Effective and Unsupervised Fractal-based Feature Selection for Very Large Datasets: removing linear and non-linear attribute correlations

Given a very large dataset of moderate-to-high di- mensionality, how to mine useful patterns from it? In such cases, dimensionality reduction is essential to overcome the “curse of dimensionality”. Although there exist algorithms to reduce the dimensionality of Big Data, unfortunately, they all fail to identify/eliminate non-linear correlations between attributes. This paper tackles the problem by exploring con- cepts of the Fractal Theory and massive parallel processing to present Curl-Remover, a novel dimensionality reduction technique for very large datasets. Our contributions are: Curl- Remover eliminates linear and non-linear attribute correlations as well as irrelevant ones; it is unsupervised and suits for analytical tasks in general – not only classification; it presents linear scale-up; it does not require the user to guess the number of attributes to be removed, and; it preserves the attributes’ semantics. We performed experiments on synthetic and real data spanning up to 1.1 billion points and Curl- Remover outperformed a PCA-based algorithm, being up to 8% more accurate.


















![Fundamental Concepts
Fractal Theory
Fractal Correlation Dimension - Box Counting
19
Multidimensional
Quad-tree
[Traina Jr. et al, 2000]](https://image.slidesharecdn.com/presentation-170127123347/85/Effective-and-Unsupervised-Fractal-based-Feature-Selection-for-Very-Large-Datasets-removing-linear-and-non-linear-attribute-correlations-19-320.jpg)




























































![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=560&fit=bounds)













More Related Content
What's hot (18)
Viewers also liked (19)















Similar to Effective and Unsupervised Fractal-based Feature Selection for Very Large Datasets: removing linear and non-linear attribute correlations (20)




















More from Universidade de São Paulo (11)











Recently uploaded (20)




















