Deep Learning for Computer Vision (2/4): Object Analytics @ laSalle 2016
15 likes3,257 views

The document presents a lecture by Xavier Giró i Nieto on deep learning methods for computer vision, focusing on object detection and segmentation using approaches like R-CNN and Fast R-CNN. It discusses various proposal methods for object detection, including hand-crafted and deep learning-based techniques such as DeepBox and Faster R-CNN. The lecture emphasizes improvements in detection capabilities for known and unknown objects using these advanced convolutional neural network architectures.




![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Proposals: Hand-crafted
5
Slides credit:
Marc Bolaños
Hand-crafted proposals used to be based on bottom-up proposals.
Selective Search (SS) Multiscale Combinatorial Grouping (MCG)
[SS] Uijlings, Jasper RR, Koen EA van de Sande, Theo Gevers, and Arnold WM Smeulders. "Selective search for object
recognition." International journal of computer vision 104, no. 2 (2013): 154-171.
[MCG] Arbeláez, Pablo, Jordi Pont-Tuset, Jonathan Barron, Ferran Marques, and Jitendra Malik. "Multiscale combinatorial
grouping." CVPR 2014.](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-5-320.jpg)
![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Proposals: DeepBox
6
Kuo, Weicheng, Bharath Hariharan, and Jitendra Malik. "Deepbox: Learning objectness with convolutional
networks." ICCV 2015. [software]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-6-320.jpg)









![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Detection: Objects
16
DPM (HOG features)[1] R-CNN [2] SPPnet [3]
Hand-crafted features Deep features
+60 %
Slide credit:
Amaia Salvador](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-16-320.jpg)







![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Detection: Objects: Fast R-CNN
24
Slide credit:
Amaia Salvador
Same as SPP[3], but single scale](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-24-320.jpg)


![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Detection: Objects: Fast R-CNN
27
Slide credit:
Amaia Salvador
AlexNet [4], VGG16 [5], VGG_1024 [6]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-27-320.jpg)

![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Detection: Objects: Faster R-CNN
29
Ren, S., He, K., Girshick, R. and Sun, J., 2015. Faster R-CNN: Towards real-time
object detection with region proposal networks. In Advances in Neural Information
Processing Systems (pp. 91-99). [Python code] [Matlab code]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-29-320.jpg)















![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 46
Detection: Objects: Reinforcement L.
Caicedo, Juan C., and Svetlana Lazebnik. "Active object localization with deep reinforcement learning." ICCV
2015 [Slides by Miriam Bellver]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-46-320.jpg)














![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Detection: Faces:DDFD
61
Farfade, Sachin Sudhakar, Mohammad Saberian, and Li-Jia Li. "Multi-view Face
Detection Using Deep Convolutional Neural Networks." ICMR (2015). [software]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-61-320.jpg)




















![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 82
Faces: Recognition: VGG Face
Parkhi, Omkar M., Andrea Vedaldi, and Andrew Zisserman. "Deep face recognition."
Proceedings of the British Machine Vision 1, no. 3 (2015): 6. [software]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-82-320.jpg)









![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 93
Objects: Recognition: Retrieval
(336x256)
Resolution
conv5_1 from
VGG16[1]
(42x32)
25K centroids 25K-D vector](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-93-320.jpg)












![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Objects: Segmentation: Farabet
106
Solution 3: Multi-level parsing
Problems with Solutions 1 & 2:
Observation level.
BPT
[Garrido, Salembier]](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-106-320.jpg)




![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Objects: Segmentation: SDS
111
Slide credit:
Eduard Fontdevila
BBOX CNN
feature
vector
1
feature
vector
2
[1 2]
*Finetuned to classify bboxes (with background), so extracting features from the region foreground is
suboptimal
BBOX CNN*
vector A
background masked out
with the mean image](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-111-320.jpg)
![Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016)
Objects: Segmentation: SDS
112
Slide credit:
Eduard Fontdevila
● Training: 2 networks trained in isolation
● Testing: results are combined
BBOX CNN
feature
vector
1
feature
vector
2
[1 2]
REGION
CNN
vector B](https://image.slidesharecdn.com/02lasallemmmdlcv-objectanalytics-160505221315/85/Deep-Learning-for-Computer-Vision-2-4-Object-Analytics-laSalle-2016-112-320.jpg)







