





















































![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=560&fit=bounds)










Ad
More Related Content
What's hot (20)
Viewers also liked (10)








Ad
Similar to 論文輪読: Deep neural networks are easily fooled: High confidence predictions for unrecognizable images (20)


![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=560&fit=bounds)

![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=560&fit=bounds)









![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=560&fit=bounds)

Ad
論文輪読: Deep neural networks are easily fooled: High confidence predictions for unrecognizable images
- 1. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 味曽野雅史 (weblab B4) 2015/10/15 2015/10/15 味曽野雅史 (weblab B4) 1
- 2. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 紹介する論文 • Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images • Anh Nguyen, Jason Yosinski, Jeff Clune • University of Wyoming, Cornell University • Computer Vision and Pattern Recognition (CVPR ’15), IEEE, 2015. • http://www.evolvingai.org/fooling • 被引用: 39 件 (Google Scholar) • 画像識別において,人間には理解できなくても DNN が 99.99%の確信度を 持つような画像を作成することができる; 進化的アルゴリズムにより,画像 を生成 2015/10/15 味曽野雅史 (weblab B4) 2
- 3. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 画像例 Figure 1: ImageNet で訓練された DNN で確信度 99.6%以上となる画像 (本論文より) 2015/10/15 味曽野雅史 (weblab B4) 3
- 4. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 背景 • DNN の中身はブラックボックス的に扱われることが多い • DNN を可視化することにより,何かしらの知見を得たい 2015/10/15 味曽野雅史 (weblab B4) 4
- 5. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 関連研究 : (C)NN の可視化 • 第一層のフィルタを可視化 • 高次元の表現を可視化 • 各層ごとにどういう計算がおこなわれるのかを可視化 • J.Yosinski et al. (2014) • Mahendran & Vadaldi (2014) • deconvolution による可視化 • Zeiler & Fergus (2013) • maximize activation • Erhan et al. (2009) • K.Simonyan et al. (2013) • C.Szegedy et al. (2013) • I.J.Goodfellow et al. (2014) • Deep Dream (2015) • J.Yosinski et al. (2015) 2015/10/15 味曽野雅史 (weblab B4) 5
- 6. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 第一層のフィルタを可視化 • 例えばガボールフィルタに近いものが学習される例が確認されている • Conv -> Pool -> FC -> FC -> Softmax の NN (MNIST) の第一層のフィ ルタ (http://eric-yuan.me/cnn/) 2015/10/15 味曽野雅史 (weblab B4) 6
- 7. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 高次元の表現を可視化 • http://colah.github.io/posts/2015-01-Visualizing-Representations/ 2015/10/15 味曽野雅史 (weblab B4) 7
- 8. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Deconvolution による可視化 • ある入力画像において,どの部分が活性化に寄与したかを可視化する (Zeiler & Fergus) 2015/10/15 味曽野雅史 (weblab B4) 8
- 9. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Deconvolution による可視化 Figure 2: Zeiler & Fergus (2013) より 2015/10/15 味曽野雅史 (weblab B4) 9
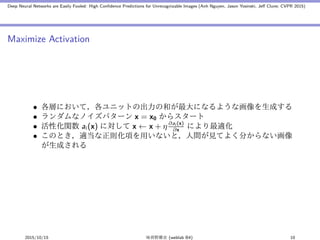
- 10. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Maximize Activation • 各層において,各ユニットの出力の和が最大になるような画像を生成する • ランダムなノイズパターン x = x0 からスタート • 活性化関数 ai (x) に対して x ← x + η ∂ai (x) ∂x により最適化 • このとき,適当な正則化項を用いないと,人間が見てよく分からない画像 が生成される 2015/10/15 味曽野雅史 (weblab B4) 10
- 11. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 本論文の例 • 正則化項なし (99.99%の確信度) 2015/10/15 味曽野雅史 (weblab B4) 11
- 12. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) K.Simonayn et al. (2013) • L2 正則化を利用 2015/10/15 味曽野雅史 (weblab B4) 12
