【DL輪読会】Hyena Hierarchy: Towards Larger Convolutional Language Models
Download as PPTX, PDF1 like1,785 views

2023/3/31 Deep Learning JP http://deeplearning.jp/seminar-2/





![関連研究(補足)
• Swin Transformer [Ze Liu et al. 2021]
– 省コストなViT
– 階層的な特徴表現により、入力画像サイズに対して線形な計算量
– 過去の輪読会でも紹介
https://www.slideshare.net/DeepLearningJP2016/dlswin-transformer-hierarchical-vision-transformer-using-shifted-windows
• Reformer [Nikita et al. 2020]
– 性能を保ちながらTransformerの効率を向上させるために2つの技術を導入
• ハッシュトリックを用いて 𝑂(𝐿2
) から 𝑂(𝐿𝑙𝑜𝑔𝐿) に
– ドット積アテンションを局所性を考慮したハッシュ関数で置き換え
• 標準的な残差の代わりに可逆的な残差層を使用
6](https://image.slidesharecdn.com/20230331dl-230410031231-28b7a2c2/85/DL-Hyena-Hierarchy-Towards-Larger-Convolutional-Language-Models-6-320.jpg)





















![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=560&fit=bounds)

![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=560&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=560&fit=bounds)


Ad
More Related Content
What's hot (20)
More from Deep Learning JP (20)


