Deep Learning for Computer Vision (2/4): Object Analytics @ laSalle 2016
- 1. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) @DocXavi Deep Learning for Computer Vision Object Analytics 5 May 2016 Xavier Giró-i-Nieto Master en Creació Multimedia
- 2. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in three parts 2 Images (global) Objects (local) Deep ConvNets for Recognition for... Video (2D+T)
- 3. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in four parts 3 Detection Recognition Local analysis for... Segmentation person bag me my bag person bag Proposals
- 4. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in four parts 4 Detection Recognition Local analysis for... Segmentation person bag me my bag person bag Proposals
- 5. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: Hand-crafted 5 Slides credit: Marc Bolaños Hand-crafted proposals used to be based on bottom-up proposals. Selective Search (SS) Multiscale Combinatorial Grouping (MCG) [SS] Uijlings, Jasper RR, Koen EA van de Sande, Theo Gevers, and Arnold WM Smeulders. "Selective search for object recognition." International journal of computer vision 104, no. 2 (2013): 154-171. [MCG] Arbeláez, Pablo, Jordi Pont-Tuset, Jonathan Barron, Ferran Marques, and Jitendra Malik. "Multiscale combinatorial grouping." CVPR 2014.
- 6. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox 6 Kuo, Weicheng, Bharath Hariharan, and Jitendra Malik. "Deepbox: Learning objectness with convolutional networks." ICCV 2015. [software]
- 7. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox 7 Slides credit: Marc Bolaños Deepbox proposes a very simple method: 1) Use a state-of-the-art method (Edge Box) to generate initial object proposals. 2) Rerank them (and possibly discard them) by using DeepBox.
- 8. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox: Architecture 8 Slides credit: Marc Bolaños PASCAL VOC AUC = 0.75, IoU = 0.5 AUC = 0.62, IoU = 0.7 PASCAL VOC AUC = 0.74, IoU = 0.5 AUC = 0.60, IoU = 0.7 AlexNet architecture (heavier) DeepBox architecture (lighter) Small drop
- 9. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox: Training 9 Slides credit: Marc Bolaños 1) Initialize layers with AlexNet weights. 3) Train on Hard Negatives 2) Train on Sliding Windows Negative Samples: Extract windows by raster scanning. Positive Samples: Having GT bounding boxes, they generate samples per instance with a perturbation of: By using bottom-up proposals from Edge boxes: If GT overlap threshold <= 0.3 → Negative Samples If GT overlap threshold >= 0.7 → Positive Samples:
- 10. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox: Results 10 DeepBox Edge Boxes DeepBox Edge Boxes Slides credit: Marc Bolaños
- 11. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox: Results 11 With a rather simple approach ConvNets can obtain much better results than previous techniques for Object Proposals. Slides credit: Marc Bolaños
- 12. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox: Results 12 Slides credit: Marc Bolaños
- 13. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Proposals: DeepBox: Results 13 Increasing not only Detection capabilities of known classes, but also of unknown ones (suitable for Object Discovery). Slides credit: Marc Bolaños
- 14. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in four parts 14 Detection Recognition Local analysis for... Segmentation person bag me my bag person bag Proposals
- 15. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects 15
- 16. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects 16 DPM (HOG features)[1] R-CNN [2] SPPnet [3] Hand-crafted features Deep features +60 % Slide credit: Amaia Salvador
- 17. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects 17 Girshick, Ross, Forrest Iandola, Trevor Darrell, and Jitendra Malik. "Deformable Part Models are Convolutional Neural Networks." CVPR 2015 Convnets (CNNs) actually learn similar detectors to the ones learned by Deformable Parts-based Models (DPMs)
- 18. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: R-CNN 18 Girshick, R., Donahue, J., Darrell, T., & Malik, J. . Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014
- 19. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: R-CNN 19 Slide credit: Joost van de Weijer
- 20. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: R-CNN 20 Slide credit: Joost van de Weijer
- 21. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: R-CNN 21
- 22. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 22 Girshick, Ross. "Fast R-CNN." ICCV 2015.
- 23. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 23 Slide credit: Amaia Salvador
- 24. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 24 Slide credit: Amaia Salvador Same as SPP[3], but single scale
- 25. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 25 He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Spatial pyramid pooling in deep convolutional networks for visual recognition." PAMI 2015. Slide credit: Joost van de Weijer
