Dealing with Unstructured Data: Scaling to Infinity
1 like418 views

The document discusses the challenges and strategies for managing unstructured and semi-structured data in the context of big data, highlighting the importance of utilizing cloud services and SQL-based queries for effective data analysis. It provides statistics on Treasure Data's performance, including vast amounts of data imported and stored, and emphasizes the need for trade-offs between ease of data collection and system performance. Additionally, it mentions various tools and libraries like Fluentd and Hivemall that facilitate data processing and machine learning in big data environments.



























Dealing with Unstructured Data: Scaling to Infinity
- 1. Dealing with Unstructured Data Scaling to Infinity Image: Boykung/Shutterstock
- 4. There are many sources of information
- 5. Copyright ©2014 Treasure Data. All Rights Reserved. Results Push Results Push SQL Big Data Simplified: One ApproachAppServers Multi-structured Events • register • login • start_event • purchase • etc SQL-based Ad-hoc Queries SQL-based Dashboards DBs & Data Marts Other Apps Results Push Familiar & Table-oriented Infinite & Economical Cloud Data Store ✓App log data ✓Mobile event data ✓Sensor data ✓Telemetry Mobile SDKs Web SDK Multi-structured Events Multi-structured Events Multi-structured Events Multi-structured Events Agent Agent Agent Agent Agent Agent Agent Agent Embedded SDKs Server-side Agents
- 6. Copyright ©2014 Treasure Data. All Rights Reserved. What is the point of all this data? BI Business Intelligence Using Very Large Sets of Data
- 8. Copyright ©2015 Treasure Data. All Rights Reserved. Service Launched Series A Funding 100 Customers Selected by Gartner as Cool Vendor in Big Data 10 Trillion Records 5 Trillion Records Treasure Data By the Numbers (Jan-2015): 13T+ records of data imported since launch 500K+ records imported each second 1.5 Trillion+ records imported each month 12B records sent per day by one customer 13 Trillion Records Series B Funding Data Records Stored in the Treasure Data Cloud Service 0 3500000000000 7000000000000 10500000000000 14000000000000 Aug-12 Oct-12 Dec-12 Feb-13 Apr-13 Jun-13 Aug-13 Oct-13 Dec-13 Feb-14 Apr-14 Jun-14 Aug-14 Oct-14 Dec-14 8 Last 2 years
- 9. Statistics Total Records Stored 25 Trillion Managed & Supported 24 * 7 * 365 Uptime 99.99% New Records / second 1 Million Daily Twitter volume 100x 1 0 1 1 0 0 0 1 0 1 1 1 0 0 0 0 1 24 / 7
- 10. A solution? • There are trade-offs to consider • Any trade off should make it easy to collect data • Easy does it! un- and semi-structured data (multi- structured data) • Open source means it’s free; also means that you need someone on hand to maintain and implement • Cloud storage means you don’t have to scale and/or shard; tradeoff means performance hit against bare metal Image: John Hammink
- 12. Images: Lightspring/Shutterstock, John Hammink, Treasure Data There are a few intro to Data Science blogs at blog.treasuredata.com!
- 13. What does a pipeline need?
- 14. Open vs. Closed source Image: Heather Craig/Shutterstock
- 15. Images: PC World, Data-Hive, Wallpapersmela or or ?
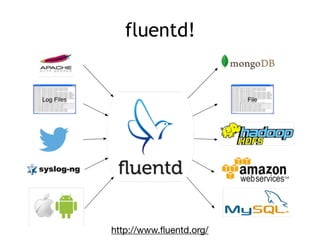
- 17. # logs from a file <source> type tail path /var/log/ httpd.log format apache2 tag web.access </source> # logs from client libraries <source> type forward port 24224 </source> # store logs to ES and HDFS <match *.*> type copy <store> type elasticsearch logstash_format
- 19. Before fluentd
- 20. Multi- structured data • un-structured data better for data for ultimate use in statistics
- 23. an open-source bulk data loader that helps data transfer between various databases, storages, file formats, and cloud services embulk.org/docs
- 26. Hivemall Hivemall is a scalable machine learning library that runs on Apache Hive. Hivemall is designed to be scalable to the number of training instances as well as the number of training features. • Classification • Regression • Recommendation • k-nearest neighbor • Anomaly Detection • Feature Engineering https://github.com/myui/hivemall
- 27. The Hadoop Story on MongoDB Image courtesy of Steven Francia @ Docker
- 28. Questions?