DMTM Lecture 05 Data representation
1 like383 views

Il documento fornisce una panoramica sulla rappresentazione e l'analisi dei dati, affrontando concetti di mining dei dati, tipi di attributi e gestione dei valori mancanti. Viene discussa la struttura matriciale dei dati, evidenziando la distinzione tra istanze e attributi, e si analizzano metodi per affrontare le informazioni incomplete. Inoltre, il documento esplora il formato ARFF per la rappresentazione dei dati e altre risorse pubbliche di dati.














































DMTM Lecture 05 Data representation
- 1. Prof. Pier Luca Lanzi Data Representation Data Mining andText Mining (UIC 583 @ Politecnico di Milano)
- 2. Prof. Pier Luca Lanzi Readings • “Data Mining and Analysis” – Chapter 1 • “Mining of Massive Datasets” – Chapter 1 2
- 3. Prof. Pier Luca Lanzi syllabusdescribing data
- 4. Prof. Pier Luca Lanzi Contact Lenses Data 4 NoneReducedYesHypermetropePre-presbyopic NoneNormalYesHypermetropePre-presbyopic NoneReducedNoMyopePresbyopic NoneNormalNoMyopePresbyopic NoneReducedYesMyopePresbyopic HardNormalYesMyopePresbyopic NoneReducedNoHypermetropePresbyopic SoftNormalNoHypermetropePresbyopic NoneReducedYesHypermetropePresbyopic NoneNormalYesHypermetropePresbyopic SoftNormalNoHypermetropePre-presbyopic NoneReducedNoHypermetropePre-presbyopic HardNormalYesMyopePre-presbyopic NoneReducedYesMyopePre-presbyopic SoftNormalNoMyopePre-presbyopic NoneReducedNoMyopePre-presbyopic hardNormalYesHypermetropeYoung NoneReducedYesHypermetropeYoung SoftNormalNoHypermetropeYoung NoneReducedNoHypermetropeYoung HardNormalYesMyopeYoung NoneReducedYesMyopeYoung SoftNormalNoMyopeYoung NoneReducedNoMyopeYoung Recommended lensesTear production rateAstigmatismSpectacle prescriptionAge
- 5. Prof. Pier Luca Lanzi Data Representation • Data are typically abstracted as a matrix, with n rows and d columns, given as • Rows are called instances, examples, records, transactions, objects, points, feature-vectors, etc. • Columns are called attributes, properties, features, dimensions, variables, fields, etc. 5
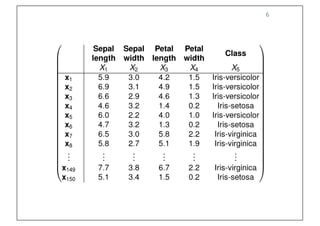
- 6. Prof. Pier Luca Lanzi 6
- 7. Prof. Pier Luca Lanzi Instances, Attributes, Concepts • Instances (observations, case) § The atomic elements of information from a dataset § Also known as records, prototypes, or examples • Attributes (variable) § Measures aspects of an instance § Also known as features or variables § Each instance is composed of a certain number of attributes • Concepts § Special content inside the data § Kind of things that can be learned § Intelligible and operational concept description 7
- 8. Prof. Pier Luca Lanzi Two Versions of the Weather Data 8 …………… YesFalseNormalMildRainy YesFalseHighHotOvercast NoTrueHighHotSunny NoFalseHighHotSunny PlayWindyHumidityTemperatureOutlook …………… YesFalse8075Rainy YesFalse8683Overcast NoTrue9080Sunny NoFalse8585Sunny PlayWindyHumidityTemperatureOutlook
- 9. Prof. Pier Luca Lanzi syllabusattribute types
- 10. Prof. Pier Luca Lanzi Attributes • Numeric Attributes §Real-valued or integer-valued domain §Interval-scaled when only differences are meaningful (e.g., temperature) §Ratio-scaled when differences and ratios are meaningful (e.g., Age) • Categorical Attributes §Set-valued domain composed of a set of symbols §Nominal when only equality is meaningful (e.g., domain(Sex) = { M, F}) §Ordinal when both equality (are two values the same?) and inequality (is one value less than another?) are meaningful (e.g., domain(Education) = { High School, BS, MS, PhD}) 10
- 11. Prof. Pier Luca Lanzi Numerical Attributes • Not only ordered but measured in fixed and equal units • Examples §Attribute “temperature” expressed in degrees §Attribute “year” • Characteristics §Difference of two values makes sense §Sum or product doesn’t make sense §Zero point is not defined • Sometimes they are divided into “discrete” and “continuous” 11