- 26. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 26 Slide credit: Amaia Salvador H h w h w Size of pooling bins: h / H’ x w/ W’ w/W’ h/H’ max pooling CONV5
- 27. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 27 Slide credit: Amaia Salvador AlexNet [4], VGG16 [5], VGG_1024 [6]
- 28. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Fast R-CNN 28 Slide credit: Amaia Salvador Multi-task loss
- 29. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 29 Ren, S., He, K., Girshick, R. and Sun, J., 2015. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems (pp. 91-99). [Python code] [Matlab code]
- 30. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 30 Slide credit: Amaia Salvador Selective Search CPMC MCG Object Proposal computation is the bottleneck in current state of the art object detection systems Selective Search. Van de Sande, K. E., Uijlings, J. R., Gevers, T., & Smeulders, A. W. (2011, November). Segmentation as selective search for object recognition. InComputer Vision (ICCV), 2011 IEEE International Conference on (pp. 1879-1886). IEEE. CPMC. Carreira, J., & Sminchisescu, C. (2010, June). Constrained parametric min-cuts for automatic object segmentation. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on (pp. 3241-3248). IEEE. MCG. Arbeláez, P., Pont-Tuset, J., Barron, J., Marques, F., & Malik, J. (2014). Multiscale combinatorial grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 328-335).
- 31. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 31 Slide credit: Amaia Salvador Selective Search CPMC MCG Replace the usage of external Object Proposals with a Region Proposal Network (RPN).
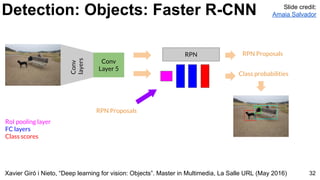
- 32. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 32 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN RPN Proposals RPN Proposals Class probabilities RoI pooling layer FC layers Class scores
- 33. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 33 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN RPN Proposals RPN Proposals Class probabilities RoI pooling layer FC layers Class scores
- 34. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 34 Slide credit: Amaia Salvador Objectness scores (object/no object) Bounding Box Regression In practice, k = 9 (3 different scales and 3 aspect ratios)
- 35. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 35 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN RPN Proposals RPN Proposals Class probabilities RoI pooling layer FC layers Class scores
- 36. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 36 Slide credit: Amaia Salvador Fast R-CNN
- 37. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 37 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN RPN Proposals RPN Proposals Class probabilities RoI pooling layer FC layers Class scores 4-step training to share features for RPN and Fast R-CNN
- 38. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 38 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN RPN Proposals Step 1: Train RPN initialized with an ImageNet pre-trained model. ImageNet weights (fine tuned)
- 39. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 39 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN Proposals (learned in 1) Class probabilities Step 2: Train Fast R-CNN with learned RPN proposals. ImageNet weights (fine tuned)
- 40. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 40 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN RPN Proposals Step 3: The model trained in 2 is used to initialize RPN and train again. Weights from Step 2 (fixed)
- 41. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 41 Slide credit: Amaia Salvador Conv Layer 5 Conv layers RPN Proposals (learned in 3) Class probabilities Step 4: Fine tune FC layers of Fast R-CNN using same shared convolutional layers as in 3. Weights from Step 2&3 (fixed)
- 42. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 42 Slide credit: Amaia Salvador Detection Accuracy (Pascal VOC) Timing in ms (Pascal VOC)
- 43. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 43 Slide credit: Amaia Salvador
- 44. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 44 Slide credit: Amaia Salvador
- 45. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Objects: Faster R-CNN 45 Slide credit: Amaia Salvador
- 46. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 46 Detection: Objects: Reinforcement L. Caicedo, Juan C., and Svetlana Lazebnik. "Active object localization with deep reinforcement learning." ICCV 2015 [Slides by Miriam Bellver]
- 47. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 47 Detection: Objects: Reinforcement L. Object is localized based on visual features from AlexNet FC6.
- 48. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 48 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Set of actions A Transformation actions
