DS-MLR: Scaling Multinomial Logistic Regression via Hybrid Parallelism
0 likes146 views

This document summarizes a research paper on scaling multinomial logistic regression via hybrid parallelism. The paper proposes a method called DS-MLR that achieves hybrid parallelism for multinomial logistic regression. DS-MLR first reformulates the MLR objective function into a doubly separable form that can be optimized in a distributed manner. It then presents an asynchronous distributed algorithm to optimize the reformulated objective function across multiple workers. Empirical results on large real-world datasets show that DS-MLR can efficiently train MLR models in a hybrid parallel manner and outperform other parallelization approaches.





![Motivation for Hybrid Parallelism
Popular ways to distribute MLR:
Data parallel (partition data,
duplicate parameters)
N
D
X
Data
D
K
W
Model
Storage Complexity:
O(ND
P ) data, O(KD) model
e.g. L-BFGS
Model parallel (partition
parameters, duplicate data)
N
D
X
Data
D
K
W
Model
Storage Complexity:
O(ND) data, O(KD
P ) model
e.g. LC [Gopal et al 2013]
3 / 54](https://image.slidesharecdn.com/dsmlrkdd19slidesshort-190813051425/85/DS-MLR-Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-6-320.jpg)




































![Parallelization - Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
(a) Initial Assignment of W and A
34 / 54](https://image.slidesharecdn.com/dsmlrkdd19slidesshort-190813051425/85/DS-MLR-Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-45-320.jpg)
![Parallelization - Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
(a) Initial Assignment of W and A
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
(b) worker 1 updates w2 and
communicates it to worker 4
34 / 54](https://image.slidesharecdn.com/dsmlrkdd19slidesshort-190813051425/85/DS-MLR-Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-46-320.jpg)
![Parallelization - Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
(a) Initial Assignment of W and A
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
(b) worker 1 updates w2 and
communicates it to worker 4
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
(c) worker 4 can now update w2
34 / 54](https://image.slidesharecdn.com/dsmlrkdd19slidesshort-190813051425/85/DS-MLR-Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-47-320.jpg)
![Parallelization - Asynchronous NOMAD [Yun et al 2014]
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
A
W
(a) Initial Assignment of W and A
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
(b) worker 1 updates w2 and
communicates it to worker 4
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
(c) worker 4 can now update w2
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xx
x
x
x
x
x
x
x
x
xx
x
x
xx
(d) As algorithm proceeds, ownership of
wk changes continuously.
34 / 54](https://image.slidesharecdn.com/dsmlrkdd19slidesshort-190813051425/85/DS-MLR-Scaling-Multinomial-Logistic-Regression-via-Hybrid-Parallelism-48-320.jpg)












DS-MLR: Scaling Multinomial Logistic Regression via Hybrid Parallelism
- 1. Scaling Multinomial Logistic Regression via Hybrid Parallelism Parameswaran Raman University of California Santa Cruz KDD 2019 Aug 4-8 Joint work with: Sriram Srinivasan, Shin Matsushima, Xinhua Zhang, Hyokun Yun, S.V.N. Vishwanathan 1 / 54
- 2. Multinomial Logistic Regression (MLR) Given: Training data (xi , yi )i=1,...,N, xi ∈ RD Labels yi ∈ {1, 2, . . . , K} N D X Data y 2 / 54
- 3. Multinomial Logistic Regression (MLR) Given: Training data (xi , yi )i=1,...,N, xi ∈ RD Labels yi ∈ {1, 2, . . . , K} N D X Data y Goal: Learn a model W Predict labels for the test data points using W D K W Model 2 / 54
- 4. Multinomial Logistic Regression (MLR) Given: Training data (xi , yi )i=1,...,N, xi ∈ RD Labels yi ∈ {1, 2, . . . , K} N D X Data y Goal: Learn a model W Predict labels for the test data points using W D K W Model Assume: N, D and K are large (N >>> D >> K) 2 / 54
