Deep Learning - CNN and RNN
22 likes6,880 views

A brief introduction to deep learning, with focus on industry favorite networks, viz. Convolutional Neural Network and Recurrent Neural Network.























![Page 24
ConvNet Layers (At a Glance)
CONV layer will compute the output of neurons that are connected to local
regions in the input, each computing a dot product between their weights
and a small region they are connected to in the input volume.
RELU layer will apply an elementwise activation function, such as the
max(0,x) thresholding at zero. This leaves the size of the volume
unchanged.
POOL layer will perform a downsampling operation along the spatial
dimensions (width, height).
FC (i.e. fully-connected) layer will compute the class scores, resulting in
volume of size [1x1xN], where each of the N numbers correspond to a
class score, such as among the N categories.
EECS 4750/5750 Machine Learning
EECS 4750/5750 Machine Learning](https://image.slidesharecdn.com/deeplearning-rnnandcnn-171116122448/85/Deep-Learning-CNN-and-RNN-24-320.jpg)









































































































































Ad
More Related Content
What's hot (20)
Viewers also liked (7)





Ad
Similar to Deep Learning - CNN and RNN (20)




















Ad
Recently uploaded (20)




















Deep Learning - CNN and RNN
- 1. Deep Learning with Convolutional Neural Network and Recurrent Neural Network Ashray Bhandare
- 2. Page 2 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning
- 3. Page 3 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning
- 4. Page 4 Introduction For a computer to do a certain task, We have to give them a set of instruction that they will follow. To give these instruction we should know what the answer is before hand. Therefore the problem cannot be generalized. What if we have a problem where we don’t know anything about it? To overcome this, we use Neural networks as it is good with pattern recognition. EECS 4750/5750 Machine Learning
- 5. Page 5 Neural Network Refresher EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 6. Page 6 Deep network EECS 4750/5750 Machine Learning
- 7. Page 7 Reasons to go Deep Historically, computers have only been useful for tasks that we can explain with a detailed list of instructions. Computers fail in applications where the task at hand is fuzzy, such as recognizing patterns. EECS 4750/5750 Machine Learning Pattern Complexity Simple Methods like SVM, regression Moderate Neural Networks outperform Complex Deep Nets – Practical Choice EECS 4750/5750 Machine Learning
- 8. Page 8 Reasons to go Deep EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 9. Page 9 Reasons to go Deep A downside of training a deep network is the computational cost. The resources required to effectively train a deep net were prohibitive in the early years of neural networks. However, thanks to advances in high- performance GPUs of the last decade, this is no longer an issue Complex nets that once would have taken months to train, now only take days. EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 10. Page 10 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 11. Page 11 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 12. Page 12 How to choose a Deep Net Convolutional Neural Network (CNN) Recurrent Neural Network (RNN) Deep Belief Network (DBN) Recursive Neural Tensor Network (RNTN) Restricted Boltzmann Machine (RBM) EECS 4750/5750 Machine Learning Applications Text Processing RNTN, RNN Image Recognition CNN, DBM Object Recognition CNN, RNTN Speech Recognition RNN Time series Analysis RNN Unlabeled data – pattern recognition RBM EECS 4750/5750 Machine Learning
- 13. Page 13 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 14. Page 14 Introduction A convolutional neural network (or ConvNet) is a type of feed-forward artificial neural network The architecture of a ConvNet is designed to take advantage of the 2D structure of an input image. A ConvNet is comprised of one or more convolutional layers (often with a pooling step) and then followed by one or more fully connected layers as in a standard multilayer neural network. EECS 4750/5750 Machine Learning VS EECS 4750/5750 Machine Learning
