Distributed system
Download as PPT, PDF2 likes1,501 views

DSM system Shared memory On chip memory Bus based multiprocessor Working through cache Write through cache Write once protocol Ring based multiprocessor Protocol used Similarities and differences b\w ring based and bus based





















































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Distributed system (20)




















Ad
More from Syed Zaid Irshad (20)




















Recently uploaded (20)




















Distributed system
- 1. Page 1Page 1 Distributed System
- 2. Page 2 TOPICS TO BE COVERED: • DSM system • Shared memory • On chip memory • Bus based multiprocessor • Working through cache • Write through cache • Write once protocol • Ring based multiprocessor • Protocol used • Similarities and differences bw ring based and bus based
- 3. Page 3 What is a DSM system? • A distributed-memory system (often called a multicomputer) consist of collection of workstations connected by a LAN share a single paged,virtual address space • Each page is present on exactly one maachine • An attempt to reference a page on different machine causes a hardware page fault which traps to operating system • The OS den sends a message to the remote machinewhich finds the needed page and sends it back to the req. processor
- 4. Page 4 What is shared memory? • Shared memory is the memory that is simultaneously accessed by more than one CPU OR PROCCESSOR • There are local caches for each processor • It is cheaper to cache than main memory • It is simple to program and hard to scale
- 5. Page 5 Various architectures to be discussed: • On chip memory • Bus based multiprocessors • Ring based multiprocessors
- 6. Page 6 On Chip Memory • In this CPU portion of the chip has a address and data lines that directly connect to the memory portion • Such chips are used in cars,appliances and even toys • In hypothetical shared memory multiprocessor we have multiple CPU’S directly sharing the same memory but it would be complicated n expensive
- 7. Page 7 • On-Chip Memory CPU Memory CPU1 Memory CPU4 CPU2 CPU3 Chip package Address and data lines Connecting the CPU to the memory extension A single-chip computer A hypothetical shared-memory Multiprocessor.
- 8. Page 8 What is a bus??? • BUS is a collection of parallel wires,some holding the address the CPU wants to read or write,some for sending or receiving data and the rest for controlling the transfers. • In most systems buses are external and are used to connect CPU’S,MEMORIES AND I/O CONTROLLERS
- 9. Page 9 BusBus CPU ACPU A CPU BCPU B memorymemory Device I/O Device I/O BUS BASED MULTIPROCESSORS SMP: Symmetric Multi-Processing All CPUs connected to one bus (backplane) Memory and peripherals are accessed via shared bus. System looks the same from any processor.
- 10. Page 10 Bus-based multiprocessors Dealing with bus overload - add local memory CPU does I/O to cache memory - access main memory on cache miss BusBus memorymemory Device I/O Device I/O CPU ACPU A cachecache CPU BCPU B cachecache
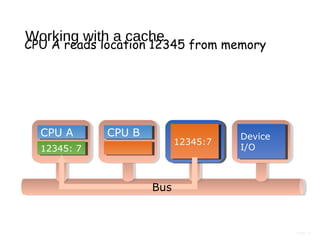
- 11. Page 11 Working with a cache CPU A reads location 12345 from memory 12345:712345:7 Device I/O Device I/O CPU ACPU A 12345: 712345: 7 CPU BCPU B Bus
- 12. Page 12 Working with a cache CPU B reads location 12345 from memory 12345:712345:7 Device I/O Device I/O CPU ACPU A 12345: 312345: 3 CPU BCPU B 12345: 712345: 7 Gets old value Memory not coherent! Bus
- 13. Page 13 Write-through cache … continued CPU B reads location 12345 from memory - loads into cache 12345:312345:3 Device I/O Device I/O CPU ACPU A 12345: 312345: 3 CPU BCPU B 12345: 312345: 3 Bus
- 14. Page 14 Write-through cache CPU A modifies location 12345 - write-through 12345:3 Device I/O Device I/O CPU ACPU A 12345: 3 CPU BCPU B 12345: 312345: 3 Cache on CPU B not updated Memory not coherent! 12345:012345:0 12345: 012345: 0 Bus
