Dremel interactive analysis of web scale datasets
Download as PPTX, PDF0 likes660 views

Dremel is an interactive query system that can analyze large web-scale datasets containing trillions of records in seconds. It uses a columnar data layout and multi-level query execution trees to distribute queries across thousands of servers. Dremel's nested data model and column-striped storage allows it to efficiently retrieve and analyze only the necessary columns from large datasets. Experimental results demonstrated Dremel's ability to process queries over datasets containing trillions of records and petabytes of data in seconds using a cluster of thousands of servers.










![Data Model
• The data model originated in the context of distributed systems (Protocol
Buffers), is used widely at Google, and is available as an open source
implementation.
• The data model is based on strongly-typed nested records.
Its abstract syntax is given by:
𝝉 = dom | < A1 : 𝝉[∗|?], ..., An : 𝝉[∗|?] >](https://image.slidesharecdn.com/dremelinteractiveanalysisofweb-scaledatasets-140609232304-phpapp02/85/Dremel-interactive-analysis-of-web-scale-datasets-12-320.jpg)
![Data Model
𝝉 = dom | < A1 : 𝝉[∗|?], ..., An : 𝝉[∗|?] >
• 𝝉: An atomic type or a record type.
• Atomic type: Integers, floating-point numbers, strings, etc.
• Record: It consist of one or multiple fields.
• Repeated fields (*) may occur multiple times in a record.
• Optional fields (?) may be missing from the record.
• Otherwise, a field is required.](https://image.slidesharecdn.com/dremelinteractiveanalysisofweb-scaledatasets-140609232304-phpapp02/85/Dremel-interactive-analysis-of-web-scale-datasets-13-320.jpg)



















































![Data Structures - Lecture 1 [introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-1introduction-141217054305-conversion-gate02-thumbnail.jpg?width=560&fit=bounds)








Ad
More Related Content
What's hot (20)
Similar to Dremel interactive analysis of web scale datasets (20)


















Ad
Recently uploaded (20)




















