Distributed systems - A Primer
Download as ODP, PDF6 likes477 views

This document provides an overview of distributed systems and strategies for scaling databases and applications. It defines distributed systems as collections of independent computers that appear as a single system. Key characteristics are concurrency, transparency, and independent failures without a global clock. The document discusses reading and replicating data for availability and consistency trade-offs governed by the CAP theorem. Scaling strategies include query optimization, indexes, caching, and sharding or partitioning data across servers.





































































































































Ad
More Related Content
Similar to Distributed systems - A Primer (20)
More from MD Sayem Ahmed (6)




Ad
Recently uploaded (20)




















Ad
Distributed systems - A Primer
- 1. Distributed Systems – A Primer MD Sayem Ahmed
- 2. Who am I ● A Bangladeshi currently living in Berlin, Germany ● Occasionally blogs at www.codesod.com ● Tweets at @say3mbd ● Can also be found on LinkedIn ● Can be reached via email at [email protected]
- 3. Today’s Agenda ● What are Distributed Systems? ● Why Distributed Systems? ● Read Replication/Single-master Replication ● CAP Theorem ● Sharding/Partitioning/Multi-master Replication
- 4. Distributed Systems – A Definition A distributed system is a collection of independent computers that appears to its users as a single coherent system Distributed Systems: Principles and Paradigms by Andrew S. Tanenbaum, Maarten van Steen
- 5. A Typical Web Application is a Distributed System
- 6. Key Characteristics of Distributed Systems ● Concurrency – all the computers operate at the same time
- 7. Key Characteristics of Distributed Systems ● Concurrency – all the computers operate at the same time ● Transparency – system is perceived as a whole
- 8. Key Characteristics of Distributed Systems ● Concurrency – all the computers operate at the same time ● Transparency – system is perceived as a whole ● Independent failure – the computers can fail independently
- 10. Key Characteristics of Distributed Systems ● Concurrency – all the computers operate at the same time ● Transparency – system is perceived as a whole ● Independent failure – the computers can fail independently ● No global clock
- 12. Back to the Book Shop
- 13. More and more people are using my book shop! But then…. It takes a long time to load the book review pages!
- 14. Book Shop is not scalable! Needs to handle more users!
- 15. What should I scale?
- 18. ● Powerful Application Servers? ● More Application Servers? ● Powerful Database Server?
- 20. Focus on ● Database ● Memory ● CPU ● Network I/O ● Disk I/O
- 21. Performance Measurement – Burning Questions ● Are my database queries slow?
- 22. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high?
- 23. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory?
- 24. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory? ● Does my application have a memory leak?
- 25. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory? ● Does my application have a memory leak? ● Is garbage collection being triggered too often?
- 26. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory? ● Does my application have a memory leak? ● Is garbage collection being triggered too often? ● Is there something wrong with the Network I/O?
- 27. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory? ● Does my application have a memory leak? ● Is garbage collection being triggered too often? ● Is there something wrong with the Network I/O? ● Is there something funny going on with the Disk Usage? Are reading/writing to disks taking too long?
- 28. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory? ● Does my application have a memory leak? ● Is garbage collection being triggered too often? ● Is there something wrong with the Network I/O? ● Is there something funny going on with the Disk Usage? Are reading/writing to disks taking too long? ● Are the third-party APIs taking too long to respond?
- 29. Performance Measurement – Burning Questions ● Are my database queries slow? ● Is my application’s CPU consumption high? ● Is my application running out of memory? ● Does my application have a memory leak? ● Is garbage collection being triggered too often? ● Is there something wrong with the Network I/O? ● Is there something funny going on with the Disk Usage? Are reading/writing to disks taking too long? ● Are the third-party APIs taking too long to respond? ● … and so on
- 30. Tools that help to measure ● New Relic / AppDynamics / DataDog ● Metrics (from Dropwizard), Grafana ● Cloud provider tools (i.e., AWS CloudWatch) ● Custom Resource Monitoring Tools
- 31. Some simple scaling strategies ● Try to optimize database queries (more on this later)
- 32. Some simple scaling strategies ● Try to optimize database queries (more on this later) ● Try purchasing more powerful CPUs and more memory (Vertical Scaling) for the application servers (only works for CPU- and memory-bound applications)
- 33. Some simple scaling strategies ● Try to optimize database queries (more on this later) ● Try purchasing more powerful CPUs and more memory (Vertical Scaling) for the application servers (only works for CPU- and memory-bound applications) ● If database is not a bottleneck, try adding more application server instances (Horizontal Scaling)
- 34. Some simple scaling strategies ● Try to optimize database queries (more on this later) ● Try purchasing more powerful CPUs and more memory (Vertical Scaling) for the application servers (only works for CPU- and memory-bound applications) ● If database is not a bottleneck, try adding more application server instances (Horizontal Scaling) ● Try using a CDN to serve static contents
