Dbms relational model
Download as PPT, PDF8 likes12,752 views

“A DBMS that manages data as collection of tables in which all data relationships are represented by common values in related tables.”





















































Ad
More Related Content
What's hot (20)
Viewers also liked (13)











Ad
Similar to Dbms relational model (20)



















Ad
More from Chirag vasava (6)






Recently uploaded (20)




















Dbms relational model
- 1. Database Management System (2130703) Topic:- Relational Model Prepared by- Vasava Aarti G Roll no_6140 (I.T departmet) 1
- 2. Relational Model Object Relational Model Object Based data Model Brief History of the Relational Model 2
- 3. “A DBMS that manages data as collection of tables in which all data relationships are represented by common values in related tables.” “A DBMS that follows all the twelve rules of CODD is called RDBMS” 3
- 4. 4 Relational Database definition All information must be represented explicitlyAll information must be represented explicitly in one and only one way: as values in tables andin one and only one way: as values in tables and each & every datum in the database must beeach & every datum in the database must be accessible by specifying a table name, a columnaccessible by specifying a table name, a column name, and a primary key.name, and a primary key.
- 5. 5 Data about various entities and their relationships are stored in a series of logical tables (also known as relations). A relation is a two-dimensional table with certain imposed restrictions: 1. Each Row is unique: No duplicate row 2. Entries in any column have the same domain. 3. Each column has a unique name 4. Order of the columns or rows is irrelevant 5. Each entry in the table is single valued: No group item, repeating group, or array is allowed. PRINCIPLES OF RELATIONAL MODELPRINCIPLES OF RELATIONAL MODEL Note: A domain is the set of all possible values an attribute may assume. Example: Domain of Major= (Acct, Mktg, Mgmt, ISOM, Fina)
- 6. Relational database: a set of relations. Relation: made up of 2 parts: – Schema : specifies name of relation, plus name and type of each column. • E.g. Students(sid: string, name: string, login: string, age: integer, gpa: real) – Instance : a table, with rows and columns. •#rows = cardinality •#fields = degree / arity • Can think of a relation as a set of rows or tuples. – i.e., all rows are distinct 6
- 7. The Relational Model developed by Dr. E. F. Codd at IBM in the late 1960s The model built on mathematical concepts, which expounded in the famous work called "A Relational Model of Data for Large Shared Databanks". At the core of the relational model is the concept of a table (also called a relation) in which all data is stored. Records (horizontal rows also known as tuples) & Fields (vertical columns also known as attributes). It is important to note that how or where the tables of data are stored makes no difference. Table can be identified by a unique name. This is quite a bit different from the Hierarchical & Network models in which the user had to have an understanding of how the data was structured within the database in order to retrieve, insert, update, or delete records from the database. 7
- 8. Advantages: The data access methodology in relational model is quite different from and better than the earlier database models . Another benefit of the relational system is that it provides extremely useful tools for database administration. Meta-data (data about the table and field names which form the database structure, access rights to the database, integrity and data validation rules etc). Thus everything within the relational model can be stored in tables. This means that many relational systems can use operations recursively in order to provide information about the database. 8
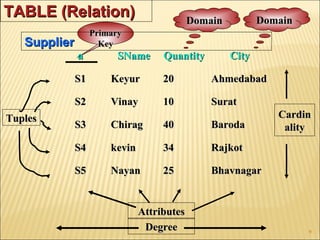
- 9. 9 TABLE (Relation)TABLE (Relation) DegreeDegree AttributesAttributes CardinCardin alityality PrimaryPrimary KeyKey TuplesTuples SupplierSupplier DomainDomainDomainDomain aa SNameSName QuantityQuantity CityCity S1S1 KeyurKeyur 2020 AhmedabadAhmedabad S2S2 VinayVinay 1010 SuratSurat S3S3 ChiragChirag 4040 BarodaBaroda S4S4 kevinkevin 3434 RajkotRajkot S5S5 NayanNayan 2525 BhavnagarBhavnagar