- 15. Page 15 Motivation behind ConvNets Consider an image of size 200x200x3 (200 wide, 200 high, 3 color channels) – a single fully-connected neuron in a first hidden layer of a regular Neural Network would have 200*200*3 = 120,000 weights. – Due to the presence of several such neurons, this full connectivity is wasteful and the huge number of parameters would quickly lead to overfitting However, in a ConvNet, the neurons in a layer will only be connected to a small region of the layer before it, instead of all of the neurons in a fully- connected manner. – the final output layer would have dimensions 1x1xN, because by the end of the ConvNet architecture we will reduce the full image into a single vector of class scores (for N classes), arranged along the depth dimension EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 16. Page 16 MLP VS ConvNet EECS 4750/5750 Machine Learning Input Hidden Output Input Hidden Output Multilayered Perceptron: All Fully Connected Layers Convolutional Neural Network With Partially Connected Convolution Layer EECS 4750/5750 Machine Learning
- 17. Page 17 MLP vs ConvNet A regular 3-layer Neural Network. A ConvNet arranges its neurons in three dimensions (width, height, depth), as visualized in one of the layers. EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 18. Page 18 How ConvNet Works For example, a ConvNet takes the input as an image which can be classified as ‘X’ or ‘O’ In a simple case, ‘X’ would look like: X or OCNN A two-dimensional array of pixels EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 19. Page 19 How ConvNet Works What about trickier cases? CNN X CNN O EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 20. Page 20 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 = ? How ConvNet Works – What Computer Sees EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 21. Page 21 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 =x How ConvNet Works EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 22. Page 22 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 X -1 -1 -1 -1 X X -1 -1 X X -1 -1 X X -1 -1 -1 -1 X 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 X -1 -1 -1 -1 X X -1 -1 X X -1 -1 X X -1 -1 -1 -1 X -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 How ConvNet Works – What Computer Sees Since the pattern doesnot match exactly, the computer will not be able to classify this as ‘X’ EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 23. Page 23 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 24. Page 24 ConvNet Layers (At a Glance) CONV layer will compute the output of neurons that are connected to local regions in the input, each computing a dot product between their weights and a small region they are connected to in the input volume. RELU layer will apply an elementwise activation function, such as the max(0,x) thresholding at zero. This leaves the size of the volume unchanged. POOL layer will perform a downsampling operation along the spatial dimensions (width, height). FC (i.e. fully-connected) layer will compute the class scores, resulting in volume of size [1x1xN], where each of the N numbers correspond to a class score, such as among the N categories. EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 25. Page 25 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 X -1 -1 -1 -1 X X -1 -1 X X -1 -1 X X -1 -1 -1 -1 X 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 X -1 -1 -1 -1 X X -1 -1 X X -1 -1 X X -1 -1 -1 -1 X -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Recall – What Computer Sees Since the pattern doesnot match exactly, the computer will not be able to classify this as ‘X’ What got changed? EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 26. Page 26 = = = Convolution layer will work to identify patterns (features) instead of individual pixels Convolutional Layer EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 27. Page 27 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 1 -1 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 -1 1 Convolutional Layer - Filters The CONV layer’s parameters consist of a set of learnable filters. Every filter is small spatially (along width and height), but extends through the full depth of the input volume. During the forward pass, we slide (more precisely, convolve) each filter across the width and height of the input volume and compute dot products between the entries of the filter and the input at any position. EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 28. Page 28 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 1 -1 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 -1 1 Convolutional Layer - Filters Sliding the filter over the width and height of the input gives 2-dimensional activation map that responds to that filter at every spatial position. EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