Effective and Unsupervised Fractal-based Feature Selection for Very Large Datasets: removing linear and non-linear attribute correlations
- 1. Effective and Unsupervised Fractal-based Feature Selection for Very Large Datasets Removing linear and non-linear attribute correlations Antonio Canabrava Fraideinberze Jose F Rodrigues-Jr Robson Leonardo Ferreira Cordeiro Databases and Images Group University of São Paulo São Carlos - SP - Brazil
- 2. 2 Terabytes? … How to analyze that data?
- 3. 3 Terabytes? Parallel processing and dimensionality reduction, for sure... … How to analyze that data?
- 4. How to analyze that data? 4 Terabytes? , but how to remove linear and non-linear attribute correlations, besides irrelevant attributes? …
- 5. How to analyze that data? 5 Terabytes? , and how to reduce dimensionality without human supervision and being task independent? …
- 7. Agenda Fundamental Concepts Related Work Proposed Method Evaluation Conclusion 7
- 8. Agenda Fundamental Concepts Related Work Proposed Method Evaluation Conclusion 8
- 13. Fundamental Concepts Fractal Theory Embedded, Intrinsic and Fractal Correlation Dimension Fractal Correlation Dimension ≅ Intrinsic Dimension 13
- 14. Fundamental Concepts Fractal Theory Embedded, Intrinsic and Fractal Correlation Dimension Embedded dimension ≅ 3 Intrinsic dimension ≅ 1 Embedded dimension ≅ 3 Intrinsic dimension ≅ 2 14
- 15. Fundamental Concepts Fractal Theory Fractal Correlation Dimension - Box Counting 15
- 16. Fundamental Concepts Fractal Theory Fractal Correlation Dimension - Box Counting 16
- 17. Fundamental Concepts Fractal Theory Fractal Correlation Dimension - Box Counting log(r) 17
- 18. Fundamental Concepts Fractal Theory Fractal Correlation Dimension - Box Counting log(r) 18
- 19. Fundamental Concepts Fractal Theory Fractal Correlation Dimension - Box Counting 19 Multidimensional Quad-tree [Traina Jr. et al, 2000]
- 20. Agenda Fundamental Concepts Related Work Proposed Method Evaluation Conclusion 20
- 21. Related Work Dimensionality Reduction - Taxonomy 1 Dimensionality Reduction Supervised Algorithms Unsupervised Algorithms Principal Component Analysis Singular Vector Decomposition Fractal Dimension Reduction 21
- 22. Related Work Dimensionality Reduction - Taxonomy 2 Dimensionality Reduction Feature ExtractionFeature Selection Principal Component Analysis Singular Vector Decomposition Fractal Dimension Reduction EmbeddedFilterWrapper 22
- 23. Related Work 23 Terabytes? Existing methods need supervision, miss non-linear correlations, cannot handle Big Data or work for classification only …
- 24. Agenda Fundamental Concepts Related Work Proposed Method Evaluation Conclusion 24
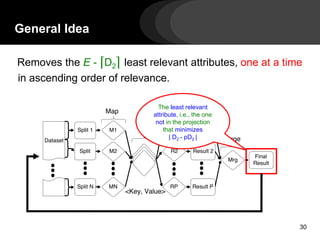
- 25. General Idea 25 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance.
- 26. General Idea 26 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Builds partial trees for the full dataset and for its E (E-1)-dimensional projections
- 27. General Idea 27 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. TreeID + cell spatial position Partial count of points
- 28. General Idea 28 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Sums partial point counts and reports log(r) and log(sum2) for each tree
- 29. General Idea 29 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Computes D2 for the full dataset and pD2 for each of its E (E-1)-dimensional projections
- 30. General Idea 30 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. The least relevant attribute, i.e., the one not in the projection that minimizes | D2 - pD2 |
- 31. General Idea 31 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Spots the second least relevant attribute …
- 32. General Idea 3 Main Issues 32 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance.
- 33. General Idea 3 Main Issues 33 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. 1° Too much data to be shuffled – one data pair per cell/tree
- 34. General Idea 3 Main Issues 34 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. 2° One data pass per irrelevant attribute
- 35. General Idea 3 Main Issues 35 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. 3° Not enough memory for mappers
- 36. Proposed Method Curl-Remover 36 1° Issue - Too much data to be shuffled; one data pair per cell/tree; Our solution - Two-phase dimensionality reduction: a) Serial feature selection in a tiny data sample (one reducer). Used to speed-up processing only; b) All mappers project data into a fixed subspace
- 37. 37 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance.Builds/reports N (2 or 3) tree levels of lowest resolution… Proposed Method Curl-Remover
- 38. 38 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. … plus the points projected into the M (2 or 3) most relevant attributes of sample Proposed Method Curl-Remover
- 39. 39 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Builds the full trees from their low resolution level cells and the projected points Proposed Method Curl-Remover
- 40. 40 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Proposed Method Curl-Remover High resolution cells are never shuffled
- 41. Proposed Method Curl-Remover 41 2° Issue - One data pass per irrelevant attribute; Our solution – Stores/reads the tree level of highest resolution, instead of the original data.
- 42. 42 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Rdb = cost to read dataset; TWRtree = cost to transfer, write and read the last tree level in next reduce step; If (Rdb > TWRtree) then writes tree; Proposed Method Curl-Remover
- 43. 43 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Proposed Method Curl-Remover
- 44. 44 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Writes tree’s last level in HDFS Proposed Method Curl-Remover
- 45. 45 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Reads tree’s last level from HDFS Proposed Method Curl-Remover
- 46. 46 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Proposed Method Curl-Remover Reads dataset only twice
- 47. Proposed Method Curl-Remover 47 3° Issue - Not enough memory for mappers; Our solution – Sorts data in mappers and reports “tree slices” whenever needed.
- 48. 48 Removes the E - ⌈D2⌉ least relevant attributes, one at a time in ascending order of relevance. Sorts its local points and builds “tree slices” monitoring memory consumption Proposed Method Curl-Remover
- 50. Proposed Method Curl-Remover 50 Reports “tree slices” with very little overlap
- 51. Agenda Fundamental Concepts Related Work Proposed Method Evaluation Conclusion 51
- 52. Evaluation Datasets Sierpinski - Sierpinski Triangle + 1 attribute linearly correlated + 2 attributes non- linearly correlated. 5 attributes, 1.1 billion points; Sierpinski Hybrid - Sierpinski Triangle + 1 attribute non-linearly correlated + 2 random attributes. 5 attributes, 1.1 billion points; Yahoo! Network Flows - communication patterns between end-users in the web. 12 attributes, 562 million points; Astro - high-resolution cosmological simulation. 6 attributes, 1 billion points; Hepmass - physics-related dataset with particles of unknown mass. 28 attributes, 10.5 million points; Hepmass Duplicated – Hepmass + 28 correlated attributes. 56 attributes, 10.5 million points. 52
- 55. Evaluation Comparison with sPCA - Classification 55
- 56. Evaluation Comparison with sPCA - Classification 56 8% more accurate, 7.5% faster
- 57. Evaluation Comparison with sPCA Percentage of Fractal Dimension after selection 57
- 58. Agenda Fundamental Concepts Related Work Proposed Method Evaluation Conclusion 58
- 59. Conclusions Accuracy - eliminates both linear and non-linear attribute correlations, besides irrelevant attributes; 8% better than sPCA; Scalability – linear scalability on the data size (theoretical analysis); experiments with up to 1.1 billion points; Unsupervised - it does not require the user to guess the number of attributes to be removed neither requires a training set; Semantics - it is a feature selection method, thus maintaining the semantics of the attributes; Generality - it suits for analytical tasks in general, and not only for classification; 59
- 60. Conclusions Accuracy - eliminates both linear and non-linear attribute correlations, besides irrelevant attributes; 8% better than sPCA; Scalability – linear scalability on the data size (theoretical analysis); experiments with up to 1.1 billion points; Unsupervised - it does not require the user to guess the number of attributes to be removed neither requires a training set; Semantics - it is a feature selection method, thus maintaining the semantics of the attributes; Generality - it suits for analytical tasks in general, and not only for classification; 60
- 61. Conclusions Accuracy - eliminates both linear and non-linear attribute correlations, besides irrelevant attributes; 8% better than sPCA; Scalability – linear scalability on the data size (theoretical analysis); experiments with up to 1.1 billion points; Unsupervised - it does not require the user to guess the number of attributes to be removed neither requires a training set; Semantics - it is a feature selection method, thus maintaining the semantics of the attributes; Generality - it suits for analytical tasks in general, and not only for classification; 61
- 62. Conclusions Accuracy - eliminates both linear and non-linear attribute correlations, besides irrelevant attributes; 8% better than sPCA; Scalability – linear scalability on the data size (theoretical analysis); experiments with up to 1.1 billion points; Unsupervised - it does not require the user to guess the number of attributes to be removed neither requires a training set; Semantics - it is a feature selection method, thus maintaining the semantics of the attributes; Generality - it suits for analytical tasks in general, and not only for classification; 62
- 63. Conclusions Accuracy - eliminates both linear and non-linear attribute correlations, besides irrelevant attributes; 8% better than sPCA; Scalability – linear scalability on the data size (theoretical analysis); experiments with up to 1.1 billion points; Unsupervised - it does not require the user to guess the number of attributes to be removed neither requires a training set; Semantics - it is a feature selection method, thus maintaining the semantics of the attributes; Generality - it suits for analytical tasks in general, and not only for classification; 63