity data only kept for a short duration ■ Expensive or sometimes impossible to look at historical raw data
- 11. Challenge – Disparate Data Sources Data Warehouse ■ How do you join data from disparate sources with EDW? Business Intelligence ???
- 12. Challenge – Lack of Agility ■ Responding to changing requirements, mistakes, etc. requires lengthy processes.
- 13. Challenge – Exploratory Analysis in the EDW ■ Difficult for users to do exploratory analysis of data in the data warehouse. Business Users Developers Analysts Data Warehouse
- 14. Complementing the EDW with Hadoop
- 15. Data Warehouse Architecture with Hadoop Extract Hadoop Operational Source Systems EDW BI/Analytics Tools Logs, machine data, etc. Extract Transformation/Analysis Load
- 16. Hadoop ETL/ELT Optimization with Hadoop OLTP Enterprise Applications ODS Business Intelligence Transform Query Store ETL Data Warehouse Query (High $/Byte)
- 17. Active Archiving with Hadoop Data Warehouse Hadoop
- 18. Joining Disparate Data Sources with Hadoop Data Warehouse Business IntelligenceHadoop
- 19. Agile Data Access with Hadoop Schema-on-Write (RDBMS): • Prescriptive Data Modeling: • Create static DB schema • Transform data into RDBMS • Query data in RDBMS format • New columns must be added explicitly before new data can propagate into the system. • Good for Known Unknowns (Repetition) Schema-on-Read (Hadoop): • Descriptive Data Modeling: • Copy data in its native format • Create schema + parser • Query Data in its native format • New data can start flowing any time and will appear retroactively once the schema/parser properly describes it. • Good for Unknown Unknowns (Exploration)
- 20. Exploratory Analysis with Hadoop Hadoop Business Users Developers Analysts Data Warehouse
- 21. A Very Brief Intro to Hadoop
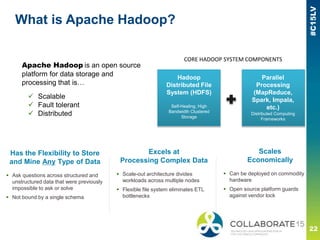
- 22. What is Apache Hadoop? Has the Flexibility to Store and Mine Any Type of Data Ask questions across structured and unstructured data that were previously impossible to ask or solve Not bound by a single schema Excels at Processing Complex Data Scale-out architecture divides workloads across multiple nodes Flexible file system eliminates ETL bottlenecks Scales Economically Can be deployed on commodity hardware Open source platform guards against vendor lock Hadoop Distributed File System (HDFS) Self-Healing, High Bandwidth Clustered Storage Parallel Processing (MapReduce, Spark, Impala, etc.) Distributed Computing Frameworks Apache Hadoop is an open source platform for data storage and processing that is… Scalable Fault tolerant Distributed CORE HADOOP SYSTEM COMPONENTS
- 23. Oracle Big Data Appliance ■ All of the capabilities we’re talking about here are available as part of the Oracle BDA.
- 24. Challenges of Hadoop Implementation
- 25. Challenges of Hadoop Implementation
- 26. Other Challenges – Architectural Considerations Data Sources Ingestion Raw Data Storage (Formats, Schema) Processed Data Storage (Formats, Schema) Processing Data Consumption Orchestration (Scheduling, Managing, Monitoring) Metadata Management
- 27. Hadoop Third Party Ecosystem Data Systems Applications Infrastructure Operational Tools
- 28. Walkthrough of Example Use Case
- 29. Use-case ■ Movielens dataset ■ Users register by entering some demographic information ▪ Users can update demographic information later on ■ Rate movies ▪ Ratings can be updated later on ■ Auxillary information about movies available ▪ e.g. release date, IMDB URL, etc.
- 30. Movielens data set u.user user id | age | gender | occupation | zip code 1|24|M|technician|85711 2|53|F|other|94043 3|23|M|writer|32067 4|24|M|technician|43537 5|33|F|other|15213 6|42|M|executive|98101 7|57|M|administrator|91344
- 31. Movielens data set u.item movie id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation |Children's | Comedy | Crime | Documentary | Drama | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western | 1|Toy Story (1995)|01-Jan- 1995||http://us.imdb.com/M/title- exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0 |0|0|0 2|GoldenEye (1995)|01-Jan- 1995||http://us.imdb.com/M/title- exact?GoldenEye%20(1995)|0|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0|1 |0|0 3|Four Rooms (1995)|01-Jan- 1995||http://us.imdb.com/M/title- exact?Four%20Rooms%20(1995)|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0| 0|1|0|0
- 32. Movielens data set u.data user id | item id | rating | timestamp 196|242|3|881250949 186|302|3|891717742 22|377|1|878887116 244 51|2|880606923 166|346|1|886397596
- 33. OLTP schema
- 34. Movielens data set - OLTP
- 35. Data Modeling
- 36. Data Modeling Considerations ■ We need to consider the following in our architecture: ▪ Storage layer – HDFS? HBase? Etc. ▪ File system schemas – how will we lay out the data? ▪ File formats – what storage formats to use for our data, both raw and processed data? ▪ Data compression formats? ■ Hadoop is not a database, so these considerations will be different from an RDBMS.
- 37. Denormalization ■ Why denormalize? ■ When to do denormalize? ■ How much to denormalize?