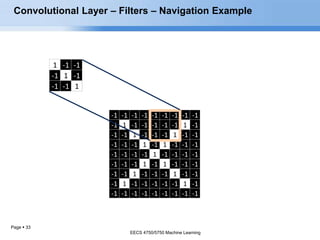
- 29. Page 29 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example Strides = 1, Filter Size = 3 X 3 X 1, Padding = 0 EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 30. Page 30 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 31. Page 31 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 32. Page 32 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 33. Page 33 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 34. Page 34 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 35. Page 35 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 36. Page 36 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 37. Page 37 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Navigation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 38. Page 38 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 39. Page 39 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 40. Page 40 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 41. Page 41 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 42. Page 42 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 43. Page 43 1 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 44. Page 44 1 1 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 45. Page 45 1 1 1 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 46. Page 46 1 1 1 1 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 47. Page 47 1 1 1 1 1 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 48. Page 48 1 1 1 1 1 1 1 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 49. Page 49 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 50. Page 50 1 1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 51. Page 51 1 1 -1 1 1 1 -1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 52. Page 52 1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 1 -1 1 1 1 -1 1 1 55 1 1 -1 1 1 1 -1 1 1 Convolutional Layer – Filters – Computation Example EECS 4750/5750 Machine Learning
- 53. Page 53 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 = 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 Convolutional Layer – Filters – Computation Example Input Size (W): 9 Filter Size (F): 3 X 3 Stride (S): 1 Filters: 1 Padding (P): 0 9 X 9 7 X 7 Feature Map Size = 1+ (W – F + 2P)/S = 1+ (9 – 3 + 2 X 0)/1 = 7 EECS 4750/5750 Machine Learning
- 54. Page 54 1 -1 -1 -1 1 -1 -1 -1 1 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 = 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 -1 -1 1 -1 1 -1 1 -1 -1 1 -1 1 -1 1 -1 1 -1 1 0.33 -0.55 0.11 -0.11 0.11 -0.55 0.33 -0.55 0.55 -0.55 0.33 -0.55 0.55 -0.55 0.11 -0.55 0.55 -0.77 0.55 -0.55 0.11 -0.11 0.33 -0.77 1.00 -0.77 0.33 -0.11 0.11 -0.55 0.55 -0.77 0.55 -0.55 0.11 -0.55 0.55 -0.55 0.33 -0.55 0.55 -0.55 0.33 -0.55 0.11 -0.11 0.11 -0.55 0.33 = = -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Filters – Output Feature Map Output Feature Map of One complete convolution: – Filters: 3 – Filter Size: 3 X 3 – Stride: 1 Conclusion: – Input Image: 9 X 9 – Output of Convolution: 7 X 7 X 3 EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 55. Page 55 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 0.33 -0.55 0.11 -0.11 0.11 -0.55 0.33 -0.55 0.55 -0.55 0.33 -0.55 0.55 -0.55 0.11 -0.55 0.55 -0.77 0.55 -0.55 0.11 -0.11 0.33 -0.77 1.00 -0.77 0.33 -0.11 0.11 -0.55 0.55 -0.77 0.55 -0.55 0.11 -0.55 0.55 -0.55 0.33 -0.55 0.55 -0.55 0.33 -0.55 0.11 -0.11 0.11 -0.55 0.33 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 Convolutional Layer – Output EECS 4750/5750 Machine Learning
- 56. Page 56 Rectified Linear Units (ReLUs) 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 0.77 Max(0,x) EECS 4750/5750 Machine Learning
- 57. Page 57 0.77 0 Rectified Linear Units (ReLUs) 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 Max(0,x) EECS 4750/5750 Machine Learning