- 12. Prof. Pier Luca Lanzi Nominal Attributes (or Categorical) • Values are distinct symbols • Values themselves serve only as labels or names • Example §Attribute “outlook” from weather data §Values: “sunny”, “overcast”, and “rainy” • Characteristics §No relation is implied among nominal values §No ordering §No distance measure §Only equality tests can be performed 12
- 13. Prof. Pier Luca Lanzi Other Types of Attributes • Ratio Attributes §Numerical attributes for which the measurement scheme defines a zero point (e.g., an attribute representing distance) • Ordinal Attributes §Categorical attributes with an imposed order on values §No distance between values defined §For instance, the attribute “temperature” in weather data “hot” > “mild” > “cool” 13
- 14. Prof. Pier Luca Lanzi Nominal or Ordinal? • Attribute “age” nominal §If age = young and astigmatic = no and tear production rate = normal then recommendation = soft • Attribute “age” ordinal (e.g. “young” < “pre-presbyopic” < “presbyopic”) §If age≤pre-presbyopic and astigmatic = no and tear production rate = normal then recommendation = soft 14
- 15. Prof. Pier Luca Lanzi Why Specifying Attribute Types? • Some algorithms fit some specific data types best • Express the best possible patterns into data • Make the most adequate comparisons • Example §Outlook > “sunny” does not make sense, while §Temperature > “cool” or §Humidity > 70 does • Additional uses of attribute type §Check for valid values §Deal with missing values, etc. 15
- 16. Prof. Pier Luca Lanzi syllabusmissing values
- 17. Prof. Pier Luca Lanzi Why Missing Values Exist? • Faulty equipment, incorrect measurements, missing cells in manual data entry, censored/anonymous data • Review scores for movies, books, etc. • Very frequent in questionnaires for medical scenarios • Censored/anonymous data • In practice, a low rate of missing values may be suspicious • Interview data (“Did you ever …”) 17
- 18. Prof. Pier Luca Lanzi Missing Values • Frequently indicated by out-of-range entries (e.g. max/min float), Nan or special values (e.g., zero) • Missing value may have significance in itself §E.g. missing test in a medical examination • Most schemes assume that is not the case §“missing” may need to be coded as additional value • Does absence of value have some significance? §If it does, “missing” is a separate value §If it does not, “missing” must be treated in a special way 18
- 19. Prof. Pier Luca Lanzi What Types of Missing Values? • Missing completely at random (MCAR) § The distribution of an example having a missing value for an attribute does not depend on either the observed data or the missing data § Example: some survey questions contain a random sample of the whole questionnaire • Missing at random (MAR) § The distribution of an example having a missing value for an attribute depends on the observed data, but does not depend on the missing data § Missing at Random means the propensity for a data point to be missing is not related to the missing data, but it is related to some of the observed data § Whether or not someone answered #13 on your survey has nothing to do with the missing values, but it does have to do with the values of some other variable § For example, people who don’t declare their salary not because of the amount of it but just because they don’t want to. • Not missing at random (NMAR) § The distribution of an example having a missing depends on the missing values. § For example, respondents with high income less likely to report income • Note that NMAR and MAR might be difficult to identify and often require domain knowledge 19
- 20. Prof. Pier Luca Lanzi Dealing with Missing Values • Use what you know § Why data is missing § Distribution of missing data • Decide on the best strategy to yield the least biased estimates § Deletion Methods (listwise deletion, pairwise deletion) § Single Imputation Methods (mean/mode substitution, dummy variable method, single regression) § Model-Based Methods (maximum Likelihood, multiple imputation 20
