Deep Learning Tutorial
Download as PPTX, PDF14 likes5,897 views

See hints, Ref under each slide Deep Learning tutorial https://www.youtube.com/watch?v=q4rZ9ujp3bw&list=PLAI6JViu7XmflH_eGgsWkwvv6lbXhYjjY


























































![2016 LSVRC winner(CUImage team)
0 Compared with CUImage submission in ILSVRC 2015, the new components are as follows.
(1) The models are pretrained for 1000-class object detection task using the approach in [a] but adapted to
the fast-RCNN for faster detection speed.
(2) The region proposal is obtained using the improved version of CRAFT in [b].
(3) A GBD network [c] with 269 layers is fine-tuned on 200 detection classes with the gated bidirectional
network (GBD-Net), which passes messages between features from different support regions during both
feature learning and feature extraction. The GBD-Net is found to bring ~3% mAP improvement on the
baseline 269 model and ~5% mAP improvement on the Batch normalized GoogleNet.
(4) For handling their long-tail distribution problem, the 200 classes are clustered. Different from the
original implementation in [d] that learns several models, a single model is learned, where different
clusters have both shared and distinguished feature representations.
(5) Ensemble of the models using the approaches mentioned above lead to the final result in the provided
data track.
(6) For the external data track, we propose object detection with landmarks. Comparing to the standard
bounding box centric approach, our landmark centric approach provides more structural information and
can be used to improve both the localization and classification step in object detection. Based on the
landmark annotations provided in [e], we annotate 862 landmarks from 200 categories on the training set.
Then we use them to train a CNN regressor to predict landmark position and visibility of each proposal in
testing images. In the classification step, we use the landmark pooling on top of the fully convolutional
network, where features around each landmark are mapped to be a confidence score of the corresponding
category. The landmark level classification can be naturally combined with standard bounding box level
classification to get the final detection result.
(7) Ensemble of the models using the approaches mentioned above lead to the final result in the external
data track. The fastest publicly available multi-GPU caffe code is our strong support [f].](https://image.slidesharecdn.com/deeplearningtutorial-180118100742/85/Deep-Learning-Tutorial-60-320.jpg)
![2017 LSVRC winner(BDAT team)
0 Adaptive attention[1] and deep combined convolutional
models[2,3] are used for LOC task.
0 Deep residual learning for image recognition.
0 Scale[4,5,6], context[7], sampling and deep combined
convolutional networks[2,3] are considered for DET task.
0 Object density estimation is used for score re-rank](https://image.slidesharecdn.com/deeplearningtutorial-180118100742/85/Deep-Learning-Tutorial-61-320.jpg)






















































Ad
More Related Content
What's hot (20)
Similar to Deep Learning Tutorial (20)


















Ad
More from Amr Rashed (19)



















Ad
Recently uploaded (20)




















Deep Learning Tutorial
- 2. Deep Learning DEEP LEANING in Bioinformatics, Conclusion RECURRENT NN,DEEP LEARNING TOOLS Types of Networks , Convolution Neural Networks DEEP NN ARCHITECTURE, PROBLEM SPACE WHAT IS DEEP LEARNING, DEEP LEARNING BASICS BIG PLAYERS, APPLICATIONS A Brief History, MACHINE LEARNING BASICS MOTIVATIONS, WHY DEEP NN AGENDA
- 3. Motivations I have worked all my life in machine learning, and I’ve never seen one algorithm knock over benchmarks like deep learning . Andrew Ng(Stanford & Baidu) Deep learning is an algorithm which has no theoretical limitations of what it can learn ;the more data you give and the more computational time you provide ;the better it is-Geoffrey Hilton(Google) Human-level artificial intelligence has the potential to help humanity thrive more than any invention that has come before it –Dileep George(Co-Founder Vicarious) For a very long time it will be a complementary tool that human scientists and human experts can use to help them with the things that humans are not naturally good- Demis Hassabis (Co-Founder Deep Mind)
- 5. Motivations NIPS(Computational Neuroscience Conference) Growth Amount of Data vs Performance
- 6. The Problem Space 0 Image classification is the task of taking an input image and outputting a class (a cat, dog, etc) or a probability of classes that best describes the image. 0 For humans, this task of recognition is one of the first skills we learn from the moment we are born . 0 Without even thinking twice, we’re able to quickly and seamlessly identify the environment and objects that surround us. 0 When we see an image we are able to immediately characterize the scene and give each object a label, all without even consciously noticing. 0 These skills of being able to quickly recognize patterns, generalize from prior knowledge, and adapt to different image environments are ones that we do not share with our fellow machines.