- 49. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 49 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Set of actions A Terminates the sequence of the current search Marks the region, inhibition-of-return (IoR)
- 50. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 50 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Set of states S (o,h) o = feature vector from pre-trained CNN fc6 : 4096 dim h = history of taken actions binary vector dim 90
- 51. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 51 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Reward Function R ground-truthbounding box
- 52. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 52 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Reward Function R for trigger action The Reward function considers the number of steps as a cost 3 minimum IoU: 0.6
- 53. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 53 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Policy function If the current state is S, which should be the next action A? Reinforcement Learning using a Q-learning
- 54. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 54 Detection: Objects: Reinforcement Slide credit: Míriam Bellver The action-value function is estimated using a neural network that: ● has as many output units as actions ● the algorithm incorporates a replay-memory to collect experiences ● category-specific Q-network Policy of the agent: selection action A with maximum estimated value of the learnt action-value function.
- 55. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 55 Detection: Objects: Reinforcement Slide credit: Míriam Bellver
- 56. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 56 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Datasets for training and testing : PASCAL VOC Two modes of evaluation: 1) All attended Regions (AAR) 2) Terminal regions (TR)
- 57. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 57 Detection: Objects: Reinforcement Slide credit: Míriam Bellver Best performance with few region proposals
- 58. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 58 Detection: Objects: Reinforcement Slide credit: Míriam Bellver
- 59. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 59 Detection: Objects: Reinforcement Slide credit: Míriam Bellver
- 60. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces 60
- 61. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces:DDFD 61 Farfade, Sachin Sudhakar, Mohammad Saberian, and Li-Jia Li. "Multi-view Face Detection Using Deep Convolutional Neural Networks." ICMR (2015). [software]
- 62. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Train 62 Dataset ● Source: Annotated Facial Landmarks in the Wild by TU Graz ● 25k annotated faces on images downloaded from Flickr. ● 380k manually annotated facial landmarks.
- 63. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Train 63 ● Randomly samples sub-windows (blocks) ○ Positive examples if Intersection-over Union (IoU) with an annotated face is larger than 50%. ○ ...and negative sample otherwise. ● Total samples: 200K positive and 20M negative.
- 64. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Test 64 Test images are rescaled up/down 3 times per octave to find different sizes.
- 65. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Test 65 Sliding window of 227x227 over the test image. Source: James Hays, “Object Category Detetcion: Sliding Windows” (Brown University, 2011)
- 66. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Test 66 Fully-connected layers are converted to convolutional layers, which allows processing images from any size. Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully Convolutional Networks for Semantic Segmentation." CVPR 2015
- 67. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Test 67 ● This makes possible to: ○ Efficiently run the convnet on images of any size. ○ Obtain a heat-map of the face etector.
- 68. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Test 68 ● Non-Maximum Suppression (NMS) to avoid overlapped detections. Source: Adrian Rosebrock, “Non-Maximum Suppression for Object Detection in Python” (Pyimagesearch, 2014)
- 69. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Results 69
- 70. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Detection: Faces: DDFD: Results 70 Precision vs Recall Curves - DPM corresponds to Deformable Part-based Models. - OpenCV face detector is an implementation of Viola & Jones. - IMPORTANT: DPM or Headhunter need extra information about pose or facial landmarks during training.
- 71. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in four parts 71 Detection Recognition Local analysis for... Segmentation person bag me my bag person bag Proposals
- 72. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 72 Faces: Recognition: FaceNet Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "FaceNet: A Unified Embedding for Face Recognition and Clustering." CVPR 2015 (Extended summary slides by Xavier Giro on the ReadCV seminar.)
