
















![Column Stores and Query-biased Workloads
Column store databases are still RDBMSs
Most SQL queries do not require all columns of a table
So partitioning data by columns (vertically) will usually
be better than partitioning by rows (horizontally)
And data compression can be more efficient
Column store databases scale up [somewhat] better
than traditional RDBMSs depending on workload,
queries, etc.
Column store <> column family](https://image.slidesharecdn.com/databaserevolutionexploratorywebcast-120522111732-phpapp02/85/Database-Revolution-Exploratory-Webcast-18-320.jpg)





























Database Revolution - Exploratory Webcast
- 1. Fit For Purpose: The New Database Revolution Mark Madsen & Robin Bloor
- 2. Introduction Significant and revolutionary changes are taking place in database technology In order to investigate and analyze these changes and where they may lead, The Bloor Group has teamed up with Third Nature to launch an Open Research project. This is the first webinar in a series of webinars and research activities that will comprise the project All research will be made available through our web site: Databaserevolution.com
- 3. Sponsors of This Research
- 4. General Webinar Structure What & why History of Database Part 1: How we got to the RDBMS History of Database Part 2: Relational and Post- relational Food For Thought: Issues, Problems, Assumptions, Challenges Current Conclusions: Insofar as we have any
- 5. Change? Why? Increased data volumes Significant hardware changes Database product innovation New workloads, different data structures Established database concepts are being challenged Market Forces can drive change
- 6. Data Volumes: Moore’s Law Cubed Moore’s Law suggests that CPU power increases 10-fold every 6 years (and other technologies have stayed in step to some degree) Large database volumes have grown 1000- fold every 6 years: In 1992, measured in megabytes In 1998 measured in gigabytes In 2004 measured in terabytes In 2010 measured in petabytes Exabytes by 2016?
- 7. Hardware Changes Moore’s Law now proceeds by adding cores rather than by increasing clock speed. Computer grids using commodity servers are now relatively inexpensive Parallelism is now on the rise and will eventually become the normal mode of processing Memory is about 1 million times faster than disk and random reads have become very expensive in respect of latency SSD are augmenting and may eventually replace spinning disk
- 8. Majority of Data becomes Historical Data over time or even all historic when no longer active Data Application Performance 10% 100% Active 70% 90% Static 30% Cost $$$ and PAIN Transactional Data Time Image courtesy: RainStror
- 9. Market Forces A new set of products appear They include some fundamental innovations A few are sufficiently popular to last Fashion and marketing drive greater adoption Products defects begin to be addressed They eventually challenge the dominant products
- 10. Section 1: History Part 1 Pre-relational and Relational What we had in prior technology regimes Where we came from What we traded away and why
- 11. The Dawn of Database Schema defines logical structure of data The schema enables extensive reuse Logical structure vs Physical structure ACID properties Atomicity – transactions must be atomic Consistency – a transaction ensures consistency Isolation – a transaction runs in isolation Durability – a completed transaction causes permanent change to data
- 12. Database Performance Bottlenecks CPU saturation Memory saturation Disk I/O channel saturation Locking Network saturation Parallelism – inefficient load balancing
- 13. The Joys of SQL? SQL is a declarative query language targeted at data organized in two- dimensional tables. It enables set operations on those tables via: Select, Project and Join operations which can be qualified (Order By, etc.) It imposes some limitations on the logical model of data. It can create a barrier between the user and the data....
- 14. The Ordering Of Data “A data set is an unordered collection of unique, non-duplicated items.” Data is naturally ordered by time if by nothing else. Events are ordered by time. Changes to entities are ordered by time Having an inherent physical order to data can save many processing cycles in some areas of application This is particularly the case for time series applications.