- 7. The Problem Space : inputs & outputs 0 Depending on the resolution and size of the image, it will see a 32 x 32 x 3 array of numbers 0 These numbers, while meaningless to us when we perform image classification, are the only inputs available to the computer. 0 The idea is that you give the computer this array of numbers and it will output numbers that describe the probability of the image being a certain class (.80 for cat, .15 for dog, .05 for bird, etc).
- 8. The Problem Space :What We Want the Computer to Do 0 To be able to differentiate between all the images it’s given and figure out the unique features that make a dog a dog or that make a cat a cat. 0 This is the process that goes on in our minds subconsciously as well. 0 When we look at a picture of a dog, we can classify it as such if the picture has identifiable features such as paws or 4 legs. 0 In a similar way, the computer is able perform image classification by looking for low level features such as edges and curves, and then building up to more abstract concepts through a series of convolutional layers.
- 9. Why Deep Neural Network - Imagine you have extracted features from sensors . - The dimension of each sample is around 800 - You have 70,000 samples (trial) - What method would you apply? - You may have several ways to do it 0 Reduce the dimension from 800 to 40 by using a feature selection or dim. reduction technique 0 What you did here is “Finding a good representation” 0 - Then, you may apply a classification methods to classify 10 classes But, what if - You have no idea for feature selection? - The dimension is much higher than 800 and you have more classes.
- 10. Why Deep Neural Network 0 Drawbacks -Back-Propagation: 0 Scalability -does not scale well over multiple layers. 0 very slow to converge. 0“Vanishing gradient problem “ errors shrink exponentially with the number of layers 0Thus makes poor use of many layers. 0This is the reason most feed forward NN have only three layers. 0 It got stuck at local optima 0 When the network outputs have not got their desired signals, the activation functions in the hidden layer are saturating. 0These were often surprisingly good but there was no good theory. 0 Traditional Machine Learning doesn’t work well when features can’t be explicitly defined.
- 11. A Brief History 0 2012 was the first year that neural nets grew to prominence as Alex Krizhevsky used them to win that year’s ImageNet competition (basically, the annual Olympics of computer vision), dropping the classification error record from 26% to 15%, an astounding improvement at the time.
- 12. Machine Learning –Basics Introduction Machine Learning is a type of Artificial Intelligence that provides computers with the ability to learn without being explicitly programmed. Provides various techniques that can learn from and make predictions on data.
- 13. Supervised Learning : Learning with a labeled training set Example : e-mail spam detector with training set of already labeled emails Unsupervised Learning :Discovering patterns in unlabeled data Example :cluster similar documents based on the text content Reinforcement learning : learning based on feedback or reward. Example :learn to play chess by wining or losing Machine Learning –Basics Learning Approach
- 14. Machine Learning –Basics Problem Types
- 15. Big Players :Superstar Researcher Jeoferry Hilton : University of Toronto &Google Yann Lecun : New Yourk University &Facebook Andrew Ng : Stanford & Baidu Yoshua Bengio : University of Montreal Jurgen schmidhuber : Swiss AI Lab & NNAISENSE
- 16. Big Players : Companies
- 17. Deep Learning : Applications
- 18. Google Application 0 What are some ways that deep learning is having a significant impact at Google?
- 19. Google Application –Sunroof Project
- 20. What is Deep Learning(DL) Part or a powerful class of the machine learning field of learning representations of data. Exceptional effective at learning patterns. Utilize learning algorithms that derive meaning out of data by using hierarchy of multiple layers that mimic the neural networks of our brain. If you provide the system tons of information , it begins to understand it and respond in useful ways. Stacked “Neural Network”. Is usually indicates “Deep Neural Network”.
- 21. What is Deep Learning (DL) • Collection of simple, trainable mathematical functions. • Learning methods which have deep architecture. • It often allows end-to-end learning. • It automatically finds intermediate representation. Thus, it can be regarded as a representation learning.
- 22. Deep Learning Basics :Neuron An artificial neuron contains a nonlinear activation function and has several incoming and outgoing weighted connections. Neurons are trained filters and detect specific features or patterns (e.g. edge, nose) by receiving weighted input, transforming it with the activation function and passing it to the outgoing connections
- 23. Commonalities with real brains: ● Each neuron is connected to a small subset of other neurons. ● Based on what it sees, it decides what it wants to say. ● Neurons learn to cooperate to accomplish the task. • The vental pathway in the visual cortex has multiple stages • There exist a lot of intermediate representations Deep Learning Basics :Neuron
- 24. Deep Learning Basics :Training process Learns by generating an error signal that measures the difference between the predictions of the network and the desired values and then using this error signal to change the weights (or parameters) so the predictions get more accurate.
- 25. Deep Learning Basics :Gradient Descent Gradient Descent/optimization finds the (local)the minimum of the cost function(used to calculate the output error) and is used to adjust the weights. Curve represents is the network's error relative to the position of a single weight. X axis weight Y axiserror Oversimplified Gradient Descent: Calculate slope at current position • If slope is negative, move right • If slope is positive, move left • (Repeat until slope == 0)
- 26. Deep Learning Basics :Gradient Descent Problems Problem 1: When slopes are too big Solution 1: Make Slopes Smaller Problem 2: Local Minimums-Solution 2: Multiple Random Starting States
- 27. Deep Neural Network :Architecture A Deep Neural Network consists of a hierarchy of layers, whereby each layer transforms the input data into more abstract representations (e.g edge - >nose -> face). The output layer combines those features to make predictions.
