[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017)” and Neural Domain Adaptation
Download as PPTX, PDF13 likes5,391 views

DL輪読会で発表した資料です.“Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017)”を中心に最近のニューラルネットワーク×ドメイン適応の研究をまとめました.
![DEEP LEARNING JP
[DL Papers]
“Asymmetric Tri-training for Unsupervised Domain
Adaptation (ICML2017)” and Neural Domain Adaptation
Yusuke Iwasawa, Matsuo Lab
http://deeplearning.jp/](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-1-320.jpg)




![Introduction: Existing Methods and Its Cons
• 特徴量の分布P(Z)が近くなるようにする
– Sの分布Ps(Z) とTの分布Pt(Z)のずれをはかって,最小化
• Cons:P(Y|Z)が違えばDiscriminativeにならない
[Ganin, 2016] “Domain-Adversarial Training of Neural Networks”
6](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-6-320.jpg)

![Related Works: Summary of Existing Methods
• Not deep (Fixed feature space)
– [Gong, 2012] GFK
– [Baktashmotlagh, 2013] UDICA
– [Sun, 2016] CORAL
– Many
• Deep (Neural based, Flexible feature space)
– Feature Adaptation
– Classifier Adaptation (<- This Work)
• [Long, 2016] RTN (NIPS2016)
• [Sener, 2016] knn-Ad (NIPS2016)
• [Saito, 2017] ATDA (ICML2017)
8](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-8-320.jpg)
![Related Works: Feature Adaptation
Mathematical Foundation
[Ganin, 2016] “Domain-Adversarial Training of Neural Networks”
Visualization
[Ben-David, 2010] “A theory of learning from different domains”
ドメイン間の距離ソース損失
理想的なhを使うと
きの損失の差
9](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-9-320.jpg)
![Maximum Mean Discrepancy (MMD) [Tzeng, 2014]
• Sの事例間類似度 + Tの事例間の類似度 - SとTの間の類似度
• カーネルを使って計算(ガウシアンカーネルがよく使われているイメージ)
(Cited)https://www.dropbox.com/s/c8vhgrtjcqmz9yy/Gret
ton.pdf?dl=1
(Cited) [Tzeng, 2014]
10](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-10-320.jpg)
![Domain-Adversarial Neural Networks [Ganin, 2014]
• Zがどちらのドメインから来たのかを分類する分類器で測って最小化
• 分類器が識別出来ないような特徴空間に飛ばす
11](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-11-320.jpg)

![Recent Advance 1/3
Encoderを完全共有はやり過ぎでは?=>Unshared encoder
• S-D共通のEnc,SのEnc,DのEnc
• 共通Enc上での類似度(MMD or GAN)+各
ドメインでの再構成
• 特徴空間を近づける系でSOTAの1つ
• ※天才
[Tzeng, 2017] ADDA
(Adversarial Discriminative Domain Adaptation)
[Bousmalis, 2016] DSN
(Domain Separation Network)
• DANNのEnc部分を共有しない版
• S部分だけ事前学習できるのが強み
• DANNより良い
13](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-13-320.jpg)