- 5. Motivation for Hybrid Parallelism Popular ways to distribute MLR: Data parallel (partition data, duplicate parameters) N D X Data D K W Model Storage Complexity: O(ND P ) data, O(KD) model e.g. L-BFGS 3 / 54
- 6. Motivation for Hybrid Parallelism Popular ways to distribute MLR: Data parallel (partition data, duplicate parameters) N D X Data D K W Model Storage Complexity: O(ND P ) data, O(KD) model e.g. L-BFGS Model parallel (partition parameters, duplicate data) N D X Data D K W Model Storage Complexity: O(ND) data, O(KD P ) model e.g. LC [Gopal et al 2013] 3 / 54
- 7. Can we get the best of both worlds? 4 / 54
- 8. Yes! Hybrid Parallelism N D X Data D K W Model Storage Complexity: O(ND P ) data, O(KD P ) model We propose a Hybrid Parallel method DS-MLR 5 / 54
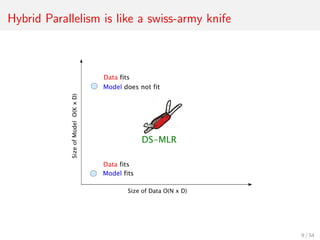
- 9. Hybrid Parallelism is like a swiss-army knife 6 / 54
- 10. Hybrid Parallelism is like a swiss-army knife 7 / 54
- 11. Hybrid Parallelism is like a swiss-army knife 8 / 54
- 12. Hybrid Parallelism is like a swiss-army knife 9 / 54
- 13. Hybrid Parallelism is like a swiss-army knife 10 / 54
- 14. Hybrid Parallelism is like a swiss-army knife 11 / 54
- 15. Empirical Study - Multi Machine 0 2 4 6 ·105 10 10.2 10.4 time (secs) objective Reddit-Full dataset (Data Size: 228 GB, Model Size: 358 GB) DS-MLR Figure: Data does not fit, Model does not fit 211 million examples - O(N) 44 billion parameters - O(K × D) 12 / 54
- 16. How do we achieve Hybrid Parallelism in machine learning models? 13 / 54
- 18. Double-Separability Definition Let {Si }m i=1 and {Sj }m j=1 be two families of sets of parameters. A function f : m i=1 Si × m j=1 Sj → R is doubly separable if ∃ fij : Si × Sj → R for each i = 1, 2, . . . , m and j = 1, 2, . . . , m such that: f (θ1, θ2, . . . , θm, θ1, θ2, . . . , θm ) = m i=1 m j=1 fij (θi , θj ) 15 / 54
- 19. Double-Separability f (θ1, θ2, . . . , θm, θ1, θ2, . . . , θm ) = m i=1 m j=1 fij (θi , θj ) Each sub-function fij can be computed independently and in parallel 16 / 54
- 20. Are all machine learning models doubly-separable? 17 / 54
- 21. Sometimes . . . e.g. Matrix Factorization L(w1, w2, . . . , wN, h1, h2, . . . , hM) = N i=1 M j=1 f (wi , hj ) Objective function is trivially doubly-separable! 18 / 54
- 22. Others need algorithmic reformulations . . . - Binary Classification (”DSO: Distributed Stochastic Optimization for the Regularized Risk”, Matsushima et al 2014) - Ranking (”RoBiRank: Ranking via Robust Binary Classification”, Yun et al 2014) 19 / 54
- 23. Others need algorithmic reformulations . . . - Binary Classification (”DSO: Distributed Stochastic Optimization for the Regularized Risk”, Matsushima et al 2014) - Ranking (”RoBiRank: Ranking via Robust Binary Classification”, Yun et al 2014) 19 / 54
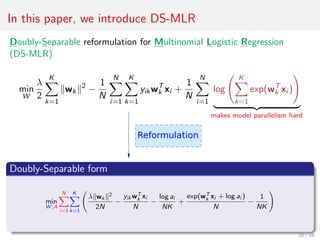
- 24. In this paper, we introduce DS-MLR Doubly-Separable reformulation for Multinomial Logistic Regression (DS-MLR) min W λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yikwT k xi + 1 N N i=1 log K k=1 exp(wT k xi ) makes model parallelism hard Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wT k xi N − log ai NK + exp(wT k xi + log ai ) N − 1 NK 20 / 54
- 25. DS-MLR 21 / 54
- 26. DS-MLR CV Fully de-centralized distributed algorithm (data and model fully partitioned across workers) Asynchronous (communicate model in the background while computing parameter updates) Avoids expensive Bulk Synchronization steps 22 / 54
- 27. DS-MLR CV Fully de-centralized distributed algorithm (data and model fully partitioned across workers) Asynchronous (communicate model in the background while computing parameter updates) Avoids expensive Bulk Synchronization steps 22 / 54
- 28. DS-MLR CV Fully de-centralized distributed algorithm (data and model fully partitioned across workers) Asynchronous (communicate model in the background while computing parameter updates) Avoids expensive Bulk Synchronization steps 22 / 54