- 28. Deep Neural Network :Architecture Consists of one input ,one output and multiple fully-connected hidden layers in between. Each layer is represented as a series of neurons and progressively extracts higher and higher-level features of the input until the final layer essentially makes a decision about what the input shows. The more layer the network has, the higher-level features it will learn.
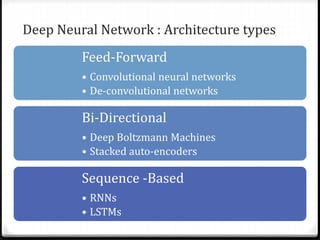
- 29. Deep Neural Network : Architecture types Feed-Forward • Convolutional neural networks • De-convolutional networks Bi-Directional • Deep Boltzmann Machines • Stacked auto-encoders Sequence -Based • RNNs • LSTMs
- 30. Types of Networks used for Deep Learning Convolutional Neural Networks(Convnet,CNN) Recurrent Neural Networks(RNN) Long Short Term Memory (LSTM) networks Deep/Restricted Boltzmann Machines (RBM) Deep Q-networks Deep Belief Networks(DBN) Deep Stacking Networks
- 31. Convolution Neural Networks(CNN):Basic Idea 0 This idea was expanded upon by a fascinating experiment by Hubel and Wiesel in 1962 where they showed that some individual neuronal cells in the brain responded (or fired) only in the presence of edges of a certain orientation. 0 For example, some neurons fired when exposed to vertical edges and some when shown horizontal or diagonal edges. Hubel and Wiesel found out that all of these neurons were organized in a columnar architecture and that together, they were able to produce visual perception. 0 This idea of specialized components inside of a system having specific tasks (the neuronal cells in the visual cortex looking for specific characteristics) is one that machines use as well, and is the basis behind CNNs.
- 32. Convolution Neural Networks(CNN) • Convolutional neural networks learn a complex representation of visual data using vast amounts of data .they are inspired by human visual system and learn multiple layers of transformations , which are applied on top of each other to extract progressively more sophisticated representation of the input . DEFENITION • Inspired by the visual cortex and Pioneered by Yann Lecun (NYU). • CNN have multiple types of layers ,the first of which is the Convolutional layer. Notes
- 33. CNN Layers 1 • Convolution Layer 2 • Batch Normalization Layer 3 • RELU Layer 4 • Local Response Normalization Layer 5 • Max and AVG Pooling 6 • Dropout Layer 7 • Fully Connected Layer (FC) 8 • Output Layer (SOFT MAX ,Regression )
- 34. CNN Structure :First Layer – Convolution Convolution layer is a feature detector that auto magically learns to filter out not needed information from an input by using convolution kernel.
- 35. CNN Structure :First Layer – Convolution
- 36. Stride and Padding Stride set to 1 Stride set to 2
- 37. Examples of Actual Visualizations End-to-End Learning A pipeline of successive Layers • Layers produce features of higher and higher abstractions – Initial Layer capture low-level features (e.g. edges or corners) – Middle Layer capture mid-level features (object parts e.g. circles, squares, textures) – Last Layer capture high level, class specific features (object model e.g. face detector) • Preferably, input as raw as possible – Pixels for computer vision, words for NLP.
- 38. Batch Normalization Layer 0 Batch Normalization is a technique to provide any layer in a Neural Network with inputs that are zero mean/unit variance . 0 Use batch normalization layers between convolutional layers and nonlinearities such as ReLU layers to speed up network training and reduce the sensitivity to network initialization. 0 The layer first normalizes the activations of each channel by subtracting the mini-batch mean and dividing by the mini-batch standard deviation. Then, the layer shifts the input by an offset β and scales it by a scale factor γ. β and γ are themselves learnable parameters that are updated during network training.
- 39. Nonlinear Activation Function(Relu) •Rectified Linear Unit (ReLU) module . •Activation function 𝑎=ℎ(𝑥)=max(0,𝑥). Most deep networks use ReLU –max(0,x)-nowadays for hidden layers ,since it trains much faster ,is more expressive than logistic function and prevents the gradient vanishing problem. Non-linearity is needed to learn complex (non linear)representations of data ,otherwise the NN would be just a linear function .
- 40. Vanishing Gradient Problem 0 It is a difficulty founds in training ANN with gradient-based learning methods and backpropagation. 0 In such methods, each of the neural network's weights receives an update proportional to the gradient of the error function with respect to the current weight in each iteration of training. 0 Traditional activation functions such as the hyperbolic tangent function have gradients in the range (−1, 1), and backpropagation computes gradients by the chain rule. 0 This has the effect of multiplying n of these small numbers to compute gradients of the "front" layers in an n-layer network. 0 This means that the gradient (error signal) decreases exponentially with n while the front layers train very slowly.
