【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モデルによる少量プロンプト推論
Download as PPTX, PDF2 likes5,990 views

2022/10/14 Deep Learning JP http://deeplearning.jp/seminar-2/
![http://deeplearning.jp/
Flamingo: a Visual Language Model for Few-Shot Learning
画像×言語の大規模基盤モデルによる少量プロンプト推論
山本 貴之(ヤフー株式会社)
DEEP LEARNING JP
[DL Papers]
1](https://image.slidesharecdn.com/dl20221014flamingo-221017045003-37ecd353/85/DL-Flamingo-a-Visual-Language-Model-for-Few-Shot-Learning-x-1-320.jpg)








![関連研究 Perceiver モデルアーキテクチャ図 CrossAttention部
10
→ QKTを計算する為K入力をD次元にしCrossAttentionに入力
LayerNorm
Cross
Attention
Q
K
V
Q
MLP
D次元へ
K
MLP
D次元へ
V
MLP
C次元へ
MLP
Q次元へ
LayerNorm
N×C次元
N×D次元
潜在表現
系列長N× D次元
入力データ
系列長M× C次元
Residual経路
出力
※輪読者が公式実装を参考に作図
CrossAttentionでの次元数変化
Attention式 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑄𝐾𝑇
𝑑𝑘
𝑉
𝑄𝐾𝑇 →[N,D][D,M]→[N,M]
× 𝑉 →[N,M][M,C]→[N,C]
MLP→[N,D]
Attention式 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑄𝐾𝑇
𝑑𝑘
𝑉
M×D次元
M×C次元
N×D次元](https://image.slidesharecdn.com/dl20221014flamingo-221017045003-37ecd353/85/DL-Flamingo-a-Visual-Language-Model-for-Few-Shot-Learning-x-10-320.jpg)
























![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=560&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)






![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=560&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=560&fit=bounds)


Ad
More Related Content
What's hot (20)
Similar to 【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モデルによる少量プロンプト推論 (10)








Ad
More from Deep Learning JP (20)




