![Recent Advance 3/3
P(Y|Z)も違う場合あるよね?=> Classifier Adaptation
[Long, 2016] RTN (Residual Transfer Network)
• Encは共有 + MMDでドメイン距離を近づける
• 工夫1:Sの分類器fsを,残差で表す(fS = fT + ⊿f)
• 工夫2: fTはTを使ったエントロピーでも訓練
• OfficeデータセットでSOTA(本研究は比較してない)
• ※工夫1が天才
• ※エントロピー正則化なくてもSOTAだけどあったほうが良い(ないとダメそうなので
不思議) 15](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-15-320.jpg)
![Classifier Adaptation
Mathematical Foundation
[Ben-David, 2010] “A theory of learning from different domains”
ドメイン間の距離ソース損失
理想的なhを使うと
きの損失の差
16
• C = Rs(h*) + Rt(h*)
• Cもちゃんと考慮したほうが良くない?という話
(普通はCは小さいと仮定している)](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-16-320.jpg)
![17
Feature Adaptation Classifier Adaptation?
Name Ref. Minimize By Means Enc unshared? Y/N By Means
DDC [Tzeng, 2014] E|P(Zs) – P(Zt)| MMD N N /
DDA [Long, 2015] E|P(Zs) – P(Zt)| MK-MMD N N /
DANN [Ganin, 2014] E|P(Zs)/P(Zt)| Adversarial N N /
CORAL [Sun, 2016] E|P(Zs) – P(Zt)| 2nd order moment N N /
VFAE [Louizos, 2016] E|P(Zs) – P(Zt)| MMD + Graphical N N /
AdaBN [Li, 2017] E|P(Zs) – P(Zt)| Domain-wise BN N N /
CMD [Zellinger, 2017] E|P(Zs) – P(Zt)| k-th order moment N N /
UPLDA [Bousmalis, 2016] E|P(Xs)/P(Xt)| GAN / N /
DSN [Bousmalis, 2016]
E|P(Zs) – P(Zt)|
or E|P(Zs)/P(Zt)| MMD or Adversarial Y N /
ADDA [Tzeng, 2017] E|P(Zs)/P(Zt)| Adversarial Y N /
KNN-Ad [Sener, 2016] ?? ?? ?? Y ??
RTN [Long, 2016] E|P(Zs) – P(Zt)| MMD N Y Residual Classifier
ATDA [Saito, 2017] / / N Y Tri-Training
DRCN [Ghifary, 2016] Implicit Reconstruction N N /
CoGAN [Liu, 2016] Implicit GAN Y N /
GTA [Swami, 2017] Implicit Conditional GAN N N /
- Feature
- Shared Enc
- Feature
- Unshared Enc
- Classifier
- Feature
- Implicit
Category](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-17-320.jpg)
![18
Feature Adaptation Classifier Adaptation?
Name Ref. Minimize By Means Enc unshared? Y/N By Means
DDC [Tzeng, 2014] E|P(Zs) – P(Zt)| MMD N N /
DDA [Long, 2015] E|P(Zs) – P(Zt)| MK-MMD N N /
DANN [Ganin, 2014] E|P(Zs)/P(Zt)| Adversarial N N /
CORAL [Sun, 2016] E|P(Zs) – P(Zt)| 2nd order moment N N /
VFAE [Louizos, 2016] E|P(Zs) – P(Zt)| MMD + Graphical N N /
AdaBN [Li, 2017] E|P(Zs) – P(Zt)| Domain-wise BN N N /
CMD [Zellinger, 2017] E|P(Zs) – P(Zt)| k-th order moment N N /
UPLDA [Bousmalis, 2016] E|P(Xs)/P(Xt)| GAN / N /
DSN [Bousmalis, 2016]
E|P(Zs) – P(Zt)|
or E|P(Zs)/P(Zt)| MMD or Adversarial Y N /
ADDA [Tzeng, 2017] E|P(Zs)/P(Zt)| Adversarial Y N /
KNN-Ad [Sener, 2016] ?? ?? ?? Y ??
RTN [Long, 2016] E|P(Zs) – P(Zt)| MMD N Y Residual Classifier
ATDA [Saito, 2017] / / N Y Tri-Training
DRCN [Ghifary, 2016] Implicit Reconstruction N N /
CoGAN [Liu, 2016] Implicit GAN Y N /
GTA [Swami, 2017] Implicit Conditional GAN N N /
<- Proposal](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-18-320.jpg)




![Add-ons 2/2 : Batch Normalization
• Fの最終層にBNを追加すると精度上がった
– ※他の研究 ([Sun et al., 2017]のAdaBN [Li et al., 2016]のCORAL)で似
たような効果が報告されていると書いてあったがやってること微妙に違う
と思う
– ※ただし,Sだけで学習する場合には精度悪化したらしいので意味があ
るのかもしれない
23](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-23-320.jpg)