- 41. Local Response Normalization Layer 0 we want to have some kind of inhibition scheme. 0 Neurobiology concept “lateral inhibition”. 0 Useful when we are dealing with ReLU neurons(unbounded activations ). 0 Detect high frequency features with a large response. 0 If we normalize around the local neighborhood of the excited neuron, it becomes even more sensitive as compared to its neighbors. 0 Inhibit the responses that are uniformly large in any given local neighborhood. 0 If all the values are large, then normalizing those values will decrease all of them. 0 Inhibition and boost the neurons with relatively larger activations. 0 Two types of normalizations available in Caffe (same and cross channel) where K, α, and β are the hyperparameters in the normalization, and ss is the sum of squares of the elements in the normalization window.
- 42. Max and AVG Pooling Layer 0 Pooling layers compute the max or average value of a particular feature over a region of the input data (downsizing of input images). 0 Also helps to detect objects in some unusual places and reduces memory size. 0 Aggregate multiple values into a single value 0 – Reduces the size of the layer output/input to next layer ->Faster computations 0 – Keeps most important information for the next layer 0 • Max pooling/Average pooling
- 43. Over Fitting 0 Over Fitting. This term refers to when a model is so tuned to the training examples that it is not able to generalize well for the validation and test sets. 0 A symptom of over Fitting is having a model that gets 100% or 99% on the training set, but only 50% on the test data. 0 Implement dropout layers in order to combat the problem of over fitting to the training data.
- 44. Dropout Layers 0 after training, the weights of the network are so tuned to the training examples they are given that the network doesn’t perform well when given new examples. 0 The idea of dropout is simplistic in nature. This layer “drops out” a random set of activations in that layer by setting them to zero. Simple as that. 0 Benefits 0 it forces the network to be redundant. By that the network should be able to provide the right classification or output for a specific example even if some of the activations are dropped out. 0 It makes sure that the network isn’t getting too “fitted” to the training data and thus helps alleviate the over fitting problem. 0 An important note is that this layer is only used during training, and not during test time.
- 45. Output Layer –Soft-max Activation Function 0 For classification problems the sigmoid function can only handle two classes, which is not what we expect. 0 The softmax function squashes the outputs of each unit to be between 0 and 1, just like a sigmoid function. 0 But it also divides each output such that the total sum of the outputs is equal to 1 . 0 The output of the softmax function is equivalent to a categorical probability distribution, it tells you the probability that any of the classes are true.
- 46. Output Layer –Regression 0 You can also use ConvNets for regression problems, where the target (output) variable is continuous. 0 In such cases, a regression output layer must follow the final fully connected layer. You can create a regression layer using the regressionLayer function. 0 The default loss function for a regression layer is the mean squared error. 0 where ti is the target output, and yi is the network’s prediction for the response variable corresponding to observation i.
- 47. Transfer Learning 0 Transfer learning is the process of taking a pre-trained model (the weights and parameters of a network that has been trained on a large dataset by somebody else) and “fine-tuning” the model with your own dataset. 0 Pre-trained model will act as a feature extractor. 0 Freeze the weights of all the other layers . 0 Remove the last layer of the network and replace it with your own classifier. 0 Train the network normally.
- 48. Cont.:Transfer Learning • Transfer from A (image recognition) to B (radiology images) • When transfer learning makes sense 1. Task A and B have same input X. 2. You have a lot more data for Task A than Task B. 3. Low level features from A could be helpful for learning B. 4. Weights initialization. • When transfer learning doesn’t makes sense 1. You have a lot more data for Task B than Task A.
- 49. Data Augmentation Techniques 0 Approaches that alter the training data in ways that change the array representation while keeping the label the same. 0 They are a way to artificially expand your dataset. Some popular augmentations people use are gray scales , horizontal flips, vertical flips, random crops, color jitters, translations, rotations, and much more . ZCA Whitening Random Rotations Random shift Random flipExample MNIST images
- 50. Recurrent Neural Network (RNN) RNNs are general computers which can learn algorithms to map input sequences to output sequences (flexible –sized vectors). The output vector’s contents influenced by the entire history of input. Applications • In time series prediction , adaptive robotics, handwriting recognition ,image classification, speech recognition, stock market prediction, and other sequence learning problems .every thing can be processed sequentially
- 52. What changed Imagenet ,youtube-8M ,AWS public dataset, Baidu’s Chinese speech recognition
- 53. Usage Requirements Large data set with good quality (input –output mapping) Measurable and describable goals (define the cost) Enough computing power(AWS GPU Instance) Excels in tasks where the basic unit (pixel, word) has very little meaning in itself, but the combination of such units has a useful meaning.
- 54. Deep Learning : Benefits Robust • No need to design the features ahead of time –features are automatically learned to be optimal for the task at hand • Robustness to natural variations in the data is automatically learned Generalizable • The same neural network approach can be used for many different applications and data types Scalable • Performance improves with more data ,method is massively parallelizable
- 55. Deep Learning: Weakness 1 • Deep learning requires a large dataset, hence long training period. 2 • In term of cost, Machine learning methods like SVM and other tree ensembles are very easily deployed even by relative machine learning novices and can usually get you reasonably good results 3 • Deep learning methods tends to learn everything. It’s better to encode prior knowledge about structure of images (or audio or text). 4 • The learned features are often difficult to understand. Many vision features are also not really human-understandable (e.g, concatenations/combinations of different features). 5 • Requires a good understanding of how to model multiple modalities with traditional tools.