- 58. Page 58 0.77 0 0.11 0.33 0.55 0 0.33 Rectified Linear Units (ReLUs) 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 Max(0,x) EECS 4750/5750 Machine Learning
- 59. Page 59 0.77 0 0.11 0.33 0.55 0 0.33 0 1.00 0 0.33 0 0.11 0 0.11 0 1.00 0 0.11 0 0.55 0.33 0.33 0 0.55 0 0.33 0.33 0.55 0 0.11 0 1.00 0 0.11 0 0.11 0 0.33 0 1.00 0 0.33 0 0.55 0.33 0.11 0 0.77 Rectified Linear Units (ReLUs) 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 Max(0,x) EECS 4750/5750 Machine Learning
- 60. Page 60 ReLU layer 0.77 0 0.11 0.33 0.55 0 0.33 0 1.00 0 0.33 0 0.11 0 0.11 0 1.00 0 0.11 0 0.55 0.33 0.33 0 0.55 0 0.33 0.33 0.55 0 0.11 0 1.00 0 0.11 0 0.11 0 0.33 0 1.00 0 0.33 0 0.55 0.33 0.11 0 0.77 0.33 0 0.11 0 0.11 0 0.33 0 0.55 0 0.33 0 0.55 0 0.11 0 0.55 0 0.55 0 0.11 0 0.33 0 1.00 0 0.33 0 0.11 0 0.55 0 0.55 0 0.11 0 0.55 0 0.33 0 0.55 0 0.33 0 0.11 0 0.11 0 0.33 0.33 0 0.55 0.33 0.11 0 0.77 0 0.11 0 0.33 0 1.00 0 0.55 0 0.11 0 1.00 0 0.11 0.33 0.33 0 0.55 0 0.33 0.33 0.11 0 1.00 0 0.11 0 0.55 0 1.00 0 0.33 0 0.11 0 0.77 0 0.11 0.33 0.55 0 0.33 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 0.77 -0.11 0.11 0.33 0.55 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.11 -0.11 0.11 -0.11 1.00 -0.33 0.11 -0.11 0.55 0.33 0.33 -0.33 0.55 -0.33 0.33 0.33 0.55 -0.11 0.11 -0.33 1.00 -0.11 0.11 -0.11 0.11 -0.11 0.33 -0.11 1.00 -0.11 0.33 -0.11 0.55 0.33 0.11 -0.11 0.77 0.33 -0.55 0.11 -0.11 0.11 -0.55 0.33 -0.55 0.55 -0.55 0.33 -0.55 0.55 -0.55 0.11 -0.55 0.55 -0.77 0.55 -0.55 0.11 -0.11 0.33 -0.77 1.00 -0.77 0.33 -0.11 0.11 -0.55 0.55 -0.77 0.55 -0.55 0.11 -0.55 0.55 -0.55 0.33 -0.55 0.55 -0.55 0.33 -0.55 0.11 -0.11 0.11 -0.55 0.33 EECS 4750/5750 Machine Learning
- 61. Page 61 Pooling Layer The pooling layers down-sample the previous layers feature map. Its function is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network The pooling layer often uses the Max operation to perform the downsampling process EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 62. Page 62 1.00 Pooling Pooling Filter Size = 2 X 2, Stride = 2 EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 63. Page 63 1.00 0.33 Pooling Pooling Filter Size = 2 X 2, Stride = 2 EECS 4750/5750 Machine Learning
- 64. Page 64 1.00 0.33 0.55 Pooling Pooling Filter Size = 2 X 2, Stride = 2 EECS 4750/5750 Machine Learning
- 65. Page 65 1.00 0.33 0.55 0.33 Pooling Pooling Filter Size = 2 X 2, Stride = 2 EECS 4750/5750 Machine Learning
- 66. Page 66 1.00 0.33 0.55 0.33 0.33 Pooling Pooling Filter Size = 2 X 2, Stride = 2 EECS 4750/5750 Machine Learning
- 67. Page 67 1.00 0.33 0.55 0.33 0.33 1.00 0.33 0.55 0.55 0.33 1.00 0.11 0.33 0.55 0.11 0.77 Pooling Pooling Filter Size = 2 X 2, Stride = 2 EECS 4750/5750 Machine Learning
- 68. Page 68 1.00 0.33 0.55 0.33 0.33 1.00 0.33 0.55 0.55 0.33 1.00 0.11 0.33 0.55 0.11 0.77 0.33 0.55 1.00 0.77 0.55 0.55 1.00 0.33 1.00 1.00 0.11 0.55 0.77 0.33 0.55 0.33 0.55 0.33 0.55 0.33 0.33 1.00 0.55 0.11 0.55 0.55 0.55 0.11 0.33 0.11 0.11 0.33 Pooling EECS 4750/5750 Machine Learning
- 69. Page 69 Layers get stacked -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1.00 0.33 0.55 0.33 0.33 1.00 0.33 0.55 0.55 0.33 1.00 0.11 0.33 0.55 0.11 0.77 0.33 0.55 1.00 0.77 0.55 0.55 1.00 0.33 1.00 1.00 0.11 0.55 0.77 0.33 0.55 0.33 0.55 0.33 0.55 0.33 0.33 1.00 0.55 0.11 0.55 0.55 0.55 0.11 0.33 0.11 0.11 0.33 EECS 4750/5750 Machine Learning
- 70. Page 70 Layers Get Stacked - Example 224 X 224 X 3 224 X 224 X 64 CONVOLUTION WITH 64 FILTERS 112 X 112 X 64 POOLING (DOWNSAMPLING) EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 71. Page 71 Deep stacking -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1.00 0.55 0.55 1.00 0.55 1.00 1.00 0.55 1.00 0.55 0.55 0.55 EECS 4750/5750 Machine Learning
- 72. Page 72 Fully connected layer Fully connected layers are the normal flat feed-forward neural network layers. These layers may have a non-linear activation function or a softmax activation in order to predict classes. To compute our output, we simply re- arrange the output matrices as a 1-D array. 1.00 0.55 0.55 1.00 0.55 1.00 1.00 0.55 1.00 0.55 0.55 0.55 1.00 0.55 0.55 1.00 1.00 0.55 0.55 0.55 0.55 1.00 1.00 0.55 EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 73. Page 73 Fully connected layer A summation of product of inputs and weights at each output node determines the final prediction X O 0.55 1.00 1.00 0.55 0.55 0.55 0.55 0.55 1.00 0.55 0.55 1.00 EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 74. Page 74 Putting it all together -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 1 -1 -1 -1 -1 -1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 X O EECS 4750/5750 Machine Learning