![Experimental Setup: Others
[ネットワーク構造]
• Visualでは[Ganin, 2014]とほぼ同じ構造のCNNを利用
• Amazon Reviewでは[Ganin, 2016]とほぼおなじ構造を利用
[ハイパーパラメータ]
• λ: Visual->0.01, Review-> 0.001
• 学習率:[0.01, 0.05]
[評価方法]
• S -> 全部訓練に利用,T->一部を学習に利用?
• Tの一部を検証に使ったと書いてある
– ※良いの?と思ったけどドメイン適応系では一般にやるっぽい.ターゲットが使えな
いとハイパラをどうやって選ぶのかという問題があるため
– ※ DANNはTのラベルを使わないReverse cross-validationという方法を利用 25](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-25-320.jpg)






![[WIP] あんまり説明できなかった研究
• 系列のドメイン適応
– [Purushotam, 2017] VRADA
• Tを生成できるzはTの分類にも寄与する
– [Ghifary, 2016] Deep Reconstruction-Classification Network
– [Sankaranarayan, 2017] Generate To Adapt
– [Liu, 2016] CoGAN
• グラフィカルモデル的に独立性を定義
– [Louizos, 2016] Variational Fair AutoEncoder
33](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-33-320.jpg)

![[WIP] Common Dataset (not completed, not covered)
• Image
– MNIST-MNISTM
– MNIST-SVHN
– MNIST-USPS
– GTSRB: real world dataset of traffic sign (Domain separation netwroks)
– LINEMOD: CAD models of objects
– CFP (Celebrities in Frontal-Profile)
• Language
– Sentiment Analysis:
– Checkout [Huang, 2009]
• Others
– Healthcare:MIMIC-Ⅲ(not well known)
– Wifi dataset
35](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-35-320.jpg)
![[WIP] Citations and Comments
• [Glorot, 2011] “Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach”, ICML2011
– SとTのデータどちらも入れたAEによりTへの性能を検証
– DeepにするとよりTで性能上がる(Deepにするほどドメインの差が消えている)ことを示した
• [Long, 2015] “Learning Transferable Features”, NIPS2015
– MMDを多層に+マルチカーネルに(MK-MMD,Multi-Kernel MMD)
– 2015年時点でSOTA
• [Louizos, 2016] “Variational Fair Auto-Encoder”, ICLR2016
– 潜在変数zがドメインを識別する変数sと独立になるようにグラフィカルモデルを組んだ上で,VAEで表現
– それだけだと実際にはzとsが独立にならないので、MMDの項を追加
• [Ganin, 2016]
– 特徴空間Hにおけるドメインのずれを分類器で測る
– MMD系の手法よりこちらの方が精度高いことが多い (DSNとかでも超えてる)
– Proxy Α-distanceを近似していると考えることができる
• [Sanjay, 2017] “Variational Recurrent Adversarial Deep Domain Adaptation”, ICLR2017 Workshop
– DANNのエンコーダーをVRNNに
– 普通のRNN(LSTM)をエンコーダーにしたDANN(R-DANN)より良い
– R-DANNもDANNよりだいぶ良い
– 系列のドメイン適応を扱った珍しい論文
– 正直なぜLSTMをVRNNに変えると良いのかはよくわからない 36](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-36-320.jpg)
![[WIP]Reverse cross-validation
• DANNの論文で使われている
• 他ではあんまり使われてないが,ラベルが無いデータに対する交
差検証的な話
37](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-37-320.jpg)
![[WIP] その他の分野との比較
• 半教師あり学習
• 転移学習
• マルチタスク学習
• ドメイン汎化
38](https://image.slidesharecdn.com/dlhacks20170728-170728025901/85/DL-Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-ICML2017-and-Neural-Domain-Adaptation-38-320.jpg)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=560&fit=bounds)









![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=560&fit=bounds)