- 13. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Deep Dream • 隣接するピクセル同士が相関するような制約を入れている 2015/10/15 味曽野雅史 (weblab B4) 13
- 14. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) J.Yosinski et al. (2015) • 4 つの異なる正則化方法を提案 2015/10/15 味曽野雅史 (weblab B4) 14
- 15. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 関連研究 : DNN と人間の視覚の違い • 正しく分類されている画像を,少し変更するだけで誤認識するように変更 できる • C.Szegedy et al. (2013) • I.J.Goodfellow et al. (2014) 2015/10/15 味曽野雅史 (weblab B4) 15
- 16. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) C.Szegedy et al. (2013) • 正しく識別出来てる画像を少し歪ませることで,全く別のものとして識別 させる 2015/10/15 味曽野雅史 (weblab B4) 16
- 17. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Goodfellow et al. (2014) Figure 3: 2015/10/15 味曽野雅史 (weblab B4) 17
- 18. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) どう画像を変化させているか? • 通常の学習の場合 → 誤差逆伝播,つまり誤識別した場合パラメータを調 整する • この時,パラメータを調整せず,逆に画像に少し変更を加えたら..? 2015/10/15 味曽野雅史 (weblab B4) 18
- 19. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) この論文の内容 - EA で画像を生成したところ,よく分からないのができた,というのが実際の経 緯っぽい 2015/10/15 味曽野雅史 (weblab B4) 19
- 20. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) この論文で使われるネットワークモデル • AlexNet (A.Krizhevsky et al. 2012) • LeNet (Y.LeCun et al. 1998) • 既に訓練済みのものを利用 (caffe 版) 2015/10/15 味曽野雅史 (weblab B4) 20
- 21. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 画像の生成手法 • 進化的アルゴリズム (Evolutionary Algorithm) • MAP-Elites (multi-dimensional archive of phenotypic elites) • A.Cully et al. 2015 • ベストな個体を記憶 • 各繰り返しステップにおいて, • 適当に個体を選び,適当に突然変異 • もし現在のベストな個体よりも良ければ,それと交換 • 今回の場合,ベストな個体 = 確信度が高い • direct encoding • 遺伝子として画像をそのまま表現 • 例) MNIST なら 28x28 のピクセル • 各ピクセルは一様乱数で初期化 • indirect encoding • Compositional Pattern-Producing Network (CPPN) • K.O.Stanley (2007) • ピクセル位置 (x,y) を受け取り,色値を出力する NN のようなもの 2015/10/15 味曽野雅史 (weblab B4) 21
- 22. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) LeNet (MNIST) Figure 4: direct encoding: 確信度 99.99% 2015/10/15 味曽野雅史 (weblab B4) 22
- 23. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) LeNet (MNIST) Figure 5: indirect encoding: 確信度 99.99% 2015/10/15 味曽野雅史 (weblab B4) 23
- 24. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) AlexNet (ImageNet) • direct encoding における世代数と確信度の変化 • direct encoding はあまりうまくいかず 2015/10/15 味曽野雅史 (weblab B4) 24
- 25. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) AlexNet (ImageNet) • indirect encoding における世代数と確信度の変化 2015/10/15 味曽野雅史 (weblab B4) 25
- 26. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) indirect encoding によって生成された画像 Figure 6: 平均確信度 99.12% 2015/10/15 味曽野雅史 (weblab B4) 26
- 27. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) fooling image を入れた学習 • DNN1 で学習 (n クラス) • DNN1 を使ってfooling image を作成 • DNN2 で fooling image を入れた (n+1) クラスの分類問題を学習 • これを繰り返す 2015/10/15 味曽野雅史 (weblab B4) 27
- 28. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) fooling image を入れた学習: ImageNet での結果 • DNN2 で作成したfooling image の確信度は DNN1 のときと比べ,大きく下 がった (平均確信度 88.1%から 11.7%) • ただし,MNIST の場合は確信度はそれほど下がらなかった 2015/10/15 味曽野雅史 (weblab B4) 28
- 29. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 生成された画像に対する考察 • ユニークな特徴を強調するように進化すれば良い • (人間には知覚できない) 少しの変化で識別するクラスが変えられることを 考えると,多様性が生まれているに驚きがある 2015/10/15 味曽野雅史 (weblab B4) 29