- 56. Pre-trained Deep Learning models • Authors :Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton • Winner 2012. • Trained the network on ImageNet data, which contained over 15 million • used for classification with 1000 possible categories • Use 11x11 sized filters in the first layer. • Used ReLU for the nonlinearity functions . • Used data augmentation techniques that consisted of image translations, horizontal reflections, and patch extractions. • Implemented dropout layers. • Trained the model using batch stochastic gradient descent, with specific values for momentum and weight decay. • Trained on two GTX 580 GPUs for five to six days • This model achieved an 15.4% error rate. built by Matthew Zeiler and Rob Fergus from NYU. Winner 2013. Very similar architecture to AlexNet, except for a few minor modifications. ZF Net trained on only 1.3 million images. ZF Net used filters of size 7x7 Used ReLUs for their activation functions, cross-entropy loss for the error function, and trained using batch stochastic gradient descent. Trained on a GTX 580 GPU for twelve days. Developed a visualization technique named Deconvolutional Network, which helps to examine different feature activations and their relation to the input space. Called “deconvnet” because it maps features to pixels (the opposite of what a convolutional layer does). This model achieved an 11.2% error rate AlexNet (2012) ZF Net (2013)
- 57. Pre-trained Deep Learning models • Built by Karen Simonyan and Andrew Zisserman of the University of Oxford • Not a winner . • 19 layer CNN , used 3x3 sized filters with stride and pad of 1 , 2x2 max pooling layers with stride 2. • The combination of two 3x3 conv layers has an effective receptive field of 5x5. • Decrease in the number of parameters. • Also, with two conv layers, we’re able to use two ReLU layers instead of one. 3 conv layers back to back have an effective receptive field of 7x7. • Interesting to notice that the number of filters doubles after each max pool layer. This reinforces the idea of shrinking spatial dimensions, but growing depth. • Worked well on both image classification and localization tasks. • used a form of localization as regression Built model with the Caffe toolbox. • Used scale jittering as one data augmentation technique during training. • Used ReLU layers after each conv layer and trained with batch gradient descent. • Trained on 4 Nvidia Titan Black GPUs for two to three weeks. • This achieved an 7.3% error rate • GoogLeNet is a 22 layer CNN. • Winner 2014 • Used 9 Inception modules in the whole architecture, with over 100 layers in total. • No use of fully connected layers! They use an average pool instead, to go from a 7x7x1024 volume to a 1x1x1024 volume. • Uses 12x fewer parameters than AlexNet. • During testing, multiple crops of the same image were created, fed into the network, and the softmax probabilities were averaged to give us the final solution. • Utilized concepts from R-CNN for their detection model. • This model places notable consideration on memory and power usage • Trained on “a few high-end GPUs within a week”. • This achieved an 6.7% error rate VGG Net (2014) Google Net (2015)
- 58. Google Net :Inception Module
- 59. Pre-trained Deep Learning models Microsoft ResNet (2015) input x go through conv-relu-conv series. 152 layer, “Ultra-deep” – Yann LeCun. Winner 2015. After only the first 2 layers, the spatial size gets compressed from an input volume of 224x224 to a 56x56 volume. increase of layers in plain nets result in higher training and test error (author claims). The authors believe that “it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping The group tried a 1202-layer network, but got a lower test accuracy, presumably due to over-fitting. Trained on an 8 GPU machine for two to three weeks. Achieved an 3.6 % error rate.
- 60. 2016 LSVRC winner(CUImage team) 0 Compared with CUImage submission in ILSVRC 2015, the new components are as follows. (1) The models are pretrained for 1000-class object detection task using the approach in [a] but adapted to the fast-RCNN for faster detection speed. (2) The region proposal is obtained using the improved version of CRAFT in [b]. (3) A GBD network [c] with 269 layers is fine-tuned on 200 detection classes with the gated bidirectional network (GBD-Net), which passes messages between features from different support regions during both feature learning and feature extraction. The GBD-Net is found to bring ~3% mAP improvement on the baseline 269 model and ~5% mAP improvement on the Batch normalized GoogleNet. (4) For handling their long-tail distribution problem, the 200 classes are clustered. Different from the original implementation in [d] that learns several models, a single model is learned, where different clusters have both shared and distinguished feature representations. (5) Ensemble of the models using the approaches mentioned above lead to the final result in the provided data track. (6) For the external data track, we propose object detection with landmarks. Comparing to the standard bounding box centric approach, our landmark centric approach provides more structural information and can be used to improve both the localization and classification step in object detection. Based on the landmark annotations provided in [e], we annotate 862 landmarks from 200 categories on the training set. Then we use them to train a CNN regressor to predict landmark position and visibility of each proposal in testing images. In the classification step, we use the landmark pooling on top of the fully convolutional network, where features around each landmark are mapped to be a confidence score of the corresponding category. The landmark level classification can be naturally combined with standard bounding box level classification to get the final detection result. (7) Ensemble of the models using the approaches mentioned above lead to the final result in the external data track. The fastest publicly available multi-GPU caffe code is our strong support [f].
