Debunking Common Myths in Stream Processing

This document discusses stream processing with Apache Flink. It begins by defining streaming as the continuous processing of never-ending data streams. It then debunks four common myths about stream processing: 1) that there is always a throughput/latency tradeoff, showing that Flink can achieve high throughput and low latency; 2) that exactly-once processing is not possible, but Flink provides exactly-once state guarantees with checkpoints; 3) that streaming is only for real-time applications, whereas it can also be used for historical data; and 4) that streaming is too hard, whereas most data problems are actually streaming problems. The document concludes by discussing Flink's community and examples of companies using Flink in production.






































































More Related Content
What's hot (20)
Viewers also liked (6)




Similar to Debunking Common Myths in Stream Processing (20)




















Recently uploaded (20)















![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)




Debunking Common Myths in Stream Processing
- 1. 1 Kostas Tzoumas @kostas_tzoumas Big Data Ldn November 4, 2016 Stream Processing with Apache Flink®
- 2. 2 Kostas Tzoumas @kostas_tzoumas Big Data Ldn November 4, 2016 Debunking Some Common Myths in Stream Processing
- 3. 3 Original creators of Apache Flink® Providers of the dA Platform, a supported Flink distribution
- 4. Outline What is data streaming Myth 1: The throughput/latency tradeoff Myth 2: Exactly once not possible Myth 3: Streaming is for (near) real-time Myth 4: Streaming is hard 4
- 6. 6 Reconsideration of data architecture Better app isolation More real-time reaction to events Robust continuous applications Process both real-time and historical data
- 7. 7 app state app state app state event log Query service
- 8. What is (distributed) streaming Computations on never- ending “streams” of data records (“events”) Stream processor distributes the computation in a cluster 8 Your code Your code Your code Your code
- 9. What is stateful streaming Computation and state • E.g., counters, windows of past events, state machines, trained ML models Result depends on history of stream Stateful stream processor gives the tools to manage state • Recover, roll back, version, upgrade, etc 9 Your code state
- 10. What is event-time streaming Data records associated with timestamps (time series data) Processing depends on timestamps Event-time stream processor gives you the tools to reason about time • E.g., handle streams that are out of order • Core feature is watermarks – a clock to measure event time 10 Your code state t3 t1 t2t4 t1-t2 t3-t4
- 11. What is streaming Continuous processing on data that is continuously generated I.e., pretty much all “big” data It’s all about state and time 11
- 12. Debunking some common stream processing myths 12
- 13. Myth 1: Throughput/latency tradeoff Myth 1: you need to choose between high throughput or low latency Physical limits • In reality, network determines both the achievable throughput and latency • A well-engineered system achieves these limits 13
- 14. Flink performance 10s of millions events per seconds in 10s of nodes scaled to 1000s of nodes with latency in single-digit milliseconds 14
- 15. Myth 2: Exactly once not possible Exactly once: under failures, system computes result as if there was no failure In contrast to: • At most once: no guarantees • At least once: duplicates possible Exactly once state versus exactly once delivery Myth 2: Exactly once state not possible/too costly 15
- 16. Transactions “Exactly once” is transactions: either all actions succeed or none succeed Transactions are possible Transactions are useful Let’s not start eventual consistency all over again… 16
- 17. Flink checkpoints Periodic asynchronous consistent snapshots of application state Provide exactly-once state guarantees under failures 17 9/2/2016 stream_barriers.svg checkpoint barrier n1 data stream stream record (event) checkpoint barrier n newer records part of checkpoint n1 part of checkpoint n part of checkpoint n+1 older records
- 18. End-to-end exactly once Checkpoints double as transaction coordination mechanism Source and sink operators can take part in checkpoints Exactly once internally, "effectively once" end to end: e.g., Flink + Cassandra with idempotent updates 18 transactional sinks
