
























































![[AWS Dev Day] 실습워크샵 | 모두를 위한 컴퓨터 비전 딥러닝 툴킷, GluonCV 따라하기](https://cdn.slidesharecdn.com/ss_thumbnails/gluoncv-190930065523-thumbnail.jpg?width=560&fit=bounds)


























More Related Content
What's hot (14)
Viewers also liked (15)







Similar to Distributed-ness: Distributed computing & the clouds (20)



![Cloud Computing Bootcamp On The Google App Engine [v1.1]](https://cdn.slidesharecdn.com/ss_thumbnails/cloudcomputingbootcamponthegoogleappenginev1-1-090506155059-phpapp02-thumbnail.jpg?width=560&fit=bounds)
















More from Robert Coup (9)









Recently uploaded (20)




















Editor's Notes
- #5: image: http://www.flickr.com/photos/erichews/2639564244/
- #8: image: http://www.flickr.com/photos/anshul/2313406717/
- #9: image: http://www.flickr.com/photos/sarkasmo/428860683/
- #11: Awesome Web 2.0 site selling hats for cats. In addition to the store...
- #12: Facebook app, online games, design-your-own hats, story writing with automatic creation of cat videos from your story, forums, blogs - you name it…
- #13: image: http://www.bride.net/wp-content/uploads/2008/02/cat-in-the-hat.gif
- #14: image: http://www.flickr.com/photos/abear23/1444321123/
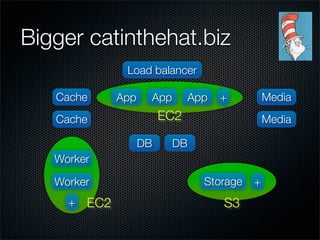
- #16: What happens when we get a bit bigger, and we start wanting more than one of anything? When we get load spikes and need 6 or 12 App servers, or 10 Workers rather than 2?
- #17: 1 worker or 20 workers should be the same to the client, and it should just work if the worker dies mid-process.
- #18: What components? background tasks, sessions,
- #19: REST services are a great example here - search
- #20: image: http://www.flickr.com/photos/ysgellery/3103708893/
- #21: Polling is a concern with many systems
- #22: image: http://www.flickr.com/photos/90001203@N00/172506278/
- #24: image: http://www.flickr.com/photos/75166820@N00/221373872/
- #25: image: http://www.flickr.com/photos/livinginmonrovia/85868861/
- #26: image: http://www.businessballs.com/project.htm
- #28: image: http://www.flickr.com/photos/donsolo/166981992/
- #29: Really easy with Twisted to add a SSH/Telnet shell
- #30: image: http://www.flickr.com/photos/dwstucke/6045801/
- #31: What happens when we get a bit bigger, and we start wanting more than one of anything? When we get load spikes and need 6 or 12 App servers, or 10 Workers rather than 2?
- #32: image: http://www.flickr.com/photos/whatknot/12974821/
- #33: $1.80/GB/year
- #34: Keys can be 1KB, and values(objects) can be up to 5GB
- #35: APIs for every language means its easy to incorporate into offline applications as well
- #36: Clever access control allows you to delegate authorization
- #37: Eventual consistency means that when your PUT request returns, it’ll be in at least 2 datacenters. But it might not be replicated across all of S3 yet, so an immediate GET request might return a not-found error. Likewise with 2 concurrent writes, it’ll take a while for (a random) one to win.
- #39: What happens when we get a bit bigger, and we start wanting more than one of anything? When we get load spikes and need 6 or 12 App servers, or 10 Workers rather than 2?
- #40: image: http://www.flickr.com/photos/phantomkitty/259379993/
- #42: Generating 60 million map tiles in a few hours for $40
- #43: Video encoding
- #44: Facebook apps with 300K users signing up in 24 hours
- #47: So now we can have as many App servers as needed, and as many Workers as needed
- #51: Used for indexing the web.
- #52: Geo-example: finding closest servo for any point on a road network