- 61. 2017 LSVRC winner(BDAT team) 0 Adaptive attention[1] and deep combined convolutional models[2,3] are used for LOC task. 0 Deep residual learning for image recognition. 0 Scale[4,5,6], context[7], sampling and deep combined convolutional networks[2,3] are considered for DET task. 0 Object density estimation is used for score re-rank
- 62. Object Recognition 0 Problem: Where do we look in the image for the object?
- 63. Solution 1:Exhaustively search for objects. 0 Problem: Extremely slow, must process tens of thousands of candidate objects.
- 64. Solution 2: Running a scanning detector is cheaper than running a recognizer, so do that first. 1. Exhaustively search for candidate objects with a generic detector. 2. Run recognition algorithm only on candidate objects. Problem: What about oddly-shaped objects? Will we need to scan with windows of many different shapes?
- 65. Segmentation 0 Idea: If we correctly segment the image before running object recognition, we can use our segmentations as candidate objects. 0 Advantages: Can be efficient, makes no assumptions about object sizes or shapes.
- 66. Segmentation is Hard 0 As we saw in Project 1, it’s not always clear what separates an object.
- 67. Segmentation is Hard 0 As we saw in Project 1, it’s not always clear what separates an object.
- 68. Selective Search Goals: 1. Detect objects at any scale. a. Hierarchical algorithms are good at this. 2. Consider multiple grouping criteria. a. Detect differences in color, texture, brightness, etc. 3. Be fast. Idea: Use bottom-up grouping of image regions to generate a hierarchy of small to large regions.
- 69. Selective Search Step 1: Generate initial sub-segmentation Goal: Generate many regions, each of which belongs to at most one object. Using the method described by Felzenszwalb et al. from week 1 works well.
- 70. Selective Search Step 2: Recursively combine similar regions into larger ones. Greedy algorithm: 1. From set of regions, choose two that are most similar. 2. Combine them into a single, larger region. 3. Repeat until only one region remains. This yields a hierarchy of successively larger regions, just like we want.
- 71. Similarity What do we mean by “similarity”? Goals: 1. Use multiple grouping criteria. 2. Lead to a balanced hierarchy of small to large objects. 3. Be efficient to compute: should be able to quickly combine measurements in two regions. Two-pronged approach: 1. Choose a color space that captures interesting things. a. Different color spaces have different invariants, and different responses to changes in color. 2. Choose a similarity metric for that space that captures everything we’re interested: color, texture, size, and shape.
- 72. Similarity 0 RGB (red, green, blue) is a good baseline, but changes in illumination (shadows, light intensity) affect all three channels.
- 73. Similarity 0 HSV (hue, saturation, value) encodes color information in the hue channel, which is invariant to changes in lighting. Additionally, saturation is insensitive to shadows, and value is insensitive to brightness changes.
- 74. Similarity 0 Lab uses a lightness channel and two color channels (a and b). It’s calibrated to be perceptually uniform. Like HSV, it’s also somewhat invariant to changes in brightness and shadow.
- 76. Fast R-CNN
- 77. Faster R-CNN
- 78. Generative Adversarial Networks 0 According to Yann LeCun, these networks could be the next big development. 0 The idea is to simultaneously train two neural nets. 0 The first one, called the Discriminator D(Y) takes an input (e.g. an image) and outputs a scalar that indicates whether the image Y looks “natural” or not. 0 The second network is called the generator, denoted G(Z), where Z is generally a vector randomly sampled in a simple distribution (e.g. Gaussian). The role of the generator is to produce images so as to train the D(Y) function to take the right shape (low values for real images, higher values for everything else).
- 79. Generative Adversarial Networks : Importance 0 The discriminator now is aware of the “internal representation of the data” because it has been trained to understand the differences between real images from the dataset and artificially created ones. 0 It can be used as a feature extractor for CNN. 0 You can just create really cool artificial images that look pretty natural to me.
- 80. Generating Image Descriptions 0 What happens when you combine CNNs with RNNs. you do get one really amazing application. 0 Combination of CNNs and bidirectional RNNs to generate natural language descriptions of different image regions
- 81. Spatial Transformer Network 0 The basic idea is that this module transforms the input image in a way so that the subsequent layers have an easier time making a classification. 0 The module consists of: 0 A localization network which takes in the input volume and outputs parameters of the spatial transformation that should be applied. 0 The creation of a sampling grid that is the result of warping the regular grid with the affine transformation (theta) created in the localization network. 0 A sampler whose purpose is to perform a warping of the input feature map.
- 82. Spatial Transformer Network 0 This Network implements the simple idea of making affine transformations to the input image in order to help models become more invariant to translation, scale, and rotation.
