[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Download as PPTX, PDF4 likes4,004 views

2021/05/14 Deep Learning JP: http://deeplearning.jp/seminar-2/
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Swin Transformer: Hierarchical Vision Transformer using
ShiftedWindows
Kazuki Fujikawa](https://image.slidesharecdn.com/swintransformer-210514020542/85/DL-Swin-Transformer-Hierarchical-Vision-Transformer-using-Shifted-Windows-1-320.jpg)





![関連研究
• Vision Transformer [Dosovitskiy+, ICLR2021]
– 入力画像をパッチ(画像の断片)に分割し、Transformerへ入力
• Patch Embedding: パッチ内のピクセルを1次元に並び替えた上で線形写像を取る
• Patch Embedding に Positional Encoding を加えることで、パッチの元画像内での位置を表現
7](https://image.slidesharecdn.com/swintransformer-210514020542/85/DL-Swin-Transformer-Hierarchical-Vision-Transformer-using-Shifted-Windows-7-320.jpg)
![関連研究
• Vision Transformer [Dosovitskiy+, ICLR2021]
– 課題: Self-Attention の計算コスト
• 画像内のすべてのPatchに対してAttentionの計算を行うため、計算コストは画像サイズに対して
二乗で増加する
8](https://image.slidesharecdn.com/swintransformer-210514020542/85/DL-Swin-Transformer-Hierarchical-Vision-Transformer-using-Shifted-Windows-8-320.jpg)










![実験: Object Detection
• 実験設定
– タスク
• COCO Object Detection
• 4種の主要な物体検出フレームワークのバックボーンに採用して実験
– Cascade Mask R-CNN [He+, 2016]
– ATSS [Zagoruyko+, 2016]
– RedPoints v2 [Chen+, 2020]
– Sparse RCNN [Sun+, 2020]
20](https://image.slidesharecdn.com/swintransformer-210514020542/85/DL-Swin-Transformer-Hierarchical-Vision-Transformer-using-Shifted-Windows-20-320.jpg)















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=560&fit=bounds)


![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=560&fit=bounds)



![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=560&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=560&fit=bounds)


Ad
More Related Content
What's hot (20)
Similar to [DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (20)
![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=560&fit=bounds)
![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=560&fit=bounds)
![[チュートリアル講演]画像データを対象とする情報ハイディング〜JPEG画像を利用したハイディング〜](https://cdn.slidesharecdn.com/ss_thumbnails/slideupload-130524001604-phpapp02-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=560&fit=bounds)



![[AI05] 目指せ、最先端 AI 技術の実活用!Deep Learning フレームワーク 「Microsoft Cognitive Toolkit 」...](https://cdn.slidesharecdn.com/ss_thumbnails/ai05-170602095345-thumbnail.jpg?width=560&fit=bounds)









Ad
More from Deep Learning JP (20)




