- 10. 10 Member of a relation type (set / table).Member of a relation type (set / table). Tuples:Tuples: Relation / Table Degree:Relation / Table Degree: Attribute Value Set:Attribute Value Set: Attribute Domain:Attribute Domain: Attribute Name:Attribute Name: Attribute (field):Attribute (field): All attribute names must be unique within aAll attribute names must be unique within a table / relation.table / relation. A set of all possible values that can be attain byA set of all possible values that can be attain by an attribute.an attribute. Values currently contained in an attribute.Values currently contained in an attribute. Number of attributes in a relation / table.Number of attributes in a relation / table. Rows in a table / relation.Rows in a table / relation. Cardinality:Cardinality: Number of tuples in a relation / table.Number of tuples in a relation / table.
- 11. 11 sid Name Login age GPA 53666 Jones Jones@ca 18 3.4 53444 smith Smith@ecs 18 3.2 53777 Blake Blake@aa 19 3.8 • Cardinality = 3, arity = 5 , all rows distinct • Do all values in each column of a relation instance have to be distinct? Student(studno,name,address) Course(courseno,lecturer) Student(123,Bloggs,Woolton) (321,Jones,Owens) Schema Instance
- 12. 12 Database SchemaDatabase Schema The description of the database is calledThe description of the database is called database schema. A database schema isdatabase schema. A database schema is describe during database design and notdescribe during database design and not expected to change frequently.expected to change frequently. Schema DiagramSchema Diagram Displayed schema is called schema diagram.Displayed schema is called schema diagram. Each object in schema is called a schemaEach object in schema is called a schema construct.construct.
- 13. 13 Database instance (occurrence or state)Database instance (occurrence or state) The data in a database at a particularThe data in a database at a particular moment of time.moment of time. Intension & ExtensionIntension & Extension The schema is sometimes called theThe schema is sometimes called the intension and a database instance is calledintension and a database instance is called an extension of the schema.an extension of the schema.
- 14. CD_ID Title Artist Genre 1 The Wall Pink Floyd Rock 2 Blue Train John Coltrane Jazz 3 Requiem W.A. Mozart Classical 14 Field Record Table
- 15. 15
- 16. Tuple: The actual data values for the attributes of a relation are stored in tuples, or rows, of the table. It is not necessary for a relation to have rows in order to be a relation; even if no data exists for the relation The relation remains defined with its set of attributes Attribute: The term attribute refers to characteristics.This simply means that what the column contains will be defined by the attribute of the column 16
- 17. EXAMPLES OF ATTRIBUTEEXAMPLES OF ATTRIBUTE DOMAINSDOMAINS 17
- 18. 18
- 19. Built in data integrity Data consistency and accuracy Easy data retrieval and data sharing How and where the tables of data stored make no difference You can access child table with out accessing parent table. Non-navigational in nature Find the data on the basis of the data values themselves. One point data administration Controlling redundancy Data abstraction Provide security Data entry , update and deletion will be efficient. Changes to the of the database is somewhat self- documenting. Support multiple users 19
- 20. 20 DBMS RDBMS The concepts of relationships is missing in a DBMS. If it exits it is very less. It is based on the concept Of relationships Speed of operation is very slow Speed of operation is very Fast Hardware and Software requirements are minimum Hardware and Software requirements are High Platform used is normally DOS Platform used can be any DOS, UNIX,VAX,VMS, etc Uses concept of a file Uses concept of table DBMS normally use 3GL RDBMS normally use a 4GL Examples are dBase, FOXBASE, etc Examples are ORACLE, INGRESS, SQL Server 2000 etc
- 21. • Oracle • Sybase • Microsoft SQL Server • Informix • Ingress • DB2 21
- 22. 22 Country Capital Italy Rome India New Delhi China Beijing France Tokyo Japan Paris Country Currency Italy Lira India Rupee China Quan France Yen Japan Francs EXAMPES
- 23. 23 Left Door Right Door Hood Roof Handle Window Lock Engine Body Chassis Car
- 24. 24 THANKYOU…