- 83. Conclusion Significant advances in deep reinforcement and unsupervised learning Bigger and more complex architectures based on various interchangeable modules/techniques Deeper models that can learn from much fewer training cases Harder problems such as video understanding and natural language processing will be successfully tackled by deep learning algorithms
- 84. Conclusion Machines that learn to represent the world from experience Deep learning is no magic ! Just statistics in a black box , but exceptional effective at learning patterns. We haven’t figured out creativity and human- empathy. Transitioning from research to consumer products .will make the tools you use every day work better, faster and smarter
- 85. Online Courses 0 https://www.coursera.org/specializations/deep-learning 0 https://www.youtube.com/watch?v=fTUwdXUFfI8&index=2 &t=895s&list=PLAI6JViu7Xmd_UKcm-_Mnxe1lvQI__qmW 0 https://adeshpande3.github.io/adeshpande3.github.io/The- 9-Deep-Learning-Papers-You-Need-To-Know-About.html
Editor's Notes
- #4: Thrive =flourish
- #7: AlexNet,8 layers(ILSVRC 2012),VGG,19 layers(ILSVRC 2014),GoogleNet,22 layers(ILSVRC 2014) ImageNet Large Scale Visual Recognition (ILSVRC ) https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- #8: A Beginner's Guide To Understanding Convolutional Neural Networks – Adit Deshpande – CS Undergrad at UCLA ('19)
- #9: A Beginner's Guide To Understanding Convolutional Neural Networks – Adit Deshpande – CS Undergrad at UCLA ('19)
- #10: A Beginner's Guide To Understanding Convolutional Neural Networks – Adit Deshpande – CS Undergrad at UCLA ('19) Paw=hand
- #13: Convolutional neural networks. Sounds like a weird combination of biology and math with a little CS sprinkled in, but these networks have been some of the most influential innovations in the field of computer vision.
- #20: Speech Recognition Google Photos Search
- #22: Artificial Intelligence(i.e. knowledge based)-Machine Learning-(i.e. SVM)Representation learning(i.e. auto-encoders)-Deep learning(i.e. MLP)
- #24: .
- #27: if we computed the network's error for every possible value of a single weight, it would generate the curve you see above. We would then pick the value of the single weight that has the lowest error (the lowest part of the curve). I say single weight because it's a two-dimensional plot. Thus, the x dimension is the value of the weight and the y dimension is the neural network's error when the weight is at that position. https://iamtrask.github.io/2015/07/27/python-network-part2/
- #28: Problem 3: When Slopes are Too Small -Solution 3: Increase the Alpha
- #32: Convolutional neural networks(Convnet,CNN) ConvNet has shown outstanding performance in recognition tasks (image, speech,object) ConvNet contains hierarchical abstraction process called pooling. Recurrent neural networks(RNN) RNN is a generative model: It can generate new data. Long Short term memory (LSTM) networks[Hochreiter and Schmidhuber, 1997] RNN+LSTM makes use of long-term memory → Good for time-series data. Deep/Restricted Boltzmann machines (RBM) It helps to avoid local minima problem(It regularizes the training data). But it is not necessary when we have large amount of data.(Drop-out is enough for regularization)
- #33: A Beginner's Guide To Understanding Convolutional Neural Networks – Adit Deshpande – CS Undergrad at UCLA ('19)
- #34: Every layer of a CNN takes a 3D volume of numbers and outputs a 3D volume of numbers.
- #35: https://www.mathworks.com/help/nnet/ug/layers-of-a-convolutional-neural-network.html#mw_ad6f0a9d-9cc7-4e57-9102-0204f1f13e99
- #36: However, let’s talk about what this convolution is actually doing from a high level. Each of these filters can be thought of as feature identifiers. When I say features, I’m talking about things like straight edges, simple colors, and curves. Think about the simplest characteristics that all images have in common with each other. Let’s say our first filter is 7 x 7 x 3 and is going to be a curve detector. (In this section, let’s ignore the fact that the filter is 3 units deep and only consider the top depth slice of the filter and the image, for simplicity.)As a curve detector, the filter will have a pixel structure in which there will be higher numerical values along the area that is a shape of a curve (Remember, these filters that we’re talking about as just numbers!).
- #37: https://www.safaribooksonline.com/library/view/deep-learning/9781491924570/ch04.html
- #39: examples of actual visualizations of the filters of the first conv layer of a trained network. Nonetheless, the main argument remains the same. The filters on the first layer convolve around the input image and “activate” (or compute high values) when the specific feature it is looking for is in the input volume.
- #40: https://www.mathworks.com/help/nnet/ug/layers-of-a-convolutional-neural-network.html#mw_a8ef6ff0-eeab-4af3-9b2a-092908284ee8 https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
- #41: https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks-Part-2/ https://en.wikipedia.org/wiki/Vanishing_gradient_problem https://www.quora.com/What-is-the-vanishing-gradient-problem http://www.cs.toronto.edu/~fritz/absps/reluICML.pdf
- #42: https://en.wikipedia.org/wiki/Vanishing_gradient_problem https://www.quora.com/What-is-the-vanishing-gradient-problem http://neuralnetworksanddeeplearning.com/chap5.html
- #43: https://www.mathworks.com/help/nnet/ug/layers-of-a-convolutional-neural-network.html#mw_ad6f0a9d-9cc7-4e57-9102-0204f1f13e99 https://prateekvjoshi.com/2016/04/05/what-is-local-response-normalization-in-convolutional-neural-networks/ “lateral inhibition” This refers to the capacity of an excited neuron to subdue its neighbors. We basically want a significant peak so that we have a form of local maxima. This tends to create a contrast in that area, hence increasing the sensory perception. Increasing the sensory perception is a good thing! We want to have the same thing in our CNNs.