![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=560&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会] Controllable Invariance through Adversarial Feature Learning” (NIPS2017)](https://cdn.slidesharecdn.com/ss_thumbnails/20171121iwasawa-171120061515-thumbnail.jpg?width=560&fit=bounds)
Ad
More Related Content
What's hot (20)
Viewers also liked (11)
![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会] Semi-Supervised Knowledge Transfer For Deep Learning From Private Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170414iwasawa-170414094134-thumbnail.jpg?width=560&fit=bounds)
![[ICLR2016] 採録論文の個人的まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2016-acceptedpapers-160209033749-thumbnail.jpg?width=560&fit=bounds)



Ad
Similar to [DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017)” and Neural Domain Adaptation (20)



![[DL輪読会]Learning to Navigate in Cities Without a Map](https://cdn.slidesharecdn.com/ss_thumbnails/20180406iwasawa-180406030716-thumbnail.jpg?width=560&fit=bounds)







![[DL輪読会]Mastering the Dungeon: Grounded Language Learning by Mechanical Turker...](https://cdn.slidesharecdn.com/ss_thumbnails/180126groundedlanguagelearningbymechanicalturkerdecent1-180126004830-thumbnail.jpg?width=560&fit=bounds)








Ad
More from Yusuke Iwasawa (12)



![[DL輪読会] Hybrid computing using a neural network with dynamic external memory](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawadnc-161220014044-thumbnail.jpg?width=560&fit=bounds)

![[DL Hacks] Learning Transferable Features with Deep Adaptation Networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-20151105-iwasawa-160204020204-thumbnail.jpg?width=560&fit=bounds)
![[Paper Reading] Learning Distributed Representations for Structured Output Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/iwasawa-paperreading-20151014-160204014222-thumbnail.jpg?width=560&fit=bounds)
![[DL Hacks輪読] Semi-Supervised Learning with Ladder Networks (NIPS2015)](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-paper-reading-160107093848-thumbnail.jpg?width=560&fit=bounds)
![[DL Hacks] Self Paced Learning with Diversity](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0813-150820004116-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)