- 15. The RDBMS Optimizer The database can know how to access data better and faster than any programmer… It wasn’t true It became true It isn’t always true It only optimizes for persistent data
- 16. Section 2: History Part 2 Relational and Post-relational Where we are today: oldsql, newsql and nosql The finalizing of the distributed web architecture Rediscovery of the past, when we had purpose-built data stores of different types, with a twist. Revisiting of old arguments Challenging old assumptions
- 18. Column Stores and Query-biased Workloads Column store databases are still RDBMSs Most SQL queries do not require all columns of a table So partitioning data by columns (vertically) will usually be better than partitioning by rows (horizontally) And data compression can be more efficient Column store databases scale up [somewhat] better than traditional RDBMSs depending on workload, queries, etc. Column store <> column family
- 19. New Lamps For Old Google, Yahoo!, Facebook and others had data management problems that established products did not cater for: Big Data, unusual data structures, new workloads They had money to invest and some smart engineers They built their own solutions: Big Table, MapReduce, Cassandra, etc. In doing so, they provoked a database revolution In others words, the internet happened and some people noticed.
- 20. A random selection of databases Sybase IQ, ASE EnterpriseDB Algebraix Teradata, Aster Data LucidDB Intersystems Caché Oracle, RAC Vectorwise Streambase Microsoft SQLServer, PDW MonetDB SQLStream IBM DB2s, Netezza Exasol Coral8 Paraccel Illuminate Ingres Kognitio Vertica Postgres EMC/Greenplum InfiniDB Cassandra Oracle Exadata 1010 Data CouchDB SAP HANA SAND Mongo Infobright Endeca Hbase MySQL Xtreme Data Redis MarkLogic IMS RainStor Tokyo Cabinet Hive Scalaris And a few hundred more…
- 21. Section 3: Database Discussion Topics The core post-relational changes in assumptions. Key aspects of the code- database mismatch Reclassifying pre-relational as NoSQL Complex data, emergent structure, types and schemas Cloud and databases, uhoh?
- 22. Changing Assumptions One single scalable piece of reliable hardware You really need a schema all the time A handful of discrete types are all anybody will ever need, and when they need more they can code UDTs and UDFs in C++ SQL is the optimal way to write and retrieve data ACID always applies Data integrity is a key component of a database
- 23. No SQL, New Concepts Maybe SQL is an unacceptable constraint Maybe SQL is unnecessary for some fit-for-purpose databases, or perhaps just unimportant Maybe the impedance mismatch can be avoided Maybe a formal schema is a constraint Maybe ACID properties can be compromised
- 24. The “Impedance Mismatch” The RDBMS stores data organized according to table structures The OO programmer manipulates data organized according to complex object structures, which may have specific methods associated with them. The data does not simply map to the structure it has within the database Consequently a mapping activity is necessary to get and put data Basically: hierarchies, types, result sets, crappy APIs, language bindings, tools
- 25. NoSQL Directions: Technology Types Some NoSQL DBs do not attempt to provide all ACID properties. (Atomicity, Consistency, Isolation, Durability) Some NoSQL DBs deploy a distributed scale-out architecture with data redundancy. XML DBMS using XQuery are NoSQL DBs Some documents stores are NoSQL DBs (OrientDB, Terrastore, etc.) Object databases are NoSQL DBs (Gemstone, Objectivity, ObjectStore, etc.) Key value stores = schema-less stores (Cassandra, MongoDB, Berkeley DB, etc.) Graph DBMS (DEX, OrientDB, etc.) are NoSQL DBs Large data pools (BigTable, Hbase, Mnesia, etc.) are NoSQL DBs
- 26. The Cloud, uh-oh Negative implications for shared-everything databases that have scalability needs There are architectural implications and possible incompatibilities for shared-nothing databases too Not at scale and at scale (concurrency, ingest volumes and frequencies, etc.) are different How does the database permit dynamic provisioning, elasticity (+/-), etc?
- 27. The new database problems for IT …are probably like old problems for people who went through the Unix client-server era. Best of breed, no standards for anything, “polyglot persistence” = silos on steroids, data integration challenges, shifting data movement architectures
- 28. Recognize Tradeoffs Read consistency vs programmatic correction Schema vs a program to interpret each data structure Standard access interface vs an API for each type of store Data integrity enforcement vs programmatic control Query performance for arbitrary queries vs planned access paths Space efficiency vs simplicity / latency Network transfer performance vs simplicity / latency For the primary goals of Horizontal scale Looser coupling Flexibility for developers building and changing applications
- 29. Information Management Through Human History New technology development creates New methods to cope creates New information scale and availability creates…
- 30. Big Data
- 31. Big data? Unstructured data isn’t really unstructured. The problem is that this data is unmodeled.