- 19. State management Checkpoints triple as state versioning mechanism (savepoints) Go back and forth in time while maintaining state consistency Ease code upgrades (Flink or app), maintenance, migration, and debugging, what-if simulations, A/B tests 19
- 20. Myth 3: Streaming and real time Myth 3: streaming and real-time are synonymous Streaming is a new model • Essentially, state and time • Low latency/real time is the icing on the cake 20
- 21. Low latency and high latency streams 21 2016-3-1 12:00 am 2016-3-1 1:00 am 2016-3-1 2:00 am 2016-3-11 11:00pm 2016-3-12 12:00am 2016-3-12 1:00am 2016-3-11 10:00pm 2016-3-12 2:00am 2016-3-12 3:00am… partition partition Stream (low latency) Batch (bounded stream) Stream (high latency)
- 23. Accurate computation Batch processing is not an accurate computation model for continuous data • Misses the right concepts and primitives • Time handling, state across batch boundaries Stateful stream processing a better model • Real-time/low-latency is the icing on the cake 23
- 24. Myth 4: How hard is streaming? Myth 4: streaming is too hard to learn You are already doing streaming, just in an ad hoc way Most data is unbounded and the code changes slower than the data • This is a streaming problem 24
- 25. It's about your data and code What's the form of your data? • Unbounded (e.g., clicks, sensors, logs), or • Bounded (e.g., ???*) What changes more often? • My code changes faster than my data • My data changes faster than my code 25 * Please help me find a great example of naturally bounded data
- 26. It's about your data and code If your data changes faster than your code you have a streaming problem • You may be solving it with hourly batch jobs depending on someone else to create the hourly batches • You are probably living with inaccurate results without knowing it 26
- 27. It's about your data and code If your code changes faster than your data you have an exploration problem • Using notebooks or other tools for quick data exploration is a good idea • Once your code stabilizes you will have a streaming problem, so you might as well think of it as such from the beginning 27
- 28. Flink in the real world 28
- 29. Flink community > 240 contributors, 95 contributors in Flink 1.1 42 meetups around the world with > 15,000 members 2x-3x growth in 2015, similar in 2016 29
- 30. Powered by Flink 30 Zalando, one of the largest ecommerce companies in Europe, uses Flink for real- time business process monitoring. King, the creators of Candy Crush Saga, uses Flink to provide data science teams with real-time analytics. Bouygues Telecom uses Flink for real-time event processing over billions of Kafka messages per day. Alibaba, the world's largest retailer, built a Flink-based system (Blink) to optimize search rankings in real time. See more at flink.apache.org/poweredby.html
- 31. 30 Flink applications in production for more than one year. 10 billion events (2TB) processed daily Complex jobs of > 30 operators running 24/7, processing 30 billion events daily, maintaining state of 100s of GB with exactly-once guarantees Largest job has > 20 operators, runs on > 5000 vCores in 1000-node cluster, processes millions of events per second 31
- 32. 32
- 34. Current work in Flink 34
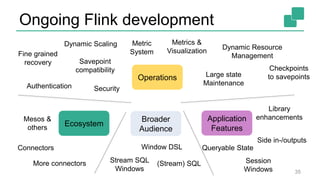
- 35. Ongoing Flink development 35 Connectors Session Windows (Stream) SQL Library enhancements Metric System Operations Ecosystem Application Features Metrics & Visualization Dynamic Scaling Savepoint compatibility Checkpoints to savepoints More connectors Stream SQL Windows Large state Maintenance Fine grained recovery Side in-/outputs Window DSL Broader Audience Security Mesos & others Dynamic Resource Management Authentication Queryable State
- 36. A longer-term vision for Flink 36
- 37. Streaming use cases Application (Near) real-time apps Continuous apps Analytics on historical data Request/response apps Technology Low-latency streaming High-latency streaming Batch as special case of streaming Large queryable state 37
- 38. Request/response applications Queryable state: query Flink state directly instead of pushing results in a database Large state support and query API coming in Flink 38 queries
- 39. In summary The need for streaming comes from a rethinking of data infra architecture • Stream processing then just becomes natural Debunking 4 common myths • Myth 1: The throughput/latency tradeoff • Myth 2: Exactly once not possible • Myth 3: Streaming is for (near) real-time • Myth 4: Streaming is hard 39