[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017)” and Neural Domain Adaptation
- 1. DEEP LEARNING JP [DL Papers] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017)” and Neural Domain Adaptation Yusuke Iwasawa, Matsuo Lab http://deeplearning.jp/
- 2. 書誌情報 • ICML2017 accepted • Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada • 選定理由: – 実世界のデータ使う時は大体訓練とテストが違う分布 =>ドメイン適応、大事(と個人的に思っている) – +分布の差を吸収する技術は本質的と思っている (生成モデルとか,シミュレータの活用とか) – 日本人で数少ないICML(12本?) • この論文を中心に最近のドメイン適応系の論文をまとめた – 本論文の本質と関係ないことも少し話します(主にRelated Work) 2
- 3. Introduction: ML under Domain Bias • DL含む多くの検証・一般的な学習理論は左を前提 • 一部の機械学習タスクはドメインバイアスがある(つまり右) – 訓練時と異なるユーザを対象とする,ユーザの行動が変化する – ドメインバイアスを無視すると,テストに対して精度が悪化 3 P(X, y) 訓練 データ テスト データ P(X, y) 訓練 データ テスト データ P’(X, y) w/oドメインバイアス w/ドメインバイアス ≒ 同じ真の分布から サンプルされたデータ 異なる真の分布から サンプルされたデータ
- 4. Introduction: Example of Domain Bias 4 http://vision.cs.uml.edu/adaptation.html
- 5. Introduction: Goal of Domain Adaptation • ソースSについては教師ありデータDs={Xs, ys} ~ Ps(X, y)が大量に 手に入る • ターゲットTについては教師なしデータDt= {Xt} ~ Pt(X)が手に入る が,ラベルデータは全く手に入らない • Ps(X, y)≠Pt(X, y) • Goal: DsとDtを使ってTに対する経験損失Rt(h)を抑える 5
- 6. Introduction: Existing Methods and Its Cons • 特徴量の分布P(Z)が近くなるようにする – Sの分布Ps(Z) とTの分布Pt(Z)のずれをはかって,最小化 • Cons:P(Y|Z)が違えばDiscriminativeにならない [Ganin, 2016] “Domain-Adversarial Training of Neural Networks” 6
- 7. Introduction: Proposal and Results • P(Y|Z)も適応させる方法を提案 – 擬似ラベルYt’をソースSのデータを使って構築する – Yt’を使ってターゲットTの分類器を構築 • 半教師の手法であるtri-trainingをドメイン適応に一般化 – 役割の異なる分類器2つ(F1, F2)をSで訓練 – F1, F2を使ってTをラベルづけ(疑似ラベルを付与) – 疑似ラベルを使ってTの分類器Ftを訓練 7
- 8. Related Works: Summary of Existing Methods • Not deep (Fixed feature space) – [Gong, 2012] GFK – [Baktashmotlagh, 2013] UDICA – [Sun, 2016] CORAL – Many • Deep (Neural based, Flexible feature space) – Feature Adaptation – Classifier Adaptation (<- This Work) • [Long, 2016] RTN (NIPS2016) • [Sener, 2016] knn-Ad (NIPS2016) • [Saito, 2017] ATDA (ICML2017) 8
- 9. Related Works: Feature Adaptation Mathematical Foundation [Ganin, 2016] “Domain-Adversarial Training of Neural Networks” Visualization [Ben-David, 2010] “A theory of learning from different domains” ドメイン間の距離ソース損失 理想的なhを使うと きの損失の差 9
- 10. Maximum Mean Discrepancy (MMD) [Tzeng, 2014] • Sの事例間類似度 + Tの事例間の類似度 - SとTの間の類似度 • カーネルを使って計算(ガウシアンカーネルがよく使われているイメージ) (Cited)https://www.dropbox.com/s/c8vhgrtjcqmz9yy/Gret ton.pdf?dl=1 (Cited) [Tzeng, 2014] 10
- 11. Domain-Adversarial Neural Networks [Ganin, 2014] • Zがどちらのドメインから来たのかを分類する分類器で測って最小化 • 分類器が識別出来ないような特徴空間に飛ばす 11