- #45: https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks-Part-2/
- #47: https://github.com/Kulbear/deep-learning-nano-foundation/wiki/ReLU-and-Softmax-Activation-Functions
- #49: https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolutional-Neural-Networks-Part-2/
- #50: https://www.coursera.org/learn/machine-learning-projects/lecture/WNPap/transfer-learning
- #51: https://machinelearningmastery.com/image-augmentation-deep-learning-keras/
- #52: https://www.youtube.com/watch?v=fTUwdXUFfI8&index=2&t=895s&list=PLAI6JViu7Xmd_UKcm-_Mnxe1lvQI__qmW
- #54: Big Data: large data sets are available – Imagenet: 14M+ labeled images http://www.image-net.org/ – YouTube-8M: 7M+ labeled videos https://research.google.com/youtube8m/ – AWS public data sets: https://aws.amazon.com/public-datasets/ Baidu’s Chinese speech recognition: 4TB of training data, +/- 10 Exaflops Computations Neural networks can now be trained on a Raspberry Pi or GPUs because DL model is lightweight
- #58: https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
- #59: https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
- #60: https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html https://www.youtube.com/watch?v=VxhSouuSZDY http://iamaaditya.github.io/2016/03/one-by-one-convolution/ https://arxiv.org/pdf/1312.4400v3.pdf
- #61: https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html a] "Deep Residual Learning for Image Recognition", Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Tech Report 2015. [b] "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks", Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. NIPS 2015.
- #62: http://image-net.org/challenges/LSVRC/2016/results [a] W. Ouyang, X. Wang, X. Zeng, S. Qiu, P. Luo, Y. Tian, H. Li, S. Yang, Z. Wang, C. Loy, X. Tang, “DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection,” CVPR 2015. [b] Yang, B., Yan, J., Lei, Z., Li, S. Z. "Craft objects from images." CVPR 2016. [c] X. Zeng, W. Ouyang, B. Yang, J. Yan, X. Wang, “Gated Bi-directional CNN for Object Detection,” ECCV 2016. [d] Ouyang, W., Wang, X., Zhang, C., Yang, X. Factors in Finetuning Deep Model for Object Detection with Long-tail Distribution. CVPR 2016. [e] Wanli Ouyang, Hongyang Li, Xingyu Zeng, and Xiaogang Wang, "Learning Deep Representation with Large-scale Attributes", In Proc. ICCV 2015. [f] https://github.com/yjxiong/caffe
- #63: http://image-net.org/challenges/LSVRC/2017/results [1] Wang F, Jiang M, Qian C, et al. Residual Attention Network for Image Classification[J]. arXiv preprint arXiv:1704.06904, 2017. [2] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778. [3] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[C]//AAAI. 2017: 4278-4284. [4] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[J]. arXiv preprint arXiv:1505.04597, 2015. [5] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[J]. arXiv preprint arXiv:1612.03144, 2016. [6] Shrivastava A, Sukthankar R, Malik J, et al. Beyond skip connections: Top-down modulation for object detection[J]. arXiv preprint arXiv:1612.06851, 2016. [7] Zeng X, Ouyang W, Yan J, et al. Crafting GBD-Net for Object Detection[J]. arXiv preprint arXiv:1610.02579, 2016.
- #64: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith
- #65: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith [N. Dalal and B. Triggs. “Histograms of oriented gradients for human detection.” In CVPR, 2005.]
- #66: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith [B. Alexe, T. Deselaers, and V. Ferrari. “Measuring the objectness of image windows.” IEEE transactions on Pattern Analysis and Machine Intelligence, 2012.]
- #67: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith
- #68: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith Texture :بنية او نسيج او تركيب
- #69: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith
- #70: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith [P. F. Felzenszwalb and D. P. Huttenlocher. “Efficient Graph-Based Image Segmentation.” IJCV, 59:167–181, 2004.]
- #71: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith [P. F. Felzenszwalb and D. P. Huttenlocher. “Efficient Graph-Based Image Segmentation.” IJCV, 59:167–181, 2004.]
- #72: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith
- #73: presentation :Selective Search for Object Recognition Uijlings et al. Schuyler Smith
- #75: I2=rgb2hsv(I);
- #76: I4=rgb2lab(I);
- #80: Adversarial :خصومة https://arxiv.org/pdf/1312.6199v4.pdf https://www.quora.com/What-are-some-recent-and-potentially-upcoming-breakthroughs-in-deep-learning https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
- #81: http://soumith.ch/eyescream/
- #82: https://arxiv.org/pdf/1412.2306v2.pdf https://arxiv.org/pdf/1406.5679v1.pdf
- #83: https://arxiv.org/pdf/1506.02025.pdf
- #84: https://drive.google.com/file/d/0B1nQa_sA3W2iN3RQLXVFRkNXN0k/view