- 73. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 73 Faces: Recognition: FaceNet Faces Euclidean space where distances correspond to face similarity FaceNet
- 74. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 74 Faces: Recognition: FaceNet End-to-end learning of an embedding (distance metric learning)... Weinberger, Kilian Q., and Lawrence K. Saul. "Distance metric learning for large margin nearest neighbor classification." The Journal of Machine Learning Research 10 (2009): 207-244
- 75. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 75 Faces: Recognition: FaceNet ...by means of well chosen triplets, using curriculum learning. Bengio, Yoshua, Jérôme Louradour, Ronan Collobert, and Jason Weston. "Curriculum learning." In Proceedings of the 26th annual international conference on machine learning, pp. 41-48. ACM, 2009
- 76. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 76 Faces: Recognition: FaceNet
- 77. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 77 Faces: Recognition: FaceNet Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks." In Computer Vision–ECCV 2014, pp. 818-833. Springer International Publishing, 2014 (Slides by Xavier Giró-i-Nieto) Architecture 1 (NN1): ZF
- 78. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 78 Faces: Recognition: FaceNet Architecture 2 (NN2): GoogLeNet Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. "Going Deeper With Convolutions." CVPR 2015. (Slides by Elisa Sayrol)
- 79. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 79 Faces: Recognition: FaceNet
- 80. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 80 Faces: Recognition: FaceNet: Test LBW: 99.63% (new record) YouTubeFaces DB: 95.12%
- 81. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 81 Faces: Recognition: FaceNet: Software Software implementation: OpenFace
- 82. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 82 Faces: Recognition: VGG Face Parkhi, Omkar M., Andrea Vedaldi, and Andrew Zisserman. "Deep face recognition." Proceedings of the British Machine Vision 1, no. 3 (2015): 6. [software]
- 83. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) E. Mohedano, Salvador, A., McGuinness, K., Giró-i-Nieto, X., O'Connor, N., and Marqués, F., “Bags of Local Convolutional Features for Scalable Instance Search”, ICMR 2016 83 Objects: Recognition: Retrieval
- 84. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 84 Objects: Recognition: Retrieval Image Database Visual Query “A dog” Expected outcome:
- 85. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 85 Objects: Recognition: Retrieval Image Database Visual Query “This dog” Expected outcome:
- 86. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 86 ... Instance Retrieval (Instance: Object, Building, Person, Place…) Objects: Recognition: Retrieval
- 87. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 87 Objects: Recognition: Retrieval v1 = (v11 , …, v1n ) vk = (vk1 , …, vkn ) ... INVERTED FILE word Image ID 1 1, 12, 2 1, 30, 102 3 10, 12 4 2,3 6 10 ... Local hand-crafted features (e.g. SIFT) Bag of Visual WordsN-Dimensional feature space High-dimensional Highly sparse
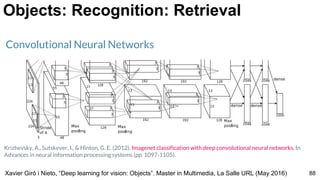
- 88. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 88 Objects: Recognition: Retrieval Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105). Convolutional Neural Networks
- 89. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 89 Objects: Recognition: Retrieval Babenko, A., Slesarev, A., Chigorin, A., & Lempitsky, V. (2014). Neural codes for image retrieval. In ECCV 2014 Razavian, A., Azizpour, H., Sullivan, J., & Carlsson, S. (2014). CNN features off-the-shelf: an astounding baseline for recognition. In DeepVision CVPRW 2014 Convolutional Neural Networks FC layers as global feature representation
- 90. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 90 Objects: Recognition: Retrieval Babenko, A., & Lempitsky, V. (2015). Aggregating local deep features for image retrieval. ICCV 2015 Tolias, G., Sicre, R., & Jégou, H. (2015). Particular object retrieval with integral max-pooling of CNN activations. ICLR 2015 Kalantidis, Y., Mellina, C., & Osindero, S. (2015). Cross-dimensional Weighting for Aggregated Deep Convolutional Features. arXiv preprint arXiv:1512.04065. Convolutional Neural Networks sum/max pooled conv features as global representation
- 91. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 91 Objects: Recognition: Retrieval Ng, J., Yang, F., & Davis, L. (2015). Exploiting local features from deep networks for image retrieval. In DeepVision CVPRW 2015 Convolutional Neural Networks conv features encoded with VLAD as global representation
- 92. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 92 Objects: Recognition: Retrieval
- 93. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 93 Objects: Recognition: Retrieval (336x256) Resolution conv5_1 from VGG16[1] (42x32) 25K centroids 25K-D vector