- 12. MMD系とDANN系(+その派生) • MMD系: 分布の差 Ps(Z) - Pt(Z)を計測 – DANN: マルチカーネルMMDを使う(MK-MMD) – VFAE: MMD+グラフィカルモデルでzとsの独立性を表現 – CORAL: 2nd order momentのみを合わせる – AdaBN: 平均と分散をドメインごとに計算して合わせるBN – CMD: k-th order momentまで計算して合わせる • DANN: 分布の比Ps(Z)/ Pt(Z)を計測 – KL-Divergence: KL(S|T) + KL (T|S),陽に1stモーメントを近づける ※どちらが良いかははっきりしてないと思う(例えば精度はMMD < DANN < CMD) ※GANみたいに比だと安定しないとかはあんまりない印 ※Wasserstainみたいな輸送距離が使われているのは見たことないけどどうなるのか気になる 12
- 13. Recent Advance 1/3 Encoderを完全共有はやり過ぎでは?=>Unshared encoder • S-D共通のEnc,SのEnc,DのEnc • 共通Enc上での類似度(MMD or GAN)+各 ドメインでの再構成 • 特徴空間を近づける系でSOTAの1つ • ※天才 [Tzeng, 2017] ADDA (Adversarial Discriminative Domain Adaptation) [Bousmalis, 2016] DSN (Domain Separation Network) • DANNのEnc部分を共有しない版 • S部分だけ事前学習できるのが強み • DANNより良い 13
- 14. Recent Advance 2/3 事例自体作っちゃえば?=>Adaptation on input spaces • Sで条件付けてTの偽データを作成 • Tの偽データ+Sで分類器を訓練(偽データがTと近くなってれば上手くいく) • (あんまり読んでない) 14
- 15. Recent Advance 3/3 P(Y|Z)も違う場合あるよね?=> Classifier Adaptation [Long, 2016] RTN (Residual Transfer Network) • Encは共有 + MMDでドメイン距離を近づける • 工夫1:Sの分類器fsを,残差で表す(fS = fT + ⊿f) • 工夫2: fTはTを使ったエントロピーでも訓練 • OfficeデータセットでSOTA(本研究は比較してない) • ※工夫1が天才 • ※エントロピー正則化なくてもSOTAだけどあったほうが良い(ないとダメそうなので 不思議) 15
- 16. Classifier Adaptation Mathematical Foundation [Ben-David, 2010] “A theory of learning from different domains” ドメイン間の距離ソース損失 理想的なhを使うと きの損失の差 16 • C = Rs(h*) + Rt(h*) • Cもちゃんと考慮したほうが良くない?という話 (普通はCは小さいと仮定している)
- 17. 17 Feature Adaptation Classifier Adaptation? Name Ref. Minimize By Means Enc unshared? Y/N By Means DDC [Tzeng, 2014] E|P(Zs) – P(Zt)| MMD N N / DDA [Long, 2015] E|P(Zs) – P(Zt)| MK-MMD N N / DANN [Ganin, 2014] E|P(Zs)/P(Zt)| Adversarial N N / CORAL [Sun, 2016] E|P(Zs) – P(Zt)| 2nd order moment N N / VFAE [Louizos, 2016] E|P(Zs) – P(Zt)| MMD + Graphical N N / AdaBN [Li, 2017] E|P(Zs) – P(Zt)| Domain-wise BN N N / CMD [Zellinger, 2017] E|P(Zs) – P(Zt)| k-th order moment N N / UPLDA [Bousmalis, 2016] E|P(Xs)/P(Xt)| GAN / N / DSN [Bousmalis, 2016] E|P(Zs) – P(Zt)| or E|P(Zs)/P(Zt)| MMD or Adversarial Y N / ADDA [Tzeng, 2017] E|P(Zs)/P(Zt)| Adversarial Y N / KNN-Ad [Sener, 2016] ?? ?? ?? Y ?? RTN [Long, 2016] E|P(Zs) – P(Zt)| MMD N Y Residual Classifier ATDA [Saito, 2017] / / N Y Tri-Training DRCN [Ghifary, 2016] Implicit Reconstruction N N / CoGAN [Liu, 2016] Implicit GAN Y N / GTA [Swami, 2017] Implicit Conditional GAN N N / - Feature - Shared Enc - Feature - Unshared Enc - Classifier - Feature - Implicit Category