- 38. Why Denormalize? ■ Regular joins are expensive in Hadoop ■ When you have 2 data sets, no guarantees that corresponding records will be present on the same ■ Such a guarantee exists when storing such data in a single data set
- 39. When to Denormalize? ■ Well, it’s difficult to say ■ It depends
- 40. Movielens Data Set - Denormalization Denormalize Denormalize
- 41. Data Set in Hadoop
- 42. Tracking Updates (CDC) ■ Can’t update data in-place in HDFS ■ HDFS is append-only filesystem ■ We have to track all updates
- 43. Tracking Updates in Hadoop
- 44. Hadoop File Types ■ Formats designed specifically to store and process data on Hadoop: ▪ File based – SequenceFile ▪ Serialization formats – Thrift, Protocol Buffers, Avro ▪ Columnar formats – RCFile, ORC, Parquet
- 45. Final Schema in Hadoop
- 46. Our Storage Format Recommendation ■ Columnar format (Parquet) for merged/compacted data sets ▪ user, user_rating, movie ■ Row format (Avro) for history/append-only data sets ▪ user_history, user_rating_fact
- 47. Ingestion
- 48. Sources Interceptors Selectors Channels Sinks Flume Agent Ingestion – Apache Flume Twitter, logs, JMS, webserver, Kafka Mask, re-format, validate… DR, critical Memory, file, Kafka HDFS, HBase, Solr
- 49. Ingestion – Apache Kafka Source System Source System Source System Source System Hadoop Security Systems Real-time monitoring Data Warehouse Kafka
- 50. Ingestion – Apache Sqoop ■ Apache project designed to ease import and export of data between Hadoop and external data stores such as an RDBMS. ■ Provides functionality to do bulk imports and exports of data. ■ Leverages MapReduce to transfer data in parallel. Client Sqoop MapReduce Map Map Map Hadoop Run import Collect metadata Generate code, Execute MR job Pull data Write to Hadoop
- 51. Sqoop Import Example – Movie sqoop import --connect jdbc:mysql://mysql_server:3306/movielens --username myuser --password mypass --query 'SELECT movie.*, group_concat(genre.name) FROM movie JOIN movie_genre ON (movie.id = movie_genre.movie_id) JOIN genre ON (movie_genre.genre_id = genre.id) WHERE ${CONDITIONS} GROUP BY movie.id' --split-by movie.id --as-avrodatafile --target-dir /data/movielens/movie
- 52. Data Processing
- 53. Popular Processing Engines ■ MapReduce ▪ Programming paradigm ■ Pig ▪ Workflow language based ■ Hive ▪ Batch SQL-engine ■ Impala ▪ Near real-time concurrent SQL engine ■ Spark ▪ DAG engine
- 54. Final Schema in Hadoop
- 55. Merge Updates hive>INSERT OVERWRITE TABLE user_tmp SELECT user.* FROM user LEFT OUTER JOIN user_upserts ON (user.id = user_upserts.id) WHERE user_upserts.id IS NULL UNION ALL SELECT id, age, occupation, zipcode, TIMESTAMP(last_modified) FROM user_upserts;
- 56. Aggregations user_rating_fact user_rating user_history movie user Merge updates One record/user/movie Merge updates One record/user avg_movie_rating latest_trending_ movies
- 57. Aggregations hive>CREATE TABLE avg_movie_rating AS SELECT movie_id, ROUND(AVG(rating), 1) AS rating FROM user_rating GROUP BY movie_id;
- 58. Export to Data Warehouse
- 59. user_rating_fact user_rating user_history movie user Merge updates One record/user/movie Merge updates One record/user Data Warehouse avg_movie_rating latest_trending_ movies Export
- 60. Sqoop Export sqoop export --connect jdbc:mysql:/mysql_server:3306/movie_dwh --username myuser --password mypass --table avg_movie_rating --export-dir /user/hive/warehouse/avg_movie_rating -m 16 --update-key movie_id --update-mode allowinsert --input-fields-terminated-by '001’ --lines-terminated-by 'n'
- 63. Please complete the session evaluation Thank you! @hadooparchbook You may complete the session evaluation either on paper or online via the mobile app
- 64. This is a slide title that can be up to two lines of text without losing readability ■ This is the first bullet of text ■ This is the second bullet of text at the same level ▪ This is a sub-bullet of text — This is a secondary sub-bullet of text (and should be as far sub- bullets indent) – This tertiary sub-bullet will be seldom used, but available ▪ This is another sub-bullet of text ■ And this is the third bullet of text
- 65. This is a slide title (one or two lines) ■ This is the first bullet of text ▪ This is a sub-bullet of text ■ This is the second bullet of text at the same level ▪ This is a sub-bullet of text — This is a secondary sub- bullet of text – This tertiary sub-bullet that can be use ▪ This is another sub-bullet of text ■ Senior Solutions Architect/Partner Enablement at Cloudera ■ Previously, Technical Lead on the big data team at Orbitz Worldwide
- 66. This is a slide title (one or two lines) ■ This is the first bullet of text ▪ This is a sub-bullet of text ■ This is the second bullet of text at the same level ▪ This is a sub-bullet of text — This is a secondary sub-bullet of text – This tertiary sub-bullet that can be use ▪ This is another sub-bullet of text ■ This is the first bullet of text ■ This is the second bullet of text at the same level ▪ This is a sub-bullet of text ▪ This is a sub-bullet of text — This secondary sub-bullet ▪ This is another sub-bullet of text ■ And this is another bullet of text Subject number one Subject number two
- 67. This is a slide title for a slide with just the title line (e.g., images/diagrams below)
- 69. What is Hadoop? Hadoop is an open-source system designed To store and process petabyte scale data. That’s pretty much what you need to know. Well almost…
- 70. Compression Codecs snappy Well, maybe. Not splittable. X Splittable. Getting better… Very good choice Splittable, but no...
- 71. Our Compression Codec Recommendation ■ Snappy for all data sets (columnar as well as row based)
- 72. File Format Choices Data set Storage format Compression Codec movie Parquet Snappy user_history Avro Snappy user Parquet Snappy user_rating_fact Avro Snappy user_rating Parquet Snappy