- 21. Prof. Pier Luca Lanzi Strategies for missing values handling • The handling of missing data depends on the type • Discarding all the examples with a missing values § Simplest approach § Allows the use of unmodified data mining methods § Only practical if there are few examples with missing values. Otherwise, it can introduce bias • Fill in the missing value manually J • Convert the missing values into a new value § Use a special value for it § Add an attribute that indicates if value is missing or not § Greatly increases the difficulty of the data mining process • Imputation methods § Assign a value to the missing one, based on the rest of the dataset. Use the unmodified data mining methods. 21
- 22. Prof. Pier Luca Lanzi Listwise Deletion (Complete Case Analysis) • Only analyze cases with available data on each variable • Simple, but reduces the data • Comparability across analyses • Does not use all the information • Estimates may be biased if data not MCAR 22
- 23. Prof. Pier Luca Lanzi Pairwise deletion (Available Case Analysis) • Analysis with all cases in which the variables of interest are present • Advantage §Keeps as many cases as possible for each analysis §Uses all information possible with each analysis • Disadvantage §Can’t compare analyses because sample different each time 23
- 24. Prof. Pier Luca Lanzi Imputation methods • Extract a model from the dataset to perform the imputation • Suitable for MCAR and, to a lesser extent, for MAR • Not suitable for NMAR type of missing data • For NMAR we need to go back to the source of the data to obtain more information • Survey of imputation methods available at http://sci2s.ugr.es/MVDM/index.php http://sci2s.ugr.es/MVDM/biblio.php 24
- 25. Prof. Pier Luca Lanzi Single Imputation Methods • Mean/mode substitution (most common value) § Replace missing value with sample mean or mode § Run analyses as if all complete cases § Advantages: Can use complete case analysis methods § Disadvantages: Reduces variability • Dummy variable control § Create an indicator for missing value (1=value is missing for observation; 0=value is observed for observation) § Impute missing values to a constant (such as the mean) § Include missing indicator in the algorithm § Advantage: uses all available information about missing observation § Disadvantage: results in biased estimates, not theoretically driven • Regression Imputation § Replaces missing values with predicted score from a regression equation. 25
- 26. Prof. Pier Luca Lanzi Do Not Impute (DNI) • Simply use the default policy of the data mining method • Works only if the policy exists 26
- 27. Prof. Pier Luca Lanzi syllabusinaccurate values
- 28. Prof. Pier Luca Lanzi Inaccurate Values • Data has not been collected for mining it • Errors and omissions that don’t affect original purpose of data (e.g. age of customer) • Typographical errors in nominal attributes, thus values need to be checked for consistency • Typographical and measurement errors in numeric attributes, thus outliers need to be identified • Errors may be deliberate (e.g. wrong zip codes) 28
- 29. Prof. Pier Luca Lanzi syllabusthe geometric view
- 30. Prof. Pier Luca Lanzi The Geometrical View of the Data • When the data matrix contains only numerical values §Every row can be viewed as a point in a d-dimension space §Every column as a point in a n-dimensional space 30
- 31. Prof. Pier Luca Lanzi 31
- 32. Prof. Pier Luca Lanzi
- 33. Prof. Pier Luca Lanzi syllabusthe probabilistic view
- 34. Prof. Pier Luca Lanzi
- 35. Prof. Pier Luca Lanzi
- 36. Prof. Pier Luca Lanzi syllabusdata format
- 37. Prof. Pier Luca Lanzi Data Format • Most commercial tools have their own proprietary format • Most tools import excel files and comma-separated value files 37 Year,Make,Model,Length 1997,Ford,E350,2.34 2000,Mercury,Cougar,2.38 Year;Make;Model;Length 1997;Ford;E350;2,34 2000;Mercury;Cougar;2,38