- 30. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 系統的な画像の生成 • 同じ種類 (犬など) は,同じようなものが進化で得られる 2015/10/15 味曽野雅史 (weblab B4) 30
- 31. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 繰り返し模様を除去した場合 • indirect encoding で得られる結果には,繰り返し模様が多い • 繰り返しを除去した場合 (下図): 繰り返しが確信度に寄与することが確認 できる 2015/10/15 味曽野雅史 (weblab B4) 31
- 32. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) 仮説: 生成モデルと識別モデル • 今回の DNN のような識別モデル p(y|X) の場合,入力 X に対して,クラ ス y を決める境界面を学習する • 入力空間が高次元の場合,あるクラスと認識する空間は訓練データの規模 よりも大きくなる • (仮説) 進化的計算で生成された画像は,境界面よりも遠く離れていた • 生成モデル p(y, X) であれば,p(y|X) の他に p(X) も必要.今回のような 問題はおきないかもしれない 2015/10/15 味曽野雅史 (weblab B4) 32
- 33. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) まとめ • 進化的計算によりあるクラスと 99%の確信度で識別される画像を生成する と,人間には判断がつかないものが生成される • 進化的計算の結果得られる画像として考えられるもの • どのクラスに対応する画像も似たようなものが生成される (C.Szegedy らの実験結果より) • 人間に認識できる画像が生成される • 実験してみると,上の二つのどちらでもなかった • もちろん筆者が意図的に認識できないような画像を生成したわけでは ない • DNN の実世界への応用を考えると,セキュリティ的な問題がある • 防犯カメラ,自動運転,音声認識,画像検索エンジン,… • CPPN EA による画像生成は,DNN 可視化の新規手法ともいえる 2015/10/15 味曽野雅史 (weblab B4) 33
- 34. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Deep Visualization Toolbox • http://yosinski.com/deepvis • https://github.com/yosinski/deep-visualization-toolbox 2015/10/15 味曽野雅史 (weblab B4) 34
- 35. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Reference • Yosinski, J., Clune, J., Bengio, Y., and Lipson, H. How transferable are features in deep neural networks? In Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., and Weinberger, K.Q. (eds.), Advances in Neural Information Processing Systems 27, pp. 3320–3328. Curran Associates, Inc., Decembe 2014. • Mahendran, A. and Vedaldi, A. Understanding Deep Image Representations by Inverting Them. ArXiv e-prints, November 2014. • Zeiler, Matthew D and Fergus, Rob. Visualizing and understanding convolutional neural networks. arXiv preprint arXiv:1311.2901, 2013. • Erhan, Dumitru, Bengio, Yoshua, Courville, Aaron, and Vincent, Pascal. Visualizing higher-layer features of a deep network. Technical report, Technical report, University of Montreal, 2009. • K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013 2015/10/15 味曽野雅史 (weblab B4) 35
- 36. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (Anh Nguyen, Jason Yosinski, Jeff Clune; CVPR 2015) Reference • K. O. Stanley and R. Miikkulainen. A taxonomy for artificial embryogeny. Artificial Life, 9(2):93–130, 2003 • A. Cully, J. Clune, and J.-B. Mouret. Robots that can adapt like natural animals. arXiv preprint arXiv:1407.3501, 2014. • Szegedy, Christian, Zaremba, Wojciech, Sutskever, Ilya, Bruna, Joan, Erhan, Dumitru, Goodfellow, Ian J., and Fergus, Rob. Intriguing properties of neural networks. CoRR, abs/1312.6199, 2013. • Goodfellow, Ian J, Shlens, Jonathon, and Szegedy, Christian. Explaining and Harnessing Adversarial Examples. ArXiv e-prints, December 2014. • Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Understanding Neural Networks Through Deep Visualization, ICML DL Workshop 2015. • Alexander Mordvintsev, Christopher Olah, Mike Tyka. Inceptionism: Going Deeper into Neural Networks http://googlere- search.blogspot.jp/2015/06/inceptionism-going-deeper-into-neural.html 2015/10/15 味曽野雅史 (weblab B4) 36