- 35. Most of the time, it is the Database
- 36. Scaling a Single Database – some simple strategies ● Reduce the number of queries
- 37. Scaling a Single Database – some simple strategies ● Reduce the number of queries ● Use indexes
- 38. Scaling a Single Database – some simple strategies ● Reduce the number of queries ● Use indexes ● Make sure your indexes are being used by the queries in production
- 39. Scaling a Single Database – some simple strategies ● Reduce the number of queries ● Use indexes ● Make sure your indexes are being used by the queries in production ● Make sure you are not creating too many indexes on write-heavy tables
- 40. Scaling a Single Database – some simple strategies ● Reduce the number of queries ● Use indexes ● Make sure your indexes are being used by the queries in production ● Make sure you are not creating too many indexes on write-heavy tables ● Try purchasing powerful CPUs and more memories for the database server (Vertical Scaling)
- 41. Scaling a Single Database – some simple strategies ● Reduce the number of queries ● Use indexes ● Make sure your indexes are being used by the queries in production ● Make sure you are not creating too many indexes on write-heavy tables ● Try purchasing powerful CPUs and more memories for the database server (Vertical Scaling) ● … and many more (indexed views, denormalization, store pre- computed value for fast read etc.)
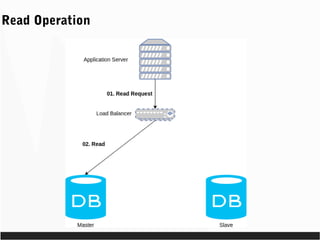
- 43. Scaling Database Reads through Read Replication
- 44. Read Operation
- 45. Read Operation
- 46. Read Operation
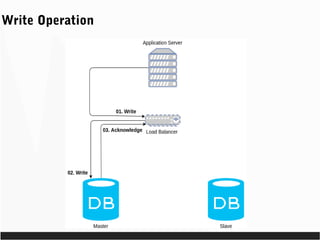
- 47. Write Operation
- 48. Write Operation
- 49. Write Operation
- 50. Write Operation
- 51. Write Operation
- 52. Write Operation
- 71. … at the cost of Availability
- 72. There will always be Trade-offs
- 73. It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees: CAP Theorem Source: https://en.wikipedia.org/wiki/CAP_theorem
- 74. It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees: – Consistency CAP Theorem Source: https://en.wikipedia.org/wiki/CAP_theorem
- 75. It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees: – Consistency – Availability CAP Theorem Source: https://en.wikipedia.org/wiki/CAP_theorem
- 76. It is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees: – Consistency – Availability – Partition Tolerance CAP Theorem Source: https://en.wikipedia.org/wiki/CAP_theorem
- 77. Every read receives the most recent write or an error CAP Theorem - Consistency Source: https://en.wikipedia.org/wiki/CAP_theorem
- 78. Every request receives a (non-error) response – without guarantee that it contains the most recent write CAP Theorem - Availability Source: https://en.wikipedia.org/wiki/CAP_theorem
- 79. The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes CAP Theorem – Partition Tolerance Source: https://en.wikipedia.org/wiki/CAP_theorem
- 80. Read Replication - Advantages ● Can easily handle vast amount of concurrent reads
- 81. Read Replication - Advantages ● Can easily handle vast amount of concurrent reads ● Configuring Redundancy is very easy
- 82. Read Replication - Problems ● Not ACID
- 83. Read Replication - Problems ● Not ACID ● Consistency or Availability – choose one
- 84. Read Replication - Problems ● Not ACID ● Consistency or Availability – choose one ● Increased operational complexity compared to a single database instance
- 85. How do I scale Writes?
- 86. Sharding / Partitioning / Multi-master Replication
- 87. Read/Write Operation User ID IP 1 - 100000 192.168.197.17 100001 - 200000 192.168.197.18
- 88. Read/Write Operation User ID IP 1 - 100000 192.168.197.17 100001 - 200000 192.168.197.18 User ID = 50000
- 89. Read/Write Operation User ID IP 1 - 100000 192.168.197.17 100001 - 200000 192.168.197.18 User ID = 50000
- 90. Read/Write Operation User ID IP 1 - 100000 192.168.197.17 100001 - 200000 192.168.197.18 User ID = 150000
- 91. Read/Write Operation User ID IP 1 - 100000 192.168.197.17 100001 - 200000 192.168.197.18 User ID = 150000
- 92. “I would like to calculate the total revenue earned from Harry Potter and the Deathly Hallows over a certain period”
- 93. Scatter
- 94. Compute
- 95. Gather
- 96. … Aka MapReduce ● Scatter/Gather is famously known as the MapReduce paradigm ● Popularized by a famous research paper from Google ● A popular implementation is part of the Apache Hadoop project
- 97. Sharding – advantages Can easily scale read/write to the Moon
- 98. Sharding – problems ● Operationally complex – Cluster Management – All queries need to have the Shard Key
- 99. Sharding – problems ● Operationally complex – Cluster Management – All queries need to have the Shard Key ● Sharding an RDBMS is painful – Referential integrity cannot be guaranteed anymore
- 100. Sharding – problems ● Operationally complex – Cluster Management – All queries need to have the Shard Key ● Sharding an RDBMS is painful – Referential integrity cannot be guaranteed anymore ● Each table must have the Shard Key
- 101. Sharding – problems ● Operationally complex – Cluster Management – All queries need to have the Shard Key ● Sharding an RDBMS is painful – Referential integrity cannot be guaranteed anymore ● Each table must have the Shard Key ● Not suitable if most of the queries are Scatter/Gather
- 102. Next Topics ● Distributed Hash Tables / Consistently Hashed Data Stores ● Distributed Transactions ● A very brief introduction to Microservices
- 103. Additional Resources ● Distributed Systems in One Lesson by Tim Berglund ● Distributed Systems reading list by Tim Berglund ● Building Microservices by Sam Newman ● PostgreSQL documentation on High Availability ● MongoDB Replication Manual ● High Scalability ● Enterprise Integration Patterns
- 104. Thank you!
- 105. Questions?