- 29. Delving deeper DS-MLR 23 / 54
- 31. Multinomial Logistic Regression (MLR) Given Training data (xi , yi )i=1,...,N where xi ∈ RD corresp. labels yi ∈ {1, 2, . . . , K} N, D and K are large (N >>> D >> K) Goal The probability that xi belongs to class k is given by: p(yi = k|xi , W ) = exp(wk T xi ) K j=1 exp(wj T xi ) where W = {w1, w2, . . . , wK } denotes the parameter for the model. 25 / 54
- 32. Multinomial Logistic Regression (MLR) Given Training data (xi , yi )i=1,...,N where xi ∈ RD corresp. labels yi ∈ {1, 2, . . . , K} N, D and K are large (N >>> D >> K) Goal The probability that xi belongs to class k is given by: p(yi = k|xi , W ) = exp(wk T xi ) K j=1 exp(wj T xi ) where W = {w1, w2, . . . , wK } denotes the parameter for the model. 25 / 54
- 33. Multinomial Logistic Regression (MLR) The corresponding l2 regularized negative log-likelihood loss: min W λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yikwk T xi + 1 N N i=1 log K k=1 exp(wk T xi ) where λ is the regularization hyper-parameter. 26 / 54
- 34. Multinomial Logistic Regression (MLR) The corresponding l2 regularized negative log-likelihood loss: min W λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yikwk T xi + 1 N N i=1 log K k=1 exp(wk T xi ) makes model parallelism hard where λ is the regularization hyper-parameter. 27 / 54
- 35. Reformulation into Doubly-Separable form Step 1: Introduce redundant constraints (new parameters A) into the original MLR problem min W ,A L1(W , A) = λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yik wk T xi − 1 N N i=1 log ai s.t. ai = 1 K k=1 exp(wk T xi ) 28 / 54
- 36. Reformulation into Doubly-Separable form Step 2: Turn the problem to unconstrained min-max problem by introducing Lagrange multipliers βi , ∀i = 1, . . . , N min W ,A max β L2(W , A, β) = λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yik wk T xi − 1 N N i=1 log ai + 1 N N i=1 K k=1 βi ai exp(wk T xi ) − 1 N N i=1 βi Primal Updates for W , A and Dual Update for β (similar in spirit to dual-decomp. methods). 29 / 54
- 37. Reformulation into Doubly-Separable form Step 2: Turn the problem to unconstrained min-max problem by introducing Lagrange multipliers βi , ∀i = 1, . . . , N min W ,A max β L2(W , A, β) = λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yik wk T xi − 1 N N i=1 log ai + 1 N N i=1 K k=1 βi ai exp(wk T xi ) − 1 N N i=1 βi Primal Updates for W , A and Dual Update for β (similar in spirit to dual-decomp. methods). 29 / 54
- 38. Reformulation into Doubly-Separable form Step 3: Stare at the updates long-enough When at+1 i is solved to optimality, it admits an exact closed-form solution given by a∗ i = 1 βi K k=1 exp(wk T xi ) . Dual-ascent update for βi is no longer needed, since the penalty is always zero if βi is set to a constant equal to 1. min W ,A L3(W , A) = λ 2 K k=1 wk 2 − 1 N N i=1 K k=1 yik wk T xi − 1 N N i=1 log ai + 1 N N i=1 K k=1 ai exp(wk T xi ) − 1 N 30 / 54
- 39. Reformulation into Doubly-Separable form Step 4: Simple re-write Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wk T xi N − log ai NK + exp(wk T xi + log ai ) N − 1 NK 31 / 54
- 40. Reformulation into Doubly-Separable form Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wk T xi N − log ai NK + exp(wk T xi + log ai ) N − 1 NK Each worker samples a pair (wk, ai ). Update wk using stochastic gradient Update ai using its exact closed-form solution ai = 1 K k=1 exp(wk T xi ) 32 / 54
- 41. Reformulation into Doubly-Separable form Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wk T xi N − log ai NK + exp(wk T xi + log ai ) N − 1 NK Each worker samples a pair (wk, ai ). Update wk using stochastic gradient Update ai using its exact closed-form solution ai = 1 K k=1 exp(wk T xi ) 32 / 54
- 42. Reformulation into Doubly-Separable form Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wk T xi N − log ai NK + exp(wk T xi + log ai ) N − 1 NK Each worker samples a pair (wk, ai ). Update wk using stochastic gradient Update ai using its exact closed-form solution ai = 1 K k=1 exp(wk T xi ) 32 / 54