- 33. Conclusion Wherein all is revealed, or ignorance exposed Best of breed is back baby Workload types and characteristics The importance of understanding workload in order to select technology Pragmatism, babies and bathwater
- 35. Types of workloads Write‐biased: Read‐biased: ▪ OLTP ▪ Query ▪ OLTP, batch ▪ Query, simple retrieval ▪ OLTP, lite ▪ Query, complex ▪ Object persistence ▪ Query‐hierarchical / ▪ Data ingest, batch object / network ▪ Data ingest, real‐time ▪ Analytic Mixed?
- 37. You must understand your workload ‐ throughput and response time requirements aren’t enough. ▪ 100 simple queries accessing month‐to‐date data ▪ 90 simple queries accessing month‐to‐date data and 10 complex queries using two years of history ▪ Hazard calculation for the entire customer master ▪ Performance problems are rarely due to a single factor.
- 38. Six Key Query Workload Elements These characteristics help determine suitability of technologies to improve query performance. 1. Retrieval – how much data comes back? 2. Selectivity – how much data is filtered? 3. Repetition – how often for the same query? 4. Concurrency – how many queries at once? 5. Data volume – how much data is being queried? 6. Query complexity – how many joins, aggregations, columns, filters, subselects, etc.? 7. Computational complexity – how much computation is performed over the data?
- 39. Characteristics of BI workloads Workload Selectivity Retrieval Repetition Complexity Reporting / BI Moderate Low Moderate Moderate Dashboards / Moderate Low High Low scorecards Ad‐hoc query and Low to Moderate Low Low to analysis high to low moderate Analytics (batch) Low High Low to High Low* Analytics (inline) High Low High Low* Operational / High Low High Low embedded BI * Low for retrieving the data, high if doing analytics in SQL
- 40. Choosing Hardware Architectures Compute and data sizes are key requirements PF MR and related Computations TF Shared nothing GF Shared everything PC or shared disk MF <10s GB 100s GB 1s TB 10s TB 100sTB PB Data volume 40
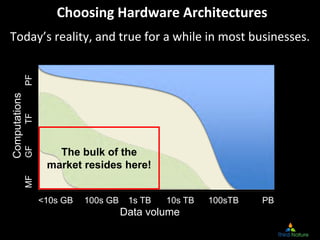
- 41. Choosing Hardware Architectures Today’s reality, and true for a while in most businesses. PF Computations TF GF The bulk of the market resides here! MF <10s GB 100s GB 1s TB 10s TB 100sTB PB Data volume 41
- 42. Choosing Hardware Architectures Today’s reality, and true for a while in most businesses. PF …but analytics Computations pushes many things TF into the MPP zone. GF The bulk of the market resides here! MF <10s GB 100s GB 1s TB 10s TB 100sTB PB Data volume 42
- 43. Evaluating DB Technology 1. Define the key problems: response time, throughput, scalability? 2. Examine the workloads and their requirements 3. Match those to suitable technologies 4. Look for vendors using those technologies 5. Evaluate on real data with real workloads Slide 43 Copyright Third Nature, Inc.
- 45. Back-Up Slides
- 46. NoSQL Directions Some NDBMS do not attempt to provide all ACID properties. (Atomicity, Consistency, Isolation, Durability) Some NDBMS deploy a distributed scale-out architecture with data redundancy. XML DBMS using XQuery are NDBMS. Some documents stores are NDBMS (OrientDB, Terrastore, etc.) Object databases are NDBMS (Gemstone, Objectivity, ObjectStore, etc.) Key value stores = schema-less stores (Cassandra, MongoDB, Berkeley DB, etc.) Graph DBMS (DEX, OrientDB, etc.) are NDMBS Large data pools (BigTable, Hbase, Mnesia, etc.) are NDBMS
- 47. The SQL Barrier SQL has: DDL (for data definition) DML (for Select, Project and Join) But it has no MML (Math) or TML (Time) Usually result sets are brought to the client for further analytical manipulation, but this creates problems Alternatively doing all analytical manipulation in the database creates problems
- 48. Discussion Topics If not covered in history through today: the core post-relational change in assumptions nosql core drivers, persistence in cloud, finalizing of web arch, SOAizing a NoSQL classification list (types and projects/products) key aspects of the OR mismatch complex data and emergent structure database technology types a giant list of databases cloud and databases, uhoh?