- 75. Page 75 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 76. Page 76 Hyperparameters (knobs) Convolution – Filter Size – Number of Filters – Padding – Stride Pooling – Window Size – Stride Fully Connected – Number of neurons EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 77. Page 77 Case Studies LeNet – 1998 AlexNet – 2012 ZFNet – 2013 VGG – 2014 GoogLeNet – 2014 ResNet – 2015 EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 78. Page 78 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 79. Page 79 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 80. Page 80 Humans don’t start their thinking from scratch every second. You don’t throw everything away and start thinking from scratch again. Your thoughts have persistence. You make use of context and previous knowledge to understand what is coming next Recurrent neural networks address this issue. They are networks with loops in them, allowing information to persist. EECS 4750/5750 Machine Learning Recurrent Neural Network -Intro EECS 4750/5750 Machine Learning
- 81. Page 81 What’s for dinner? pizza sushi waffles day of the week month of the year late meeting Recurrent Neural Network -Intro EECS 4750/5750 Machine Learning
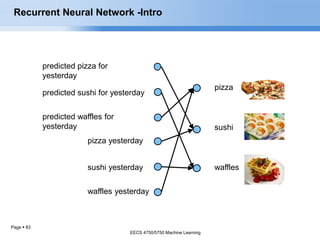
- 82. Page 82 pizza sushi waffles pizza yesterday sushi yesterday waffles yesterday What’s for dinner? Recurrent Neural Network -Intro EECS 4750/5750 Machine Learning
- 83. Page 83 pizza sushi waffles pizza yesterday sushi yesterday waffles yesterday predicted pizza for yesterday predicted sushi for yesterday predicted waffles for yesterday Recurrent Neural Network -Intro EECS 4750/5750 Machine Learning
- 84. Page 84 A vector is a list of values Weather vectorHigh temperature 67 43 13 .25 .83 Low temperature Wind speed Precipitation Humidity == “High is 67 F. Low is 43 F. Wind is 13 mph. .25 inches of rain. Relative humidity is 83%.” 67 43 13 .25 .83 Vectors as Inputs EECS 4750/5750 Machine Learning
- 85. Page 85 A vector is a list of values 0 0 1 0 0 0 0 Day of week vector Sunday 0 0 1 0 0 0 0 Monday Tuesday Wednesday Thursday Friday Saturday ==“It’s Tuesday” Vectors as Inputs EECS 4750/5750 Machine Learning
- 86. Page 86 A vector is a list of values Dinner prediction vector Pizza 0 1 0 Sushi Waffles == “Tonight I think we’re going to have sushi.” 0 1 0 Vectors as Inputs EECS 4750/5750 Machine Learning
- 87. Page 87 pizza sushi waffles pizza yesterday sushi yesterday waffles yesterday predicted pizza for yesterday predicted sushi for yesterday predicted waffles for yesterday How RNN’s Work EECS 4750/5750 Machine Learning
- 88. Page 88 prediction for today dinner yesterday predictions for yesterday How RNN’s Work EECS 4750/5750 Machine Learning
- 89. Page 89 predicti on new information How RNN’s Work EECS 4750/5750 Machine Learning
- 90. Page 90 predicti on How RNN’s Work EECS 4750/5750 Machine Learning
- 91. Page 91 Unrolled predictions pizza sushi waffles yesterdaytwo days ago ... ... ... How RNN’s Work EECS 4750/5750 Machine Learning
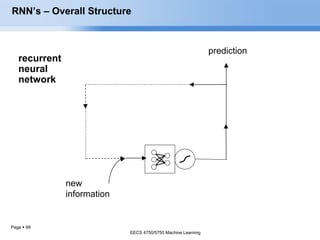
- 92. Page 92 RNN’s – Overall Structure These loops make recurrent neural networks seem kind of mysterious. A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop: EECS 4750/5750 Machine Learning
- 93. Page 93 Consider Simple statements Harry met Sally. Sally met James. James met Harry. ... Dictionary : {Harry, Sally, James, met, .} RNN’s - Example For the sake of illustration, lets build an RNN that looks at only one previous word. EECS 4750/5750 Machine Learning
- 94. Page 94 predicti on new information Sally Harry James saw . Sally Harry James met . Sally Harry James met . RNN’s - Example EECS 4750/5750 Machine Learning
- 95. Page 95 predicti on new information . RNN’s - Example Sally Harry James saw . Sally Harry James met . Sally Harry James met . EECS 4750/5750 Machine Learning
- 96. Page 96 predicti on new information RNN’s - Example Sally Harry James saw . Sally Harry James met . Sally Harry James met . EECS 4750/5750 Machine Learning