Ad
【DL輪読会】Hyena Hierarchy: Towards Larger Convolutional Language Models
- 1. 1 Hyena Hierarchy: Towards Larger Convolutional Language Models Yuya TAKEDA, TMI M1
- 2. 書誌情報 • 著者 Michael Poli*, Stefano Massaroli*, Eric Nguyen*, Dan Fu, Tri Dao, Stephen A. Baccus, Yoshua Bengio, Stefano Ermon, and Chris Ré * Equal contribution. • 概要 – H3(Hungry Hungry Hippo )とGSS(Gated State Spaces)の一般化によるアーキテクチャ – Transformerを使わず、高速な推論が可能なLLMを構築可能 • 出典 – サイト https://hazyresearch.stanford.edu/blog/2023-03-07-hyena – 論文 https://arxiv.org/abs/2302.10866 – コード https://github.com/HazyResearch/safari 2
- 3. 書誌情報 • 選定理由 – LLMが盛り上がっている – Transformerを使わないLLMへの興味 – 専門は画像だが、言語のpoolformer的な 趣を感じた – ヨシュア・ベンジオ氏が著者に 名を連ねることでも話題に – 発表して間もなく、ITmedia でも取り上げられた 3
- 4. 背景 • Transformer – 時系列情報のモデル化のための強力なツール • ドメイン)言語、画像、音声、生物学、etc… – 計算コストが最も大きな制約 • シーケンス 𝐿 に対して 𝑂(𝐿2 ) で増加 – 2次の壁を破ることでDLに新たな可能性 • 例)本一冊の文脈を使用、長編音楽の生成、ギガピクセル画像の処理 4
- 5. 関連研究 • Attentionの計算コスト削減 – 線形化や低ランク行列の積、スパース化による近似 (Child et al., 2019; Wang et al., 2020; Kitaev et al., 2020; Zhai et al., 2021; Roy et al., 2021; Schlag et al., 2021; Tu et al., 2022) – 計算量と表現力はトレードオフ (Mehta et al., 2022; Dao et al., 2022c) • Attentionの演算子としての冗長性 – Attention機構が言語処理に利用しているのは、 二次的な能力のほんの一部とする証拠が増えている (Olsson et al., 2022; Dao et al., 2022c) 5
- 6. 関連研究(補足) • Swin Transformer [Ze Liu et al. 2021] – 省コストなViT – 階層的な特徴表現により、入力画像サイズに対して線形な計算量 – 過去の輪読会でも紹介 https://www.slideshare.net/DeepLearningJP2016/dlswin-transformer-hierarchical-vision-transformer-using-shifted-windows • Reformer [Nikita et al. 2020] – 性能を保ちながらTransformerの効率を向上させるために2つの技術を導入 • ハッシュトリックを用いて 𝑂(𝐿2 ) から 𝑂(𝐿𝑙𝑜𝑔𝐿) に – ドット積アテンションを局所性を考慮したハッシュ関数で置き換え • 標準的な残差の代わりに可逆的な残差層を使用 6
- 7. Attentionと計算コストに関する知見 • 大規模なAttentionの質に匹敵する2次以下の演算子 – 効率的な2次以下のプリミティブ • 長い畳み込み(入力と同じ長さのフィルターサイズを持つ畳み込み) • 要素ごとの乗算(ゲーティング) – これらを用いて以下を満たす様な演算子を提案 • 三つの特性 ターゲット推論タスクに基づ気、既存の2次以下のアプローチとAttentionの性能差に関連する – データ制御(入力で条件付け) – 2次以下のパラメータスケーリング(𝑂(𝐿2 ) 以下) – 無制限の文脈(局所性なしに任意の二点間の依存関係を近似) 7
- 8. 提案手法:Hyena hierarchy • Hyena演算子 – 暗黙の長い畳み込み ℎ (FFNによってパラメータ化されたHyenaフィルタ) と入力の要素ごとの乗算を再帰的に用いる • 再帰の深さは演算子の大きさを指定 – データ制御(入力 𝑢 によって条件付け)された、対角行列 𝐷𝑥 とテプリッツ行列 𝑆ℎ との乗算として等価に表現できる – 2次以下のパラメータスケーリングと無制限の文脈を示し、 より低い時間複雑性を有する 8 テプリッツ行列 ・各下降対角線に沿って要素が一定 ・𝐀𝐱 = 𝐛 の自由度は 2𝑛 − 1 (例) 𝑎 𝑏 𝑐 𝑑 𝑒 𝑓 𝑎 𝑏 𝑐 𝑑 𝑔 𝑓 𝑎 𝑏 𝑐 ℎ 𝑔 𝑓 𝑎 𝑏 𝑗 ℎ 𝑔 𝑓 𝑎 ・テプリッツ行列による離散畳み込み (2次の場合は二重循環行列を用いる) 参考:Bengioら「Deep Learning」 9.1節など
- 9. 提案手法:Hyena hierarchy • 2次以下の演算子 – Attention-Free Transformers(AFTs) • レイヤーは、ゲーティングと、SoftMax(AFT full)または単一の明示的な畳み込み(AFT conv)の 組み合わせによってオペレーターを構成 – Gated State Spaces(GSS) • ゲーティングと状態空間モデル(SSM)によってパラメータ化された長い畳み込みを 組み合わせてオペレーターを構成 – Hungry Hungry Hippo(H3) • GSSの欠点に着目して、追加のゲートとシフトSSMによって得られる 短い畳み込みを含めた機構を拡張 • Hyenaは、効率的に評価されるゲートと暗黙的な長い畳み込みの再帰を 導入することによって、AFTsとH3を一般化 9