Ad
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モデルによる少量プロンプト推論
- 1. http://deeplearning.jp/ Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モデルによる少量プロンプト推論 山本 貴之(ヤフー株式会社) DEEP LEARNING JP [DL Papers] 1
- 2. 書誌情報 Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モデルによる少量プロンプト推論 https://arxiv.org/abs/2204.14198 タイトル: 著者: Jean-Baptiste Alayrac*, ‡, Jeff Donahue*, Pauline Luc*, Antoine Miech*, Iain Barr†, Yana Hasson†, Karel Lenc†, Arthur Mensch†, Katie Millican†, Malcolm Reynolds†, Roman Ring†, Eliza Rutherford†, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan*,‡ *Equal contributions, ordered alphabetically, †Equal contributions, ordered alphabetically, ‡Equal senior contributions GPT-3の画像×言語版 概要: 2 選定理由: 学習済の画像と言語のモデルを使い、それらをドメイン適応する手法に対する興味 (NeurIPS 2022 Poster) DeepMind 公式実装: なし ※出典記載の無い図表は本論文からの引用
- 4. Flamingoは何が出来るのか? 実例 4 画像とテキストを組み合わせたプロンプトを入力 → その続きのテキストを生成
- 5. Flamingoは何が出来るのか? ゼロショットで動画QAや画像チャット 5 画像チャット応答も可能 (左図) 画像の代わりに動画もOK (上図) ゼロショットQ&Aも可能
- 6. Flamingoのポイント 6 学習済モデルを 重み固定で利用 画像とテキスト間の ドメイン適応部を学習 画像/動画(=視覚)は 一定次元ベクトルに圧縮 汎用性を高めている 言語:サイズ70BのChinchilla (Hoffmann et al., 2022) 画像:サイズ435MのNFNet-F6(Brock et al., 2021) XAttn-Denseで言語と画像学習済モデルを結合 学習する部分 Flamingoオリジナルの構造の提案手法 画像/動画 & 自然言語 Andrew Brock, Soham De, Samuel L. Smith, and Karen Simonyan. High-performance largescale image recognition without normalization. arXiv:2102.06171, 2021. Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, JohannesWelbl, Aidan Clark, Eric Noland Tom Hennigan, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. Training compute-optimal large language models. arXiv:2203.15556, 2022. Perceiverで画像or動画を一定の潜在ベクトルに圧縮 学習する部分 関連研究として後述
- 7. 関連研究 Perceiver 長期時系列×高次元データの圧縮 7 全体アーキテクチャ図 (次のページから詳細説明)
- 8. 関連研究 Perceiver モデルアーキテクチャ図 入力部 8 潜在表現(圧縮先) 系列長N×各D次元 入力データ(圧縮元) 系列長M×各C次元 初期値はσ=0.02で -2~+2範囲のガウスノイズ Perceiver入力部抜粋 動画/画像など系列が長く高次元のデータ 潜在表現(N×D)に圧縮
- 9. 関連研究 Perceiver モデルアーキテクチャ図 全体 9 Cross Attention + Latent Transformerブロックの繰り返し(再帰的)構造 重みは共有する場合としない場合がある(任意) ブロック ブロック 繰返し数を レイヤー数と呼ぶ GPT-2アーキテクチャを利用 SelfAttention+Dense 系列N方向に平均し D次元のLogitsを生成
- 10. 関連研究 Perceiver モデルアーキテクチャ図 CrossAttention部 10 → QKTを計算する為K入力をD次元にしCrossAttentionに入力 LayerNorm Cross Attention Q K V Q MLP D次元へ K MLP D次元へ V MLP C次元へ MLP Q次元へ LayerNorm N×C次元 N×D次元 潜在表現 系列長N× D次元 入力データ 系列長M× C次元 Residual経路 出力 ※輪読者が公式実装を参考に作図 CrossAttentionでの次元数変化 Attention式 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾𝑇 𝑑𝑘 𝑉 𝑄𝐾𝑇 →[N,D][D,M]→[N,M] × 𝑉 →[N,M][M,C]→[N,C] MLP→[N,D] Attention式 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾𝑇 𝑑𝑘 𝑉 M×D次元 M×C次元 N×D次元
- 11. Flamingo モデルアーキテクチャ図 (全体) 11 画像と言語モデルは重み固定→破滅的忘却を防止 ピンク色部分のみを学習 画像入力 テキスト入力 テキスト出力
- 13. Flamingoモデルアーキテクチャ Vision Encoder & Perceiver Resampler 部 13 K,VにQもconcatしているのは、オリジナルPerceiverと違う Perceiverにより、様々なサイズの画像や動画に対応 どんな長さ×次元でもOK 潜在 画像 動画
- 15. Flamingo ドメイン適応 Gated X-Attention部 15 X-Attention 視覚系列入力 テキスト系列入力 ゲート機構 CrossAttention(X-Attention)で 視覚とテキストをドメイン適応 1 CrossAttentionはPerceiver構造 を参考にQとKVが別次元でもOK 2 ゲート機構がある(詳細後述) 3 LM layerとGATED XATTN-DENSE が複数層重なっている 4 系列長 64token
- 16. Flamingo ドメイン適応 Gate機構詳細 16 ゲート機構とは 学習するパラメータα(1次元)のレイヤーの事 αの初期値は0なので学習初期はResidual経路になる ゲート:tanh(α) Residual バイパス Residual バイパス tanh関数 ゲート出力を -1 ~ +1 にする為 ゲート:tanh(α)
- 17. Flamingo ドメイン適応 模擬コードでの理解 17 αは初期値0 学習により変化 アテンション出力 * tanh(α) + Residual
- 20. Flamingo 学習データセット (全てWEBスクレイプデータ) 20 Flamingo自体の学習データセット(言語と画像の学習済モデルではない) 名称 サイズ・内容 特徴 重みλ データイメージ M3W Multi-Modal Massive Web 43.3M instance テキスト容量 182GB 画像枚数 185M 複数画像がありインター リーブ学習に適している 1.0 VTP Video & Text Pairs 27M instance 動画テキストペア 動画 説明的なテキスト 比較的高品質 0.03 LTIP Long Text & Image Pairs 312M instance 画像テキストペア 長文で説明的なテキスト 比較的高品質 0.2 ALIGN A Large-scale ImaGe and Noisy-text 1,800M instance 画像テキストペア 低品質だが大量 画像とAlt-Text(短文) 0.2 ALIGNの画像出典:Jia, C., Yang, Y., Xia, Y., Chen, Y. T., Parekh, Z., Pham, H., ... & Duerig, T. (2021, July). Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning (pp. 4904-4916). PMLR.
- 22. Flamingoのモデル3種と学習時間等 22 項目 値 TPUチップ数 1,536個 日数 15日間 パラメータ数 806億(内、学習部分は102億) Flamingoのモデル3種(特に記載がない場合は最大モデルの事) 学習時間等
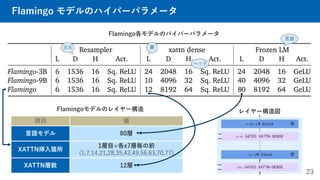
- 23. Flamingo モデルのハイパーパラメータ 23 項目 値 言語モデル 80層 XATTN挿入箇所 1層目+各x7層毎の前 (1,7,14,21,28,35,42,49,56,63,70,77) XATTN層数 12層 Flamingo各モデルのパイパーパラメータ Flamingoモデルのレイヤー構造 層 次元 ヘッド 言語 レイヤー構造図
- 26. 26 アブレーションスタディ Tanhゲート -4.4% 学習データmix -21.5% 基準(小モデル) X-ATTN構造 -11.0% Perceiver構造 -5.1% 言語モデル学習 -1.2% ・VANILLA XATTN:オリジナルTransformer ・Grafting:2022年論文で類似目的手法
- 27. まとめ 結論 Few-shotで画像/動画を理解する言語タスクに応用できるFlamingoモデルの紹介 Few-shotによる様々なタスクで最先端の性能を発揮 タスク固有のFineTuningを要する既存手法に対して、競争力のある性能を発揮 画像/動画に対するチャットQAのような対話能力は、従来手法を超える柔軟性 言語と視覚を橋渡しするFlamingoが、汎用的視覚理解への重要な一歩を踏み出した 27 感想 学習データの「質が重要」と記載があるが、そのデータはWEBスクレイプデータのみ →質を担保する手法が気になる 思ったよりドメイン適応学習が計算資源を使う為、ここがFew-shotで出来る手法がないか 大規模学習済モデルをリーズナブルに複数繋げられれば(ドメイン適応)、事業応用の幅が広がりそう