- 97. Page 97 prediction new information recurrent neural network RNN’s - Example EECS 4750/5750 Machine Learning
- 98. Page 98 Hyperbolic tangent (tanh) squashing function Your number goes in here The squashed version comes out here No matter what you start with, the answer stays between -1 and 1. EECS 4750/5750 Machine Learning
- 99. Page 99 prediction new information recurrent neural network RNN’s – Overall Structure EECS 4750/5750 Machine Learning
- 100. Page 100 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 101. Page 101 Mistakes an RNN can makeHarry met Harry. Sally met James met Harry met … James. Harry. Sally. Why RNN’s Fail This can be easily resolved by going back multiple time steps EECS 4750/5750 Machine Learning
- 102. Page 102 “the clouds are in the sky” Why RNN’s Fail –Vanishing or Exploding Gradient In such cases, where the gap between the relevant information and the place that it’s needed is small, RNNs can learn to use the past information. EECS 4750/5750 Machine Learning
- 103. Page 103 Why RNN’s Fail –Vanishing or Exploding Gradient EECS 4750/5750 Machine Learning
- 104. Page 104 “I grew up in France. I lived there for about 20 years. The people there are very nice. I can speak fluent French” Why RNN’s Fail –Vanishing or Exploding Gradient Unfortunately, as that gap grows, RNNs become unable to learn to connect the information. EECS 4750/5750 Machine Learning
- 105. Page 105 Why RNN’s Fail –Vanishing or Exploding Gradient EECS 4750/5750 Machine Learning
- 106. Page 106 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 107. Page 107 prediction new information recurrent neural network Solution – Long Short Term Memory EECS 4750/5750 Machine Learning
- 108. Page 108 prediction new information Solution – Long Short Term Memory EECS 4750/5750 Machine Learning
- 109. Page 109 memory memory forgetting prediction Prediction + Memories new information Forget Gate Layer EECS 4750/5750 Machine Learning
- 110. Page 110 Plus junction: element-by-element addition 6 7 8 3 4 5 = 3 + 6 4 + 7 5 + 8 9 11 13 = EECS 4750/5750 Machine Learning
- 111. Page 111 Times junction: element-by-element multiplication 6 7 8 3 4 5 = 3 x 6 4 x 7 5 x 8 18 28 40 = EECS 4750/5750 Machine Learning
- 112. Page 112 Gating 1.0 0.5 0.0 0.8 0.8 0.8 = 0.8 x 1.0 0.8 x 0.5 0.8 x 0.0 0.8 0.4 0.0 = Signal On / Off gating EECS 4750/5750 Machine Learning
- 113. Page 113 Logistic (sigmoid) squashing function 1.0 0.5 1.0 2.0-1.0-2.0 No matter what you start with, the answer stays between 0 and 1. EECS 4750/5750 Machine Learning
- 114. Page 114 memory memory forgetting prediction Prediction + Memories new information Forget Gate Layer EECS 4750/5750 Machine Learning
- 115. Page 115 collected possibilities selection memory forgetting possibilities Prediction new information Long Short Term Memory EECS 4750/5750 Machine Learning
- 116. Page 116 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction new information Long Short Term Memory EECS 4750/5750 Machine Learning
- 117. Page 117 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 118. Page 118 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction Harry met Sally. James … LSTM in Action EECS 4750/5750 Machine Learning
- 119. Page 119 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction Harry met Sally. James … James, Harry, Sally LSTM in Action EECS 4750/5750 Machine Learning
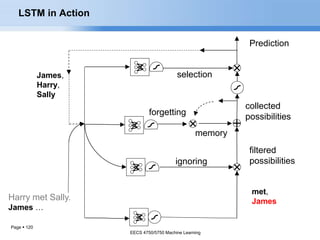
- 120. Page 120 filtered possibilitiesignoring collected possibilities selection memory forgetting Prediction Harry met Sally. James … James, Harry, Sally met, James LSTM in Action EECS 4750/5750 Machine Learning
- 121. Page 121 ignoring collected possibilities selection memory forgetting Prediction Harry met Sally. James … James, Harry, Sally met, James met, James LSTM in Action EECS 4750/5750 Machine Learning
- 122. Page 122 ignoring selection memory forgetting Prediction Harry met Sally. James … James, Harry, Sally met, James met, James met, James LSTM in Action EECS 4750/5750 Machine Learning
- 123. Page 123 ignoring selection memory forgetting Harry met Sally. James … James, Harry, Sally met, James met, James met, James met LSTM in Action EECS 4750/5750 Machine Learning
- 124. Page 124 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction new information LSTM in Action EECS 4750/5750 Machine Learning