- 94. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 94 Objects: Recognition: Retrieval Query Representation ... ... ... ... ... ... Global Search (GS) Local Search (LS)
- 95. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 95 Objects: Recognition: Retrieval
- 96. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in four parts 96 Detection Recognition Local analysis for... Segmentation person bag me my bag person bag Proposals
- 97. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation 97 Slide credit: Eduard Fontdevila Semantic segmentation: assign a category label to all pixels in an image
- 98. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 98 Farabet, Clement, Camille Couprie, Laurent Najman, and Yann LeCun. "Learning hierarchical features for scene labeling." TPAMI 2013
- 99. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 99 Pyramid of three spatial scales.
- 100. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 100 The same parameters in the three convnets theta_i=theta_0=filters weights (H_l) and biases b_l) Non-linear: tanh Pooling: max
- 101. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 101 Upsampling and concatenation.
- 102. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 102 Pixel-wise soft-max classifier
- 103. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 103 Problem: No spatial consistency among labels 3 explored solutions: 1) Superpixels 2) Conditional Random Fields 3) Parameter-free multilevel parsing
- 104. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 104 Prediction with a 2-layer network Solution 1: Superpixels
- 105. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 105 Prediction with a 2-layer network Solution 2: Superpixels + CRF
- 106. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 106 Solution 3: Multi-level parsing Problems with Solutions 1 & 2: Observation level. BPT [Garrido, Salembier]
- 107. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 107 Solution 3: Multi-level parsing Problems with Solutions 1 & 2: Observation level. Contribution: Automatically discover the best observation level (optimal cover) for each pixel in the image.
- 108. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: Farabet 108 Solution 3: Multi-level parsing Problems with Solutions 1 & 2: Observation level. Contribution: Automatically discover the best observation level (optimal cover) for each pixel in the image. C2 will be labelled with the class of C5 For each pixel (leaf) i, the optimal component is the C_i is the one along the path between the leaf and the root with minimal cost S.
- 109. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 109 Slide credit: Eduard Fontdevila Hariharan, Arbelaez, Girshick, Malik, Simultaneous Detection and Segmentation (ECCV 2014)
- 110. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 110 Slide credit: Eduard Fontdevila ● Interest in obtaining segments, not just bounding boxes ● Multiscale combinational grouping (MCG) to generate object candidates ○ Cuts algorithm ○ Hierarchical segmenter ○ Grouping strategy to combine multiscale regions
- 111. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 111 Slide credit: Eduard Fontdevila BBOX CNN feature vector 1 feature vector 2 [1 2] *Finetuned to classify bboxes (with background), so extracting features from the region foreground is suboptimal BBOX CNN* vector A background masked out with the mean image
- 112. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 112 Slide credit: Eduard Fontdevila ● Training: 2 networks trained in isolation ● Testing: results are combined BBOX CNN feature vector 1 feature vector 2 [1 2] REGION CNN vector B
- 113. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 113 Slide credit: Eduard Fontdevila ● Training: as a whole (using segmentation overlap) ● Testing: results are combined (using the output of the penultimate layer) vector C
- 114. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 114 Slide credit: Eduard Fontdevila penultimate fully connected layer SVM
- 115. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 115 Slide credit: Eduard Fontdevila
- 116. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 116 Slide credit: Eduard Fontdevila ● Results on pixel IU (Jaccard index) to evaluate semantic segmentation: ○ Convert the output of the final system (C+ref) into a pixel-level category labeling (using pasting scheme, Carreira et al)
- 117. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) Objects: Segmentation: SDS 117 Slide credit: Eduard Fontdevila
- 118. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) One lecture organized in four parts 118 Detection Recognition Local analysis for... Segmentation person bag me my bag person bag Proposals
- 119. Xavier Giró i Nieto, “Deep learning for vision: Objects”. Master in Multimedia, La Salle URL (May 2016) 119 Thank you ! https://imatge.upc.edu/web/people/xavier-giro https://twitter.com/DocXavi https://www.facebook.com/ProfessorXavi [email protected] Xavier Giró-i-Nieto