












![credits: [x]](https://image.slidesharecdn.com/df1-py-2-kalaidin-introductiontowordembeddingswithpython-150921141354-lva1-app6891/85/DF1-Py-Kalaidin-Introduction-to-Word-Embeddings-with-Python-15-320.jpg)








![here comes word2vec
Distributed Representations of Words and Phrases and their Compositionality, Mikolov et al: [paper]](https://image.slidesharecdn.com/df1-py-2-kalaidin-introductiontowordembeddingswithpython-150921141354-lva1-app6891/85/DF1-Py-Kalaidin-Introduction-to-Word-Embeddings-with-Python-24-320.jpg)













![word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling
Word-Embedding Method, Goldberg et al, 2014 [arxiv]](https://image.slidesharecdn.com/df1-py-2-kalaidin-introductiontowordembeddingswithpython-150921141354-lva1-app6891/85/DF1-Py-Kalaidin-Introduction-to-Word-Embeddings-with-Python-38-320.jpg)












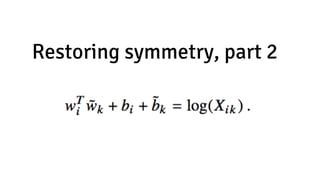















![deep walk:
DeepWalk: Online Learning of Social
Representations [link]](https://image.slidesharecdn.com/df1-py-2-kalaidin-introductiontowordembeddingswithpython-150921141354-lva1-app6891/85/DF1-Py-Kalaidin-Introduction-to-Word-Embeddings-with-Python-67-320.jpg)

![predicting hashtags
interesting read: #TAGSPACE: Semantic
Embeddings from Hashtags [link]](https://image.slidesharecdn.com/df1-py-2-kalaidin-introductiontowordembeddingswithpython-150921141354-lva1-app6891/85/DF1-Py-Kalaidin-Introduction-to-Word-Embeddings-with-Python-69-320.jpg)


































Ad
More Related Content
Viewers also liked (6)
Similar to DF1 - Py - Kalaidin - Introduction to Word Embeddings with Python (20)

![[Emnlp] what is glo ve part ii - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisglovepartii-towardsdatascience-200228052050-thumbnail.jpg?width=560&fit=bounds)


Ad
More from MoscowDataFest (6)






Ad
Recently uploaded (20)









![Hardy_Weinbergs_law_and[1]. A simple Explanation](https://cdn.slidesharecdn.com/ss_thumbnails/hardyweinbergslawand1-250505160803-e672c3cf-thumbnail.jpg?width=560&fit=bounds)










DF1 - Py - Kalaidin - Introduction to Word Embeddings with Python
- 1. Introduction to word embeddings Pavel Kalaidin @facultyofwonder Moscow Data Fest, September, 12th, 2015
- 5. лойс
- 6. годно, лойс лойс за песню из принципа не поставлю лойс взаимные лойсы лойс, если согласен What is the meaning of лойс?
- 7. годно, лойс лойс за песню из принципа не поставлю лойс взаимные лойсы лойс, если согласен What is the meaning of лойс?
- 8. кек
- 9. кек, что ли? кек))))))) ну ты кек What is the meaning of кек?
- 10. кек, что ли? кек))))))) ну ты кек What is the meaning of кек?
- 12. simple and flexible platform for understanding text and probably not messing up
- 13. one-hot encoding? 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 14. co-occurrence matrix recall: word-document co-occurrence matrix for LSA
- 15. credits: [x]
- 16. from entire document to window (length 5-10)
- 17. still seems suboptimal -> big, sparse, etc.
- 18. lower dimensions, we want dense vectors (say, 25-1000)
- 19. How?
- 22. lots of memory?
- 23. idea: directly learn low- dimensional vectors
- 24. here comes word2vec Distributed Representations of Words and Phrases and their Compositionality, Mikolov et al: [paper]
- 25. idea: instead of capturing co- occurrence counts predict surrounding words
- 26. Two models: C-BOW predicting the word given its context skip-gram predicting the context given a word Explained in great detail here, so we’ll skip it for now Also see: word2vec Parameter Learning Explained, Rong, paper
- 28. CBOW: several times faster than skip-gram, slightly better accuracy for the frequent words Skip-Gram: works well with small amount of data, represents well rare words or phrases
- 29. Examples?
- 36. Wwoman - Wman = Wqueen - Wking classic example
- 38. word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method, Goldberg et al, 2014 [arxiv]
- 39. all done with gensim: github.com/piskvorky/gensim/
- 40. ...failing to take advantage of the vast amount of repetition in the data
- 41. so back to co-occurrences
- 42. GloVe for Global Vectors Pennington et al, 2014: nlp.stanford. edu/pubs/glove.pdf
- 43. Ratios seem to cancel noise
- 44. The gist: model ratios with vectors
- 45. The model
- 49. recall:
- 51. Restoring symmetry, part 2
- 52. Least squares problem it is now
- 53. SGD->AdaGrad
- 54. ok, Python code
- 56. two sets of vectors input and context + bias average/sum/drop
- 57. complexity |V|2
- 65. Abusing models
- 67. deep walk: DeepWalk: Online Learning of Social Representations [link]
- 68. user interests Paragraph vectors: cs.stanford. edu/~quocle/paragraph_vector.pdf
- 69. predicting hashtags interesting read: #TAGSPACE: Semantic Embeddings from Hashtags [link]
- 70. RusVectōrēs: distributional semantic models for Russian: ling.go.mail. ru/dsm/en/
- 72. corpus matters
- 73. building block for bigger models ╰(*´︶`*)╯
- 74. </slides>