


















































































Ad
More Related Content
What's hot (18)
Similar to Drupal as a Semantic Web platform - ISWC 2012 (20)







![[HKDUG] #20151017 - BarCamp 2015 - Drupal 8 is Coming! Are You Ready?](https://cdn.slidesharecdn.com/ss_thumbnails/hkdug20151017-barcamp2015-drupal8iscomingareyouready-151017054334-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)








Ad
More from scorlosquet (6)






Ad
Recently uploaded (20)




















Drupal as a Semantic Web platform - ISWC 2012
- 1. Drupal as a Semantic Web platform Stéphane Corlosquet, Sudeshna Das, Emily Merrill, Paolo Ciccarese, and Tim Clark Massachusetts General Hospital ISWC 2012, Boston, USA – Nov 14th, 2012
- 2. Drupal ● Dries Buytaert - small news site in 2000 ● Open Source - 2001 ● Content Management System ● LAMP stack ● Non-developers can build sites and publish content ● Control panels instead of code http://www.flickr.com/photos/funkyah/2400889778
- 10. Who uses Drupal?
- 11. Who uses Drupal?
- 12. Who uses Drupal? http://buytaert.net/tag/drupal-sites
- 13. Drupal ● Open & modular architecture ● Extensible by modules ● Standards-based ● Low resource hosting ● Scalable http://drupal.org/getting-started/before/overview
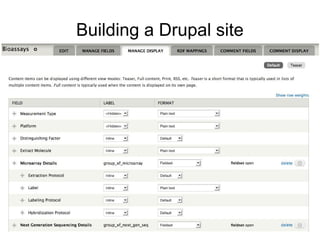
- 14. Building a Drupal site http://www.flickr.com/photos/toomuchdew/3792159077/
- 15. Building a Drupal site ● Create the content types you need Blog, article, wiki, forum, polls, image, video, podcast, e- commerce... (be creative) http://www.flickr.com/photos/georgivar/4795856532/
- 16. Building a Drupal site ● Enable the features you want Comments, tags, voting/rating, location, translations, revisions, search... http://www.flickr.com/photos/skip/42288941/
- 17. Building a Drupal site
- 18. Building a Drupal site Thousands of free contributed modules ● Google Analytics ● Wysiwyg ● Captcha ● Calendar ● XML sitemap ● Five stars ● Twitter ● ... http://www.flickr.com/photos/kaptainkobold/1422600992/
- 19. The Drupal Community http://www.flickr.com/photos/x-foto/4923221504/
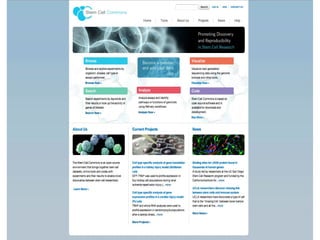
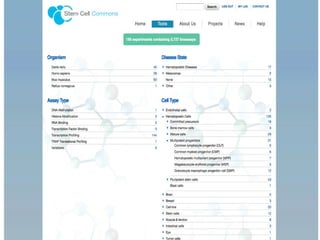
- 20. Use Case #1: Stem Cell Commons http://stemcellcommons.org
- 21. Repository • New repository for stem cell data as part of Stem Cell Commons • Harvard Stem Cell Institute (HSCI): Blood and Cancer program system • Designed to incorporate - multiple stem cell types - multiple assay types - user requested features • Integrated with analytical tools • Enhanced search and browsing capabilities
- 26. Content types
- 29. Integrated with Analysis tools
- 30. What about RDF?
- 31. Drupal 7 default RDF Schema
- 32. SCC RDF Schema
- 34. Modules used ● Contributed module for more features ● RDF Extensions ● Serialization formats: RDF/XML, Turtle, N-Triples ● SPARQL ● Expose Drupal RDF data in a SPARQL Endpoint ● Features and packaging ● Build distributions / deployment workflow
- 35. SPARQL Endpoint ● SPARQL Endpoint available at /sparql
- 36. SPARQL Endpoint ● Need to query Drupal data across different classes from R ● Need a standard query language ● SQL? ● Query Drupal data with SPARQL
- 39. SPARQL query PREFIX obo: <http://purl.obolibrary.org/obo/> PREFIX mged: <http://mged.sourceforge.net/ontologies/MGEDontology.php#> PREFIX dc: <http://purl.org/dc/terms/> SELECT ?bioassay_title WHERE { ?experiment obo:OBI_0000070 ?bioassay; dc:title ?bioassay_title . ?bioassay mged:LabelCompound <http://exframe-dev.sciencecollaboration.org/taxonomy/term/588> . } GROUP BY ?bioassay_title ORDER BY ASC(dc:date)
- 40. Wrap up use case #1 ● Drupal is a good fit for building web frontends ● Editing User Interfaces out of the box ● Querying Data in SQL: ● not very friendly ● may not be appropriate / performant ● Querying with SPARQL: ● Use the backend that match your needs ● ARC2 can be sufficient for prototyping and lightweight use cases
- 41. Use Case #2: Data Layers Domeo + Drupal
- 42. Domeo ● Annotation Tool developed by MIND Informatics, Massachusetts General Hospital ● Annotate HTML documents ● Share annotations ● Annotation Ontology (AO), provenance, ACL ● JSON-LD Service to retrieve annotations ● http://annotationframework.org/
- 43. Domeo
- 44. Domeo
- 45. Domeo
- 46. Domeo
- 47. JSON-LD ● JSON for Linked Data ● Client side as well as server side friendly ● Browser Scripting: – Native javascript format – RDFa API in the DOM ● Data can be fetched from anywhere: – Cross-Origin Resource Sharing (CORS) required ● Clients can mash data
- 48. List of publications in Drupal
- 49. Can we layer personal annotations on top?
- 50. What do we have? ● RDFa markup for each publication
- 51. RDFa API ● Extract structured data from RDFa documents ● Green Turtle: RDFa 1.1 library in Javascript document.getElementsByType('http://schema.org/ScholarlyArticle');
- 52. RDFa API
- 53. Domeo + Drupal ● Data mash up from independent sources
- 54. Domeo + Drupal
- 55. Wrap up use case #2 ● Another use case for exposing data as RDFa ● RDFa and JSON-LD fit well together ● HTML → RDFa ● JSON → JSON-LD ● CORS support not yet available everywhere ● Grails didn't have it ● Use JSONP instead
- 56. Thanks! ● Stéphane Corlosquet ● [email protected] ● @scorlosquet ● http://openspring.net/ ● MIND Informatics ● http://www.mindinformatics.org/