Deep learning on yarn running distributed tensorflow etc on hadoop cluster v3

Deep learning is useful for enterprises tasks in the field of speech recognition, image classification, AI chatbots, and machine translation, just to name a few. In order to train deep learning/machine learning models, applications such as TensorFlow, MXNet, Caffe, and XGBoost can be leveraged. And sometimes these applications will be used together to solve different problems. To make distributed deep learning/machine learning applications easily launched, managed, and monitored, we introduced, in Apache Hadoop 3.x, YARN native services along with other improvements such as first-class GPU support, container-DNS support, scheduling improvements, etc. These improvements make distributed deep learning/machine learning applications run on YARN as simple as running it locally, which can let machine learning engineers focus on algorithms instead of worrying about underlying infrastructure. Also, YARN can better manage a shared cluster which runs deep learning/machine learning and other services and ETL jobs with these improvements. In this session, we will take a closer look at these improvements and show how to run these applications on YARN with demos. Audiences can start trying running these applications on YARN after this talk. Speakers Wanga Tan, Staff Software Engineer, Hortonworks Sunil Govindan, Staff Engineer, Hortonworks

























































More Related Content
What's hot (20)
Similar to Deep learning on yarn running distributed tensorflow etc on hadoop cluster v3 (20)
![[Hadoop Meetup] Tensorflow on Apache Hadoop YARN - Sunil Govindan](https://cdn.slidesharecdn.com/ss_thumbnails/tensorflowonapachehadoopyarn-sunil-171222071922-thumbnail.jpg?width=560&fit=bounds)

















More from DataWorks Summit (20)



















Recently uploaded (20)




