- 10. 提案手法:Hyena hierarchy • Hyena演算子 – 定義 𝑣, 𝑥1 , . . . , 𝑥𝑁 を入力の写像、ℎ1 , . . . ℎ𝑁 を学習可能なフィルタの集合としたとき Hyena演算子は再帰的に以下の様に定義される(但し、簡単のため 𝐷 = 1) 𝑧𝑡 1 = 𝑣𝑡 𝑧𝑡 𝑛+1 = 𝑥𝑡 𝑛 (ℎ𝑛 ∗ 𝑧𝑛 )𝑡 𝑛 = 1, . . . , 𝑁 𝑦𝑡 = 𝑧𝑡 𝑁+1 – H3機構がベース – 再帰の時間計算量は 𝑂(𝑁𝐿𝑙𝑜𝑔𝐿) であり、入出力マップは 𝑦 = 𝑥𝑁 ⋅ (ℎ𝑁 ∗ (𝑥𝑁−1 ⋅ (ℎ𝑁−1 ∗ (⋯ )))) となり、各畳み込みはフーリエ領域を通して 𝑂(𝐿𝑙𝑜𝑔𝐿) で実行される 10 チャンネル数。 1だとSISOになる。
- 11. Hyenaの性能評価 • dence Attentionと2次以下の演算子との間の品質差 – Hyenaの設計はこの差を縮めることがモチベーション – これは、スケールでの言語モデリング性能と相関のある推論タスクに焦点を当 てることで特定される • 基本的な機械論的解釈可能性ベンチマークを拡張 – タスクの複雑さが増す(例えば語彙のサイズが大きくなる)と、 モデルの性能がどれだけ早く劣化するかを調査 – Hyenaの長い畳み込みの最適なパラメーターを調査 • 暗黙のパラメータ化スキームは50%以上の精度で改善 11
- 12. Hyenaの性能評価 • 言語と視覚のスケールアップ 推論ベンチマーク群におけるランキングが、スケールアップ時の品質を予測できるかどうかを検 証 – 10億以下のパラメータスケールでの自己回帰言語モデリングでHyenaをテスト – 335MパラメータスケールのTHE PILEでは計算量を20%削減 – ImageNet-1kでゼロから訓練した場合、精度でAttentionに匹敵 • 長いシーケンスに対するHyenaの効率性をベンチマーク – 長さ8192のdense Self Attentionに対して5倍 – 高度に最適化されたFlashAttentionに対して2倍 – 64kのシーケンス長ではFlashAttentionに対して100倍 ※ 64kはPyTorchの標準的なAttentionの実装がメモリ不足に陥る長さ 12
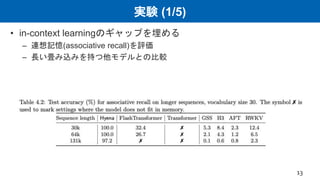
- 13. 実験 (1/5) • in-context learningのギャップを埋める – 連想記憶(associative recall)を評価 – 長い畳み込みを持つ他モデルとの比較 13
- 14. 実験 (2/5) • 言語モデリング – 自己回帰言語モデリングにおけるスケーリングの検証 – WIKITEXT103とTHE PTLEにおいてパープレキシティ(PPL)を評価 – AttentionなしでGPT-2に匹敵し、計算量は20%減
- 15. 実験 (3/5) • 下流タスク 質問応答(question answering)や読解などの言語理解に関するタスク – SuperGLUEで評価 – GPTNeo300B、RWKV332B、Hyena137Bで同性能 – few-shotも可能(MultiRCでは20%向上) 15 入手可能な中で 最高のAttention フリーモデル
- 16. 実験 (4/5) • 実行時間の比較 – ハイエナとFlashAttentionのクロスオーバーポイントは4096と8196の間 – Hyenaのハードウェア使用率がFlashAttentionより低いため、計算量の絶対的な 減少にもかかわらず、高速化が達成されるのはギャップが十分に大きくなった 長いシーケンスにおいてのみ • FFTConvの実装を改善し、専用のハードウェアを導入することで、理論上の最高 速度のギャップは縮小すると予想される 16
- 17. 実験 (5/5) • 大規模画像認識 – ViTのAttention層をHyenaにドロップイン置換 – 小さな画像バッチを使用する方がいずれのモデルも性能が向上 →ピクセルレベルに近づくほどHyenaが速度で勝ることが期待される – 2次元畳み込みモデルのS4NDでは、8%高速化し、25%パラメータ減 17
- 18. おわりに <まとめ> • 多くのLLMの中核をなす構成要素に、Attentionを必要としないドロップイン型の代替手段を導入 • Hyena演算子 – ゲーティングと暗黙のパラメトリックな長い対話の再帰 – 2次以下の時間で効率的 • THE PILEでのHyena – 非常に長いシーケンスに対してインコンテキストで学習可能 – Transformersの複雑さと下流性能に匹敵する、学習計算を大幅に削減した 最初のAttentionフリーの畳み込みアーキテクチャ <考察と結論> • 10億パラメータ以下のスケールでの有望な結果は、Attentionが ”all we need” ではないことを示唆 • モデル規模の拡大、推論速度の最適化による更なる性能に期待 18
- 19. おわりに • 感想 – モデル名ではなく、アーキテクチャと明記してあるのは、(大規模モデルの 学習に限らず、)Self Attentionを伴う計算に利用可能という点を強調するためか – xFormerの代替としての性能が気になる – LLMには動物名のモデルが多い ※ Hyenaはアーキテクチャ • Chinchilla • Gopher • Sparrow • LLaMA • Alpaca • Koala 19 Gopher (ホリネズミ)