- 18. 18 Feature Adaptation Classifier Adaptation? Name Ref. Minimize By Means Enc unshared? Y/N By Means DDC [Tzeng, 2014] E|P(Zs) – P(Zt)| MMD N N / DDA [Long, 2015] E|P(Zs) – P(Zt)| MK-MMD N N / DANN [Ganin, 2014] E|P(Zs)/P(Zt)| Adversarial N N / CORAL [Sun, 2016] E|P(Zs) – P(Zt)| 2nd order moment N N / VFAE [Louizos, 2016] E|P(Zs) – P(Zt)| MMD + Graphical N N / AdaBN [Li, 2017] E|P(Zs) – P(Zt)| Domain-wise BN N N / CMD [Zellinger, 2017] E|P(Zs) – P(Zt)| k-th order moment N N / UPLDA [Bousmalis, 2016] E|P(Xs)/P(Xt)| GAN / N / DSN [Bousmalis, 2016] E|P(Zs) – P(Zt)| or E|P(Zs)/P(Zt)| MMD or Adversarial Y N / ADDA [Tzeng, 2017] E|P(Zs)/P(Zt)| Adversarial Y N / KNN-Ad [Sener, 2016] ?? ?? ?? Y ?? RTN [Long, 2016] E|P(Zs) – P(Zt)| MMD N Y Residual Classifier ATDA [Saito, 2017] / / N Y Tri-Training DRCN [Ghifary, 2016] Implicit Reconstruction N N / CoGAN [Liu, 2016] Implicit GAN Y N / GTA [Swami, 2017] Implicit Conditional GAN N N / <- Proposal
- 19. Proposed Method: Asymmetric Tri-Training • 基本的には2つの分類器F1, F2を使ってTのデータXtの一部に疑似ラベルyt’付与 +{Xt, yt’ }を使ってTtを訓練 19
- 20. Prosed Method: Pseudo-Labeling Xt 1. C1 = C2 (maximum prob class) 2. α < Max(p1) and α < Max(p2) Then add pseud label C1 to Xt 20
- 21. Proposed Method: Algorithm Summary (1) Sを使ってiter回全てのネットワークを訓練 (2) Nt個を上限に疑似ラベルづけ(Tl) (3) L = S∪ Tlを使って訓練 - F, F1, F2をLで訓練 - F, FtをTlで訓練 (4)疑似ラベルを更新(3に戻る) 21
- 22. Add-ons 1/2 : Weight constrains • Weight constrains • 気持ちとしてはW1とW2が直交して欲しい (同じ予測をすると2つ用意している意味がない) • ※個人的には効いているのか不明だと思っている – 単に|W1|や|W2|を小さくしているだけでは? – 実験的にもそんなに貢献大きくない(表1) 22
- 23. Add-ons 2/2 : Batch Normalization • Fの最終層にBNを追加すると精度上がった – ※他の研究 ([Sun et al., 2017]のAdaBN [Li et al., 2016]のCORAL)で似 たような効果が報告されていると書いてあったがやってること微妙に違う と思う – ※ただし,Sだけで学習する場合には精度悪化したらしいので意味があ るのかもしれない 23
- 24. Experimental Setup: Adaptation Task • Visual – MNIST->MNIST-M – SVHN->MNIST – MNIST->SVHN – SYN DIGITS -> SVHN – SYN SIGNS -> GTSRB – ※ No evaluation on Office (because it requires additional dataset) • Amazon Review (Sentiment Analysis) – Type of products: books, DVDs, electronics, kitchen 24
- 25. Experimental Setup: Others [ネットワーク構造] • Visualでは[Ganin, 2014]とほぼ同じ構造のCNNを利用 • Amazon Reviewでは[Ganin, 2016]とほぼおなじ構造を利用 [ハイパーパラメータ] • λ: Visual->0.01, Review-> 0.001 • 学習率:[0.01, 0.05] [評価方法] • S -> 全部訓練に利用,T->一部を学習に利用? • Tの一部を検証に使ったと書いてある – ※良いの?と思ったけどドメイン適応系では一般にやるっぽい.ターゲットが使えな いとハイパラをどうやって選ぶのかという問題があるため – ※ DANNはTのラベルを使わないReverse cross-validationという方法を利用 25
- 26. Result: Visual • どのタスクでもSOTA • BNがないと精度落ちる • Weight Constrainはあったほうが良いが,そんなに変わらない 26
- 27. Result: Domain Invariance (MNIST-MNISTM)ProposalDANN Proxy A-distance※ ※分類器でSとTをどのくらい識別できるか. 今回は線形SVMを利用. • DANNみたいに明示的にDomain-Invarianceの獲得を目的にしてないけど良くなっている (という主張.個人的にはそんなに変わってないやんという気がする.) 27
- 28. Result: Amazon • Reviewでも大体提案手法が良い • VFAEはあんまり説明してないけど,簡 単に言えばVAE+MMD (グラフィカルモデルでzがドメインに依存 しないようにしている) 28