Ad
Dremel interactive analysis of web scale datasets
- 1. Dremel: Interactive Analysis of Web-Scale Datasets Carl Adler IDSL - Dep. IM - NTUST
- 2. Outline • About Dremel • Main Features • Record-Oriented v.s. Column-Oriented • Data Model • Nested Columnar Storage • Query Execution • Experiments • Conclusions
- 3. About Dremel A scalable, interactive ad-hoc query system for analysis of read-only nested data. By combining multi-level execution trees and columnar data layout, it is capable of running aggregation queries over trillion-row tables in seconds.
- 4. Main Features • Dremel is a large-scale system • The complement for MapReduce-based interactive query • The nested data model • Build on ideas from web search and parallel DBMSs • Column-striped storage representation
- 5. Main Features Dremel is a large-scale system: • Reading 1TB of compressed data in 1 sec -> Needs tens of thousands of disks, concurrently reading. -> Fault tolerance is critical.
- 6. Main Features The complement for MapReduce-based interactive query: • Unlike traditional DBs, it is capable of operating on in situ nested data. • Not a replacement for MR.
- 7. Main Features The nested data model: • Data used in web are often non-relational. • Need some flexible data model like json.
- 8. Main Features Build on ideas from web search and parallel DBMSs: • Serving tree: Divide a huge and complicated query into several small queries. • SQL-like interface: Like Hive and Pig.
- 9. Main Features Column-striped storage representation: • Read less data from secondary storage and reduce CPU cost due to compression. • Column stores have been adopted for analyzing relational data but to the best of our knowledge have not been extended to nested data models.
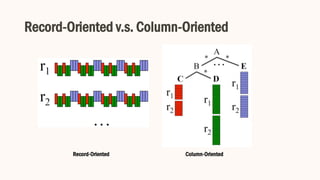
- 10. Record-Oriented v.s. Column-Oriented Record-Oriented Column-Oriented
- 11. Record-Oriented v.s. Column-Oriented • We can just retrieve A.B.C without reading A.E or A.B.D, etc. • Challenge: How to scan arbitrary subset of fields efficiently and process some analysis in the same time.
- 12. Data Model • The data model originated in the context of distributed systems (Protocol Buffers), is used widely at Google, and is available as an open source implementation. • The data model is based on strongly-typed nested records. Its abstract syntax is given by: 𝝉 = dom | < A1 : 𝝉[∗|?], ..., An : 𝝉[∗|?] >
- 13. Data Model 𝝉 = dom | < A1 : 𝝉[∗|?], ..., An : 𝝉[∗|?] > • 𝝉: An atomic type or a record type. • Atomic type: Integers, floating-point numbers, strings, etc. • Record: It consist of one or multiple fields. • Repeated fields (*) may occur multiple times in a record. • Optional fields (?) may be missing from the record. • Otherwise, a field is required.
- 14. Data Model
- 15. Data Model This type of data model is language independent and platform-neutral, so a MR program written in Java can consume records from a data source exposed via a C++ library.
- 16. Nested Columnar Storage • Values alone do not convey the structure of a record. • Given two values of a repeated field, we do not know at what ‘level’ the value repeated (e.g., whether these values are from two different records, or two repeated values in the same record). Repetition Levels • Given a missing optional field, we do not know which enclosing records were defined explicitly. Definition Levels
- 18. Nested Columnar Storage: Repetition Levels • Repetition Levels: It tells us at what repeated field in the field’s path the value has repeated. • The field path Name.Language.Code contains two repeated fields, Name and Language. Hence, the repetition level of Code ranges between 0 and 2; level 0 denotes the start of a new record.
- 19. Nested Columnar Storage: Repetition Levels
- 20. Nested Columnar Storage: Definition Levels • Definition Levels: Each value of a field with path p, esp. every NULL, has a definition level specifying how many fields in p that could be undefined (because they are optional or repeated) are actually present in the record.
- 21. Nested Columnar Storage: Definition Levels
- 22. Nested Columnar Storage • Splitting Records into Columns: With this type of data model, write operation is very easy, but we need to focus on reading. When reading, we don’t need to read the entire records, and we can just read those columns we need to form a partial data model.
- 24. Nested Columnar Storage Complete record assembly automaton. Edges are labeled with repetition levels.
- 25. Query Execution • Dremel’s query language is based on SQL and is designed to be efficiently implementable on columnar nested storage. • Each SQL statement takes as input one or multiple nested tables and their schemas and produces a nested table and its output schema.
- 26. Query Execution Sample query, its result, and output schema.
- 27. Query Execution Architecture: • Dremel uses a multi-level serving tree to execute queries. • A root server receives incoming queries, reads metadata from the tables, and routes the queries to the next level in the serving tree. The leaf servers communicate with the storage layer or access the data on local disk.
- 28. Query Execution System architecture and execution inside a server node.
- 29. Query Execution • Consider a simple aggregation query below: SELECT A, COUNT(B) FROM T GROUP BY A • When the root server receives the above query, it determines all tablets, i.e., horizontal partitions of the table, that comprise T and rewrites the query as follows: SELECT A, SUM(c) FROM (R1 1 UNION ALL ... R1 n) GROUP BY A • Tables R1 1 , …, R1 n are the results of queries sent to the nodes 1, …, n at level 1 of the serving tree:
- 30. Query Execution • Tables R1 1 , …, R1 n are the results of queries sent to the nodes 1, …, n at level 1 of the serving tree: R1 i = SELECT A, COUNT(B) AS c FROM T1 i GROUP BY A • T1 i is a disjoint partition of tablets in T processed by server i at level 1. • Here, we can know that the dataset will smaller than the original one, and each dataset can be processed faster.
- 31. Query Execution • Because Dremel is a multi-user system(usually several queries are executed simultaneously). • A query dispatcher schedules queries based on their priorities and balances the load. Its other important role is to provide fault tolerance when one server becomes much slower than others or a tablet replica becomes unreachable.
- 32. Query Execution • A system with 3000 leaf servers • Each leaf server using 8 threads • 3000 * 8 = 24000 (slots) • A table spanning 100,000 tablets • Assigning about 5 tablets / slot
- 33. Experiments • The basic data access characteristics on a single machine • How columnar storage benefits MR execution • Dremel’s performance
- 34. Experiments Table name Number of records Size (unrepl., compressed) Number of fields Data center Repl. factor T1 85 billion 87 TB 270 A 3× T2 24 billion 13 TB 530 A 3× T3 4 billion 70 TB 1200 A 3× T4 1+ trillion 105 TB 50 B 3× T5 1+ trillion 20 TB 30 B 2× Datasets used in the experimental study
- 35. Experiments – Single Machine Performance breakdown when reading from a local disk (300K-record fragment of Table T1) T1 85 billion 87 TB 270 A 3×
- 36. Experiments – MR and Dremel Q1: SELECT SUM( CountWords (txtField)) / COUNT(*) FROM T1 T1 85 billion 87 TB 270 A 3×
- 37. Experiments – Serving Tree Topology Q2: SELECT country, SUM( item.amount ) FROM T2 GROUP BY country Q3: SELECT domain, SUM( item.amount ) FROM T2 WHERE domain CONTAINS ’.net’ GROUP BY domain T2 24 billion 13 TB 530 A 3×
- 38. Experiments – Per-tablet Histograms The area under each histogram corresponds to 100%. As the figure indicates, 99% of Q2 (or Q3) tablets are processed under one second (or two seconds).
- 39. Experiments – Scalability In each run, the total expended CPU time is nearly identical, at about 300K seconds, whereas the user-perceived time decreases near-linearly with the growing size of the system.
- 40. Experiments – Stragglers Q6: SELECT COUNT(DISTINCT a) FROM T5 In contrast to the other datasets, T5 is two-way replicated. Hence, the likelihood of stragglers slowing the execution is higher since there are fewer opportunities to reschedule the work. T5 1+ trillion 20 TB 30 B 2×
- 41. Conclusions • Dremel is a custom, scalable data management solution built from simpler components. It complements the MR paradigm. • We outlined the key aspects of Dremel, including its storage format, query language, and execution. • Multi-level execution trees & Columnar data layout • In the future, it might be widely adopted in the world.
- 42. Reference • Dremel: Interactive Analysis of Web-Scale Datasets
- 43. END