- 125. Page 125 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction new information met LSTM in Action EECS 4750/5750 Machine Learning
- 126. Page 126 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction met Harry met Sally. James met… LSTM in Action EECS 4750/5750 Machine Learning
- 127. Page 127 filtered possibilitiesignoring collected possibilities selection memory forgetting possibilities Prediction met Harry met Sally. James met… met, James LSTM in Action EECS 4750/5750 Machine Learning
- 128. Page 128 filtered possibilitiesignoring collected possibilities selection James forgetting possibilities Prediction met Harry met Sally. James met… met, James LSTM in Action EECS 4750/5750 Machine Learning
- 129. Page 129 filtered possibilitiesignoring collected possibilities selection James forgetting James, Harry, Sally Prediction met Harry met Sally. James met… met, James LSTM in Action EECS 4750/5750 Machine Learning
- 130. Page 130 ignoring collected possibilities selection James forgetting James, Harry, Sally Prediction met Harry met Sally. James met… met, James James, Harry, Sally LSTM in Action EECS 4750/5750 Machine Learning
- 131. Page 131 ignoring Harry, Sally selection James forgetting James, Harry, Sally Prediction met Harry met Sally. James met… met, James James, Harry, Sally LSTM in Action EECS 4750/5750 Machine Learning
- 132. Page 132 ignoring Harry, Sally selection James forgetting James, Harry, Sally Harry, Sally met Harry met Sally. James met… met, James James, Harry, Sally LSTM in Action EECS 4750/5750 Machine Learning
- 133. Page 133 Agenda Introduction to Deep Learning – Neural Nets Refresher – Reasons to go Deep Demo 1 – Keras How to Choose a Deep Net Introcuction to CNN – Architecture Overview – How ConvNet Works ConvNet Layers – Convolutional Layer – Pooling Layer – Normalization Layer (ReLU) – Fully-Connected Layer Hyper Parameters EECS 4750/5750 Machine Learning Demo 2 – MNIST Classification Introduction to RNN – Architecture Overview – How RNN’s Works – RNN Example Why RNN’s Fail LSTM – Memory – Selection – Ignoring LSTM Example Demo 3 – Imdb Review Classification Image Captioning EECS 4750/5750 Machine Learning
- 134. Page 134 References Karpathy, A. (n.d.). CS231n Convolutional Neural Networks for Visual Recognition. Retrieved from http://cs231n.github.io/convolutional-networks/#overview Rohrer, B. (n.d.). How do Convolutional Neural Networks work?. Retrieved from http://brohrer.github.io/how_convolutional_neural_networks_work.html Brownlee, J. (n.d.). Crash Course in Convolutional Neural Networks for Machine Learning. Retrieved from http://machinelearningmastery.com/crash-course-convolutional-neural- networks/ Lidinwise (n.d.). The revolution of depth. Retrieved from https://medium.com/@Lidinwise/the- revolution-of-depth-facf174924f5#.8or5c77ss Nervana. (n.d.). Tutorial: Convolutional neural networks. Retrieved from https://www.nervanasys.com/convolutional-neural-networks/ Olah, C. (n.d.). Tutorial: Understanding LSTM Networks. Retrieved from http://colah.github.io/posts/2015-08-Understanding-LSTMs/ Rohrer, B. (n.d.). Tutorial: How Recurrent Neural Networks and Long Short-Term Memory Work. Retrieved from https://brohrer.github.io/how_rnns_lstm_work.html Serrano, L. (n.d.). A friendly introduction to Recurrent Neural Networks. Retrieved from https://www.youtube.com/watch?v=UNmqTiOnRfg&t=87s EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
- 135. Page 135 Thank you EECS 4750/5750 Machine Learning EECS 4750/5750 Machine Learning
Editor's Notes
- #6: NN is all about inputs on which progressively complex calculations are being performed. Then we get an output which solves a particular problem
- #8: Neural nets tend to be too computationally expensive for data with simple patterns; in such cases you should use a model like Logistic Regression or an SVM. As the pattern complexity increases, neural nets start to outperform other machine learning methods. At the highest levels of pattern complexity – high-resolution images for example – neural nets with a small number of layers will require a number of nodes that grows exponentially with the number of unique patterns. Even then, the net would likely take excessive time to train, or simply would fail to produce accurate results.