- 15. Page 15 Write once protocol • This protocol manages cache blocks, each of which can be in one of the following three states: INVALID: This cache block does not contain valid data. CLEAN: Memory is up-to-date; the block may be in other caches. DIRTY: Memory is incorrect; no other cache holds the block. • The basic idea of the protocol is that a word that is being read by multiple CPUs is allowed to be present in all their caches. A word that is being heavily written by only one machine is kept in its cache and not written back to memory on every write to reduce bus traffic.
- 16. Page 16 Write through protocol Event Action taken by a cache in response to its own CPU’s operation Action taken by a cache in response to a remote CPU’s operation Read miss Fetch data from memory and store in cache no action Read hit Fetch data from local cache no action Write miss Update data in memory and store in cache no action Write hit Update memory and cache invalidate cache entry
- 17. Page 17 For example A B W1C W1 CLEAN Memory is correct (a) Initial state – word W1 containing value W1 is in memory and is also cached by B. CPU A B W1C W1 W1 CLEANCLEAN Memory is correct (b) A reades word W and gets W1. B doe not respond to the read, but the memory does.
- 18. Page 18 A B W1C W2 W1 A B W1C W3 W1 DIRTY INVALID DIRTY INVALID Memory is correct (c)A write a value W2, B snoops on the bu sees the write, and invalidates its entry. A’s copy is marked DIRTY. Not update memory Memory is correct (d) A write W again. This and subsequent writes by A are done locally, without any bus traffic.
- 19. Page 19 A B W1C W3 W1 INVALID INVALID DIRTY W3 (e) C reads or writes W. A sees th request by snooping on the bus, provides the value, and invalidates its own entry. C now has the only valid copy. Not update memory
- 20. Page 20 Ring-Based Multiprocessors: Memnet CPU CPU CPU CPU CPU CPU CPU Private memory MMU Cache Home memory Memory management unit Location Interrupt Home Exclusive Valid 0 1 2 3 The block table
- 21. Page 21 Protocol • Read • When the CPU wants to read a word from shared memory, the memory address to be read is passed to the Memnet device, which checks the block table to see if the block is present. If so, the request is satisfied. If not, the Memnet device waits until it captures the circulating token, puts a request onto the ring. As the packet passes around the ring, each Memnet device along the way checks to see if it has the block needed. If so, it puts the block in the dummy field and modifies the packet header to inhibit subsequent machines from doing so. • If the requesting machine has no free space in its cache to hold the incoming block, to make space, it picks a cached block at random and sends it home. Blocks whose Home bit are set are never chosen because they are already home.
- 22. Page 22 • Write • If the block containing the word to be written is present and is the only copy in the system (i.e., the Exclusive bit is set), the word is just written locally. • If the needed block is present but it is not the only copy, an invalidation packet is first sent around the ring to force all other machines to discard their copies of the block about to be written. When the invalidation packet arrives back at the sender, the Exclusive bit is set for that block and the write proceeds locally. • If the block is not present, a packet is sent out that combines a read request and an invalidation request. The first machine that has the block copies it into the packet and discards its own copy. All subsequent machines just discard the block from their caches. When the packet comes back to the sender, it is stored there and written.
- 23. Page 23 Similarities bw bus based and ring based multiprocessors • In both cases read operations always return the values most recently written • In both designs a block may be absent from a cache,present in multiple caches for reading,or present in a single cache for writing
- 24. Page 24 DIFFERENCES BW TWO MULTIPROCESSORS BUS BASED MULTIPROCCESORS • They are tightly coupled with the CPU’S normally in a single rack • It has seprate global memory RING BASED MULTIPROCCESORS • Machines here can be much more loosely coupled n this loose coupling can affect their performance • It has no seprate global memory