- 43. Reformulation into Doubly-Separable form Doubly-Separable form min W ,A N i=1 K k=1 λ wk 2 2N − yik wk T xi N − log ai NK + exp(wk T xi + log ai ) N − 1 NK Each worker samples a pair (wk, ai ). Update wk using stochastic gradient Update ai using its exact closed-form solution ai = 1 K k=1 exp(wk T xi ) 32 / 54
- 45. Parallelization - Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W (a) Initial Assignment of W and A 34 / 54
- 46. Parallelization - Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W (a) Initial Assignment of W and A x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx (b) worker 1 updates w2 and communicates it to worker 4 34 / 54
- 47. Parallelization - Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W (a) Initial Assignment of W and A x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx (b) worker 1 updates w2 and communicates it to worker 4 x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx (c) worker 4 can now update w2 34 / 54
- 48. Parallelization - Asynchronous NOMAD [Yun et al 2014] x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx A W (a) Initial Assignment of W and A x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx (b) worker 1 updates w2 and communicates it to worker 4 x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx (c) worker 4 can now update w2 x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x xx x x x x x x x x xx x x xx (d) As algorithm proceeds, ownership of wk changes continuously. 34 / 54
- 50. Motivation for Hybrid Parallelism LSHTC1-small LSHTC1-large ODP Youtube8M-Video Reddit-Full 101 102 103 104 105 106 max memory of commodity machine SizeinMB(log-scale) data size (MB) parameters size (MB) Reddit-Full dataset: Data 228 GB and Model: 358 GB 36 / 54
- 51. Motivation for Hybrid Parallelism LSHTC1-small LSHTC1-large ODP Youtube8M-Video Reddit-Full 101 102 103 104 105 106 max memory of commodity machine SizeinMB(log-scale) data size (MB) parameters size (MB) Reddit-Full dataset: Data 228 GB and Model: 358 GB 36 / 54
- 52. Datasets 37 / 54
- 53. Empirical Study - Single Machine 100 101 102 103 1.45 1.5 1.55 1.6 1.65 time (secs) objective NEWS20 dataset DS-MLR L-BFGS LC 10−1 100 101 102 103 104 105 1 2 3 4 time (secs) objective CLEF dataset DS-MLR L-BFGS LC 101 102 103 104 0 0.2 0.4 0.6 0.8 1 time (secs) objective LSHTC1-small dataset DS-MLR L-BFGS LC Figure: Data fits, Model fits 38 / 54
- 54. Empirical Study - Multi Machine 103 104 0.5 0.6 0.7 0.8 time (secs) objective LSHTC1-large dataset (Model Size: 34 GB) DS-MLR LC 0 1 2 3 4 5 6 ·105 9.4 9.6 9.8 10 10.2 10.4 time (secs)objective ODP dataset (Model Size: 355 GB) DS-MLR Figure: Data fits, Model does not fit 39 / 54
- 55. Empirical Study - Multi Machine 0 1 2 3 ·105 0 20 40 60 time (secs) objective Youtube-Video dataset (Data Size: 76 GB) DS-MLR Figure: Data does not fit, Model fits 40 / 54
- 56. Empirical Study - Multi Machine 0 2 4 6 ·105 10 10.2 10.4 time (secs) objective Reddit-Full dataset (Data Size: 228 GB, Model Size: 358 GB) DS-MLR Figure: Data does not fit, Model does not fit 211 million examples - O(N) 44 billion parameters - O(K × D) 41 / 54
- 57. Conclusion We proposed DS-MLR Hybrid Parallel reformulation for MLR → O(Data) P and O(Parameters) P Fully De-centralized and Asynchronous algorithm Avoids Bulk-synchronization Empirical results suggest wide applicability and good predictive performance 42 / 54
- 58. Future Extensions Design Doubly-Separable losses for other machine learning models: Extreme multi-label classification Log-linear parameterization for undirected graphical models Deep Learning Thank You! 43 / 54
- 59. More details Please check out our paper / poster Code: https://bitbucket.org/params/dsmlr 44 / 54
- 60. Acknowledgements Thanks to all my collaborators! 45 / 54