- #9: The reason is that different parts of the net can detect simpler patterns and then combine them together to detect a more complex pattern. For example, a convolutional net can detect simple features like edges, which can be combined to form facial features like the nose and eyes, which are then combined to form a face In deep-learning networks, each layer of nodes trains on a distinct set of features based on the previous layer’s output. The further you advance into the neural net, the more complex the features your nodes can recognize, since they aggregate and recombine features from the previous layer.
- #14: Two big categories in industry. Image classification CNN Sequence modelling RNN Facebook image tag: CNN Apple self driving cars: CNN Google translate: RNN Image cationing: CNN, RMM Alexa, Siri, Google Voice - RNN
- #29: The distance that filter is moved across the input from the previous layer each activation is referred to as the stride. Sometimes it is convenient to pad the input volume with zeros around the border. Zero padding is allows us to preserve the spatial size of the output volumes
- #80: Up till now, we have seen networks with fixed input that produce a fixed output. Not only that: These models perform this mapping using a fixed amount of computational steps (e.g. the number of layers in the model). We will see, networks that allow us to operate over sequences of vectors: Sequences in the input, the output, or in the most general case both Text processing, Speech Recognition, Sentiment Analysis, Language Translation
- #82: Set up a Neural network Variables that affect, what you are gonna have for dinner. NN doesn’t work very well. As the data has a pattern. Pizza ---sushi ---- waffels (cycle) Doent depend on the day of the wek or anything else
- #84: Actual information of yesterday but also our predictions of yesterday.
- #91: If we were lacking some information. Say we were out for two weeks. We can still make use of this model. We will make us of our his history and go from there.
- #92: We can unwrap or unwind vector in time, until we have some information. Then we play it forward.
- #93: These loops make recurrent neural networks seem kind of mysterious. However, if you think a bit more, it turns out that they aren’t all that different than a normal neural network. A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. Consider what happens if we unroll the loop: These can be thought of multiple timesteps
- #95: After training, we would see certain patterns, Name ----- ‘met or full stop’
- #96: Similaryly previous predictions would also make the same kind of decidion
- #99: Helpful when you have loop like this. Same values get processed. In the course of the process, some values get multiplied and blow up.. This is to keep the values in a controlled range.
- #102: Our model looks back only one time step, such errors can occur
- #104: We know that the weights of a NN get updated due to the change in error with respect to the change in weights. Learning rate. With more layers, we have to back propagate even further. In this case we will follow the chain rule and multiply the gradients till we reach that layer
- #105: This is an example of Long –term dependency
- #107: LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn! The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates.
- #110: We introduce memory, se we can save information from various timesteps The first step in our LSTM is to decide what information we’re going to throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate layer.” outputs a number between 0 and 1 for each number. A 1 represents “completely keep this” while a 0 represents “completely get rid of this.”
- #113: Gating helps to control the flow of input. Singnal pass right though, or is blocked or signal is passed through but controlled Gating is done using the sigmoid function
- #114: A value of zero means “let nothing through,” while a value of one means “let everything through!”
- #115: Predictions are held on to for next timestep, some are forgotten some are remembered ----- gating Those which are rememberd are saved. Entire separate NN that learns when to forget what When we combine prediction + memories, we need something to determine what shoelud be used as prediction and what should not be used as predictions
- #116: we need to decide what we’re going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer which decides what parts of the cell state we’re going to output. This is learnt by their own NN
- #117: The next step is to decide what new information we’re going to store in the cell state. Things that are not immediately relevant are kept aside so that it does not cloud the judgement of the model
- #121: Positive prediction for met And negative prediction for james as it does not expect to see it in near future
- #122: Example is very simple, we don’t need the ignoring step, so lets move along
- #123: For simplicity, lets assume there is memory right now
- #124: not selection has leanrt, since recent prediction was name -- - it selects a verb or a full stop
- #128: Before we move ahead with the prdictions, an interesting thing happened. Met and not james went into the forgetting layer. Now the forgetting layers said that based on the recent output ‘met’ I can forget about it but I will keep ‘not james’ in memery
- #131: Ignoring the ignoring layer
- #132: Negatice James cancels positive Jumps
- #133: This shows that LSTM can look back may timesteps. And avoid outputs like James met james