Deep learning on yarn running distributed tensorflow etc on hadoop cluster v3
- 1. Wangda Tan (Hadoop PMC member @Hortonworks) Sunil Govind (Hadoop PMC member @Hortonworks) Deep learning on YARN: running Tensorflow , etc. on Hadoop clusters
- 2. 2 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Agenda Machine Learning Basic Machine Learning In Production How YARN Helps Example: Running distributed Tensorflow on YARN
- 3. 3 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Machine learning basics
- 4. 4 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Basics: Machine Learning Cat Classifier Cats Labeled data (Training) Non-Cats Feed Save Predict Cat (80%) Non-Cat (20%) Model
- 5. 5 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Basics: Model Training Model Training Model Evaluation Model Validation Model Staging Model Training Traditional machine learning models – Logistic Regression – Gradient boosting tree – Recommendation/ALS – LDA Libraries – Apache Spark MLlib – XGBoost Deep learning models – DNN – CNN – RNN – LSTM Libraries – TensorFlow – Apache MXNet – PyTorch
- 6. 6 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Basics: Why GPU? GPU: Many cores to handle massive (but simple) computation tasks simultaneously: GPU CPU GPU Computation Intensive Other Without GPU support, researchers/engineers are almost impossible to wait job finish.
- 7. 7 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Machine learning in production
- 8. 8 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Machine Learning in tutorial $ nvidia-docker run -it -p 8888:8888 tensorflow/tensorflow:latest-gpu Go to your browser on http://localhost:8888/
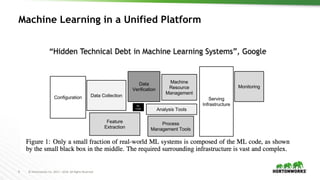
- 9. 9 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Machine Learning in a Unified Platform “Hidden Technical Debt in Machine Learning Systems”, Google
- 10. 10 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Training Hierarchical Models Word Embedding Model Food picture classifier Model Ensemble Model "Burger is great. however onion rings were over cooked" (Image/Photo from Yelp)
- 11. 11 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Data pipelines for Machine Learning (Big Data) ETLData Exploration Join / Sampling / Feature Extraction Split train, test Data set, etc.
- 12. 12 © Hortonworks Inc. 2011 – 2016. All Rights Reserved How YARN helps
- 13. 13 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Running on YARN: All about data and sharing Hadoop YARN HDFS AWS S3 RDBMS Spark MLlib XGBoost TensorFlow Zeppelin / Jupyter Hive/LLAP Spark SQL CPU GPU SSD
- 14. 14 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Why all under YARN SLA! Monitoring! A normal cluster user Quotas! Isolation! Capacity Planning, Preemption, Reservation System. Time time services, Grafana, etc. Queues / Users quota, user access control. CPU / Memory / GPU / FPGA, (WIP) Network/Disk YARN
- 15. 15 © Hortonworks Inc. 2011 – 2016. All Rights Reserved All running on the same YARN platform LLAP 128 G 128 G 128 G 128 G 128 G LLAP LLAP 128 G 128 G GPUs
- 16. 16 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Recent works in YARN to support ML workloads like Tensorflow GPU isolation/scheduling support Native Service - Easy to define and run any custom service All above works available in Apache Hadoop 3.1.0
- 17. 17 © Hortonworks Inc. 2011 – 2016. All Rights Reserved GPU support on YARN (Apache Hadoop 3.1.0) Why need isolation? – Multiple processes use the single GPU will be: • Serialized. • Cause OOM easily. GPU isolation on YARN: . – Granularity is for per-GPU device. – Use Cgroups / docker to enforce the isolation.
- 18. 18 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Docker + GPU support on YARN (Apache Hadoop 3.1.0) Most of machine learning platforms has python/R/cudnn/CUDA dependencies. Docker solves messy dependencies issues – But it may introduce problems for GPU base libraries Nvidia-docker-plugin mounts Nvidia driver, etc. when container got launched. YARN supports Docker and as well as nvidia-docker-plugin. Tensorflow 1.2 Nginx AppUbuntu 14:04 Nginx AppHost OS GPU Base Lib v1 Volume Mount CUDA Library 5.0 Tensorflow 1.2 Nginx AppUbuntu 14:04 GPU Base Lib v2 Nginx AppHost OS GPU Base Lib v1 X Fails CUDA Library 5.0
- 19. 19 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Running Distributed Tensorflow on YARN
- 20. 20 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Why distributed? Reference: https://www.tensorflow.org/performance/benchmarks
- 21. 21 © Hortonworks Inc. 2011 – 2016. All Rights Reserved How Distributed TF Works? Distributed TF architecture How to make it work? – Set following environment: TF_CONFIG
- 22. 22 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Using YARN to run distributed Tensorflow What you need to do: – Write YARN service spec with proper TF_CONFIG in parameter. – Run the job by using: – yarn app -launch ${SERVICE_NAME} ${PATH_TO_SERVICE_SPEC} What happened under the hood
- 23. 23 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Write service spec to run distributed Tensorflow
- 24. 24 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Write service spec to serve Tensorflow model Note: – Uses simple_tensorflow_serving (github.com/tobegit3hub/simple_tensorflow_serving) – http://serving.serving-job-001.<domain-name>:port to access serving REST end point – Still feel complicated? We’re working on wrapper to simply this!
- 25. 25 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Write service spec to run MXNet – Fine-tune model. Note: – Fine-tune refers training with parameters partially initialized with pre-trained model. – Prepare caltech256 dataset first, then fine tune it with imagenet11k-resnet-152 – YARN Native Service’s dependencies feature helps to run the prepare component first and once its completed, real training is started on the prepared dataset.
- 26. 26 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Accelerating XGBoost applications with GPU and Spark https://dataworkssummit.com/berlin-2018/session/accelerating-xgboost-applications-with-gpu- and-spark/ 2:50 PM, Room I, Wed April 18th -- Related Session -- Yanbo Liang & Mingjie Tang
- 27. 27 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Demo
- 28. 28 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Questions?
Editor's Notes
- #6: Model training is the most important step of the whole pipeline.
- #9: Just like the workflow shows, only a tiny fraction of the code is actually devoted to model learning. The machine learning workflow usually need lots of supports from the big data platform, such as data collection from different data sources, feature extraction, feature transform, and so on. Let’s find out how big data infrastructure could help machine learning step by step.
- #10: Just like the workflow shows, only a tiny fraction of the code is actually devoted to model learning. The machine learning workflow usually need lots of supports from the big data platform, such as data collection from different data sources, feature extraction, feature transform, and so on. Let’s find out how big data infrastructure could help machine learning step by step.
- #11: To Do:
- #12: ToDo Add Ooozie/Azkaban to control the workflow
- #18: Even though TF provide options to use GPU memory less than whole device provided. But we cannot enforce this from external.
- #19: Even though TF provide options to use GPU memory less than whole device provided. But we cannot enforce this from external.