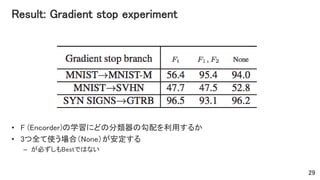
- 29. Result: Gradient stop experiment • F (Encorder)の学習にどの分類器の勾配を利用するか • 3つ全て使う場合(None)が安定する – が必ずしもBestではない 29
- 30. Result: Accuracy of Three Classifiers • 3つの分類器のTに対する精度がどのように 変化したか • どれも同じような変化 • ※え、じゃあFt意味ある?(個人的意見) • ※1つの設定しかなかったので他のデータ気 になる 30
- 31. Result: Labeling Accuracy and Classification Accuracy 31
- 32. 感想 • 個人的にはいくつか疑問(主に実験部分) – ラベル付きTをパラメタの探索に使っている=>ずるい (それでDANNみたいにラベル付きTを使ってないものと比べて良いのか) – 評価のやり方がどの論文読んでも違うのに数値比較して良いのか (既に観測済みの教師なし事例のみを対象にする場合もある) – いくつかの関連研究(この文献より精度良い)がなかったことになっている(Arxivだか ら良いと言えば良い気もするけど) – &めっちゃ関連するRTNが比較に入ってない – |W1 TW2|は本当に効くの?普通にやると単にノルム小さくなるだけでは? – 3つの分類器どれも似た精度になるならtri-trainingいらないのでは?(要は疑似ラベ ルでTのラベルデータも用意することが大事なのでは) • とはいえ良い論文 – 多くの研究が無視していた部分を考慮する方法を提案した貢献は大きい 32
- 33. [WIP] あんまり説明できなかった研究 • 系列のドメイン適応 – [Purushotam, 2017] VRADA • Tを生成できるzはTの分類にも寄与する – [Ghifary, 2016] Deep Reconstruction-Classification Network – [Sankaranarayan, 2017] Generate To Adapt – [Liu, 2016] CoGAN • グラフィカルモデル的に独立性を定義 – [Louizos, 2016] Variational Fair AutoEncoder 33
- 34. Deep Reconstruction-Classification Network (DRN) • SからTへの再構成誤差も追加,Tを生成できるzならきっとどちらにも使えるんじゃな い?という話(CoGANとかGenerate to Adaptとかが同じ思想だと思う) • SとTのalignmentをどうやってやるのかはパット見じゃわからなかった 34
- 35. [WIP] Common Dataset (not completed, not covered) • Image – MNIST-MNISTM – MNIST-SVHN – MNIST-USPS – GTSRB: real world dataset of traffic sign (Domain separation netwroks) – LINEMOD: CAD models of objects – CFP (Celebrities in Frontal-Profile) • Language – Sentiment Analysis: – Checkout [Huang, 2009] • Others – Healthcare:MIMIC-Ⅲ(not well known) – Wifi dataset 35
- 36. [WIP] Citations and Comments • [Glorot, 2011] “Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach”, ICML2011 – SとTのデータどちらも入れたAEによりTへの性能を検証 – DeepにするとよりTで性能上がる(Deepにするほどドメインの差が消えている)ことを示した • [Long, 2015] “Learning Transferable Features”, NIPS2015 – MMDを多層に+マルチカーネルに(MK-MMD,Multi-Kernel MMD) – 2015年時点でSOTA • [Louizos, 2016] “Variational Fair Auto-Encoder”, ICLR2016 – 潜在変数zがドメインを識別する変数sと独立になるようにグラフィカルモデルを組んだ上で,VAEで表現 – それだけだと実際にはzとsが独立にならないので、MMDの項を追加 • [Ganin, 2016] – 特徴空間Hにおけるドメインのずれを分類器で測る – MMD系の手法よりこちらの方が精度高いことが多い (DSNとかでも超えてる) – Proxy Α-distanceを近似していると考えることができる • [Sanjay, 2017] “Variational Recurrent Adversarial Deep Domain Adaptation”, ICLR2017 Workshop – DANNのエンコーダーをVRNNに – 普通のRNN(LSTM)をエンコーダーにしたDANN(R-DANN)より良い – R-DANNもDANNよりだいぶ良い – 系列のドメイン適応を扱った珍しい論文 – 正直なぜLSTMをVRNNに変えると良いのかはよくわからない 36
- 37. [WIP]Reverse cross-validation • DANNの論文で使われている • 他ではあんまり使われてないが,ラベルが無いデータに対する交 差検証的な話 37
- 38. [WIP] その他の分野との比較 • 半教師あり学習 • 転移学習 • マルチタスク学習 • ドメイン汎化 38