Ad
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 1. 1 DEEP LEARNING JP [DL Papers] http://deeplearning.jp/ Swin Transformer: Hierarchical Vision Transformer using ShiftedWindows Kazuki Fujikawa
- 2. サマリ • 書誌情報 – Swin Transformer: Hierarchical Vision Transformer using Shifted Windows • Arxiv:2103.14030 • Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo (Microsoft Research Asia) • 概要 – CVの汎用バックボーン: Swin Transformerを提案 • Transformerの画像への適用で課題になる、画像サイズ対して二乗で計算量が増える問題を 線形の増加に緩和 – モデルの複雑度・速度のトレードオフで良好な結果を確認 • Object Detection, Semantic Segmentation タスクで SoTA 2
- 3. アウトライン • 背景 • 関連研究 • 提案手法 • 実験・結果 3
- 4. アウトライン • 背景 • 関連研究 • 提案手法 • 実験・結果 4
- 5. 背景 • Tranformerベースのアーキテクチャは、NLPではデファクトスタンダードと なり、CVの世界でも活用可能であることが報告されている • Transformerを言語から画像へ適用する際の課題として、解像度の問題が 挙げられる – 画像における解像度は、自然言語におけるトークン数と比較して、スケールの変化が大きい – Self-Attentionは解像度に対して二乗の計算コストを要する 5 画像サイズに対してスケーラブルな Transformerアーキテクチャを考えたい!
- 6. アウトライン • 背景 • 関連研究 • 提案手法 • 実験・結果 6
- 7. 関連研究 • Vision Transformer [Dosovitskiy+, ICLR2021] – 入力画像をパッチ(画像の断片)に分割し、Transformerへ入力 • Patch Embedding: パッチ内のピクセルを1次元に並び替えた上で線形写像を取る • Patch Embedding に Positional Encoding を加えることで、パッチの元画像内での位置を表現 7
- 8. 関連研究 • Vision Transformer [Dosovitskiy+, ICLR2021] – 課題: Self-Attention の計算コスト • 画像内のすべてのPatchに対してAttentionの計算を行うため、計算コストは画像サイズに対して 二乗で増加する 8
- 9. アウトライン • 背景 • 関連研究 • 提案手法 • 実験・結果 9
- 10. 提案手法: Swin Transformer • 以下の3モジュールで構成 – Patch Partition + Linear embedding – Swin Transformer Block • Window based Multihead Self-Attention (W-MSA) • Shifted window based Multihead Self-Attention (SW-MSA) – Patch Merging 10
- 11. 提案手法: Swin Transformer • Patch Partition + Linear embedding – Patch Embedding の 計算は Vision Transformer と同様 • パッチへの分割 → 線形写像 11
- 12. 提案手法: Swin Transformer • Window based Multihead Self-Attention(W-MSA) – 画像をパッチに分割後、パッチの集合であるウィンドウを定義 – Window内のパッチに対してのみ、Self-Attentionで参照する • → Self-Attentionの計算コストは画像サイズの大きさに対して線形に増加 12 Patch (e.g. 4x4 pixel) Window (e.g. 4x4 patch) Swin Transformer Block
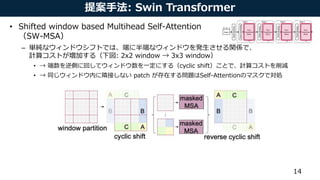
- 13. 提案手法: Swin Transformer • Shifted window based Multihead Self-Attention (SW-MSA) – W-MSA では、ウィンドウ間の関係性をモデリングできない • → ウィンドウをシフトさせ、ウィンドウ間の関係性をモデリングできるようにした • (下図: 縦方向に2patch, 横方向に2patch, ウィンドウをシフトしている) 13 Swin Transformer Block
- 14. 提案手法: Swin Transformer • Shifted window based Multihead Self-Attention (SW-MSA) – 単純なウィンドウシフトでは、端に半端なウィンドウを発生させる関係で、 計算コストが増加する(下図: 2x2 window → 3x3 window) • → 端数を逆側に回してウィンドウ数を一定にする(cyclic shift)ことで、計算コストを削減 • → 同じウィンドウ内に隣接しない patch が存在する問題はSelf-Attentionのマスクで対処 14
- 15. 提案手法: Swin Transformer • Patch Merging – Swin Transformer Block を数層重ねた後、隣接する 2x2 の patch を統合する • Pixel embedding 同様、2x2 の patch を 1次元に並び替えて線形写像を取る • その後の Swin Transformer Blockでは Window 内の patch 数は一定に保つため、 計算コストはそのままで広範な範囲に対して Self-Attention を計算することになる 15
- 16. アウトライン • 背景 • 関連研究 • 提案手法 • 実験・結果 16
- 17. 実験: Image Classification • 実験設定 – アーキテクチャ: レイヤー数、チャネル数の異なる複数のモデルを定義 • Swin-T: C = 96, layer numbers = {2, 2, 6, 2} • Swin-S: C = 96, layer numbers = {2, 2, 18, 2} • Swin-B: C = 128, layer numbers = {2, 2, 18, 2} • Swin-L: C = 192, layer numbers = {2, 2, 18, 2} – タスク • ImageNet 1000クラス分類のタスク(train: 1.23M)をスクラッチで学習 • 他のモデルで同様の複雑度(パラメータ数・速度)のものと比較して評価 17
- 18. 実験: Image Classification • 実験結果 – SoTA の Transformer ベースのアーキテクチャ(DeiT)に対し、同様の複雑度で良い パフォーマンスを実現 – SoTA の CNN ベースのアーキテクチャ(RegNet, EfficientNet)に対し、速度-精度の トレードオフでわずかに改善 18
- 19. 実験: Image Classification • 実験結果 – SoTA の Transformer ベースのアーキテクチャ(DeiT)に対し、同様の複雑度で良い パフォーマンスを実現 – SoTA の CNN ベースのアーキテクチャ(RegNet, EfficientNet)に対し、速度-精度の トレードオフでわずかに改善 19
- 20. 実験: Object Detection • 実験設定 – タスク • COCO Object Detection • 4種の主要な物体検出フレームワークのバックボーンに採用して実験 – Cascade Mask R-CNN [He+, 2016] – ATSS [Zagoruyko+, 2016] – RedPoints v2 [Chen+, 2020] – Sparse RCNN [Sun+, 2020] 20
- 21. 実験: Object Detection • 実験結果 – いずれの物体検出フレームワークでもベースライン(ResNet50)からの改善を確認 – Transformerベースのバックボーン: DeiT と比較して、精度と共に速度も改善 – SoTAモデルとの比較でも改善を確認 21
- 22. 実験: Object Detection • 実験結果 – いずれの物体検出フレームワークでもベースライン(ResNet50)からの改善を確認 – Transformerベースのバックボーン: DeiT と比較して、精度と共に速度も改善 – SoTAモデルとの比較でも改善を確認 22
- 23. 実験: Object Detection • 実験結果 – いずれの物体検出フレームワークでもベースライン(ResNet50)からの改善を確認 – Transformerベースのバックボーン: DeiT と比較して、精度と共に速度も改善 – SoTAモデルとの比較でも改善を確認 23
- 24. 実験: Semantic Segmentation • 実験設定 – タスク: ADE20K • 実験結果 – DeiTの同等の複雑度のモデルより高速で、高精度の予測ができることを確認 – SoTAモデル(SETR)より少ないパラメータで、高精度な予測ができることを確認 24
- 25. 実験: Semantic Segmentation • 実験設定 – タスク: ADE20K • 実験結果 – DeiTの同等の複雑度のモデルより高速で、高精度の予測ができることを確認 – SoTAモデル(SETR)より少ないパラメータで、高精度な予測ができることを確認 25
- 26. 結論 • CVの汎用バックボーン: Swin Transformerを提案 – Transformerの画像への適用で課題になる、画像サイズの増加に対して二乗で計算量が 増える問題を線形の増加に緩和 • モデルの複雑度・速度のトレードオフで良好な結果を確認 – Object Detection, Semantic Segmentation タスクで SoTA 26
- 27. References • Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." arXiv preprint arXiv:2103.14030 (2021). • Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." In ICLR2021. 27