Distributed Logistic Model Trees
0 likes1,794 views

The document discusses the use of interpretable algorithms, specifically logistic model trees, in data science compared to black box methods such as logistic regression and decision trees. It highlights the importance of metrics like accuracy, precision, and recall in evaluating model performance, particularly in distributed implementations suitable for big data environments. The authors showcase example algorithms and the advantages of using distributed systems like Spark for building decision trees and conducting logistic regressions.




































Distributed Logistic Model Trees
- 1. Distributed Logistic Model Trees, Stratio Intelligence Mateo Álvarez and Antonio Soriano @StratioBD
- 2. Aerospace Engineer, MSc in Propulsion Systems (UPM), Master in Data Science (URJC). Working as data scientist and Big Data developer at Stratio Big Data in the data science department mateo-alvarez
- 3. Ph.D. in Telecommunications, MSc in Electronic Systems Engineering and Telecommunication Technologies, Systems and Networks (UPV), and MSc “Big Data Expert” (UTAD). Working as data scientist and Big Data developer at at Stratio Big Data in the data science department @Phd_A_Soriano
- 4. Why using interpretable algorithms instead of “black boxes” Logistic Regression Decision Trees Variance-Bias tradeoff Metrics Demo Logistic Model Trees Distributed implementation Cost function & configuration params Demo
- 5. • Why use interpretable algorithms instead of “black boxes” • Logistic Regression • Decision Trees • Variance-Bias tradeoff @StratioBD
- 6. Accuracy Explainability VS Medical Studies Power management Financial environment Criminal activity
- 10. Feature 1 Root node Leaf node Leaf node
- 11. Feature 1 Root node Feature 2 Feature 2 Leaf node Leaf node Leaf node Leaf node
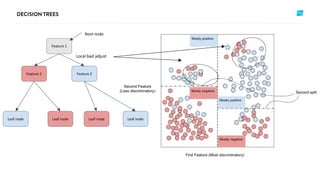
- 12. Feature 1 Root node Feature 2 Feature 2 Leaf node Leaf node Leaf node Leaf node Local bad adjust
- 13. MeanError Model complexity Test error Training error Model complexity Variance Total error Bias 2 Error OverfittingUnderfitting
- 14. Variance Bias
- 15. Missing important variables for the problem to make the predictions Variance Bias
- 16. Overfitting to the sample/training data Variance Bias
- 17. Irreducible error on prediction Variance Bias
- 18. • Logistic Model Trees • Distributed implementation • Cost function & configuration parametres • Demo @StratioBD
- 22. Feature 1 Root node Feature 2 Feature 2
- 25. DISTRIBUTED IMPLEMENTATION Spark’s Decision Tree (distributed implementation of random forests) Spark’s Logistic Regression / weka’s Logistic Regression on the nodes
- 26. LMT Cost function to fix the logistic regression threshold • AccuracyCostFunction • ConfusionMatrix • PrecisionCostFunction • PrecisionRecallCostFunction • RocCostFunction The same cost function for pruning criteria Performance metrics Performance metrics Performance metrics
- 27. Big datasets Power of spark to distribute building the tree and logistic regressions ADVANTAGES OF THIS IMPLEMENTATION Medium datasets Distributed tree growth and weka’s logistic regression Small datasets Although it can be slow to distribute the data for the decision tree, cost functions can be still used and specific optimization for particular cases
- 28. Example of DLMT algorithm in a synthetic dataset
- 30. PREDICTION Positive Negative TRUE CONDITION Positive True Positives False Negatives Negative False Positives True Negatives Precission True Positive Rate (Recall) False Positive Rate TPR = TP/(TP+FN) Insensitive to unbalance FPR = FP/(FP+TN) Insensitive to unbalance Precision = TP/(TP+FP) Sensitive to unbalance Accuracy = (TP+TN)/(TP+TN+FP+FN) Sensitive to unbalance
- 31. PREDICTION Positive Negative TRUE CONDITION Positive True Positives False Negatives Negative False Positives True Negatives True Positive Rate (Recall) False Positive Rate AUROC (AUC): TPR/FPR -> Insensitive to unbalance! TPR FPR Best performance
- 32. PREDICTION Positive Negative TRUE CONDITION Positive True Positives False Negatives Negative False Positives True Negatives True Positive Rate (Recall) AUPRC: Precision/TPR -> Sensitive to unbalance! Precission Precision Recall Best performance
- 34. @StratioBD
- 35. Accuracy ExplainabilityVS Performance Metrics: AUROC, AUPRC, ACCURACY Automatic Benchmarking Framework f f 1 n BenchmarkABF 1 2 3 4
- 36. THANK YOU UNITED STATES Tel: (+1) 408 5998830 EUROPE Tel: (+34) 91 828 64 73 [email protected] www.stratio.com @StratioBD