- 38. Prof. Pier Luca Lanzi Attribute-Relation File Format (ARFF) 38 % % ARFF file for weather data with some numeric features % @relation weather @attribute outlook {sunny, overcast, rainy} @attribute temperature numeric @attribute humidity numeric @attribute windy {true, false} @attribute play? {yes, no} @data sunny, 85, 85, false, no sunny, 80, 90, true, no overcast, 83, 86, false, yes ... http://www.cs.waikato.ac.nz/~ml/weka/arff.html
- 39. Prof. Pier Luca Lanzi Additional Attribute Types • ARFF supports string attributes: • Similar to nominal attributes but list of values is not pre-specified • ARFF also supports date attributes: • Uses the ISO-8601 combined date and time format yyyy-MM-dd-THH:mm:ss 39 @attribute description string @attribute today date
- 40. Prof. Pier Luca Lanzi Additional Attribute Types • ARFF supports sparse data, for instance the following examples, • Can also be represented as, 40 0, 26, 0, 0, 0 ,0, 63, 0, 0, 0, “class A” 0, 0, 0, 42, 0, 0, 0, 0, 0, 0, “class B” {1 26, 6 63, 10 “class A”} {3 42, 10 “class B”}
- 41. Prof. Pier Luca Lanzi Missing Values in ARFF 41 @relation labor @attribute 'duration' real @attribute 'wage-increase-first-year' real @attribute 'wage-increase-second-year' real @attribute 'wage-increase-third-year' real @attribute 'cost-of-living-adjustment' {'none','tcf','tc'} @attribute 'working-hours' real @attribute 'pension' {'none','ret_allw','empl_contr'} @attribute 'standby-pay' real @attribute 'shift-differential' real @attribute 'education-allowance' {'yes','no'} @attribute 'statutory-holidays' real @attribute 'vacation' {'below_average','average','generous'} @attribute 'longterm-disability-assistance' {'yes','no'} @attribute 'contribution-to-dental-plan' {'none','half','full'} @attribute 'bereavement-assistance' {'yes','no'} @attribute 'contribution-to-health-plan' {'none','half','full'} @attribute 'class' {'bad','good'} @data 1,5,?, ?, ?,40, ?, ?,2, ?,11,'average', ?, ?,'yes',?,'good' 2,4.5,5.8, ?, ?,35,'ret_allw', ?, ?,'yes',11,'below_average', ?,'full', ?,'full','good' ?, ?, ?, ?, ?,38,'empl_contr', ?,5, ?,11,'generous','yes','half','yes','half','good' 3,3.7,4,5,'tc', ?, ?, ?, ?,'yes', ?, ?, ?, ?,'yes', ?,'good'
- 42. Prof. Pier Luca Lanzi Attribute Types and Interpretation • Interpretation of attribute types in ARFF depends on the mining scheme • Numeric attributes are interpreted as §Ordinal scales if less-than and greater-than are used §Ratio scales if distance calculations are performed (normalization/standardization may be required) • Instance-based schemes define distance between nominal values (0 if values are equal, 1 otherwise) • Integers in some given data file: nominal, ordinal, or ratio scale? 42
- 43. Prof. Pier Luca Lanzi DSPL: Dataset Publishing Language • Open format by Google available at http://code.google.com/apis/publicdata/ • Use existing data: add an XML metadata file existing CSV • Read by the Google Public Data Explorer, which includes animated bar chart, motion chart, and map visualization • Allow linking to concepts in other datasets • Geo-enabled: allows adding latitude and longitude data to your concept definitions 43
- 44. Prof. Pier Luca Lanzi syllabusmodel representation
- 45. Prof. Pier Luca Lanzi Predictive Model Markup Language • XML-based markup language developed by the Data Mining Group (DMG) to provide a way for applications to define models related to predictive analytics and data mining • The goal is to share models between applications • Vendor-independent method of defining models • Allow to exchange of models between applications. • PMML Components: data dictionary, data transformations, model, mining schema, targets, output 45
- 46. Prof. Pier Luca Lanzi syllabusdata repositories
- 47. Prof. Pier Luca Lanzi Publicly Available Datasets • UCI repository §http://archive.ics.uci.edu/ml/ §Probably the most famous collection of datasets • Kaggle §http://www.kaggle.com/ §It is not a static repository of datasets, but a site that manages Data Mining competitions §Example of the modern concept of crowdsourcing • KDNuggets §http://www.kdnuggets.com/datasets/ 47