Efficient in situ processing of various storage types on apache tajo
10 likes11,422 views

The document discusses Apache Tajo, an open source data warehouse system that supports efficient in-situ processing of various storage types. It describes Tajo's architecture, how it supports different storage backends like HDFS, S3, HBase and data formats. The key points are: 1) Tajo provides a unified interface to integrate and process data from various storage systems and formats like HDFS, S3, HBase, in a single system. 2) It uses a pluggable storage and data format architecture with tablespaces to abstract different physical storage configurations. 3) Operations can be pushed down to underlying storages for optimization during query execution. 4) Current supported storages include HDFS, S























Efficient in situ processing of various storage types on apache tajo
- 1. Efficient In-‐situ Processing of Various Storage Types on Apache Tajo Hadoop Summit 2015 San Jose Hyunsik Choi, Gruter Inc.
- 2. Agenda • Tajo Overview • Various Storage Support • Motivation • Design Consideration • What we did/are doing
- 3. An overview of Apache Tajo
- 4. Tajo: A Data Warehouse System • Data Warehouse System • Apache Top-‐level project • Low latency, and long running batch queries in a single system • ~100 ms up to several hours • Fault tolerance • Features • ANSI SQL compliance • Mature SQL features: Joins, Group by, Sort, Multiple distinct aggregations and Window function • Partitioned table support • Java/Python UDF support • JDBC driver and Java-‐based asynchronous API • SQL data type and Nested type support • Direct JSON support
- 5. Master
- 7. Query
- 9. Shell Web
- 10. UI Slave
- 12. Query
- 15. Query
- 17. (MySQL,
- 18. ..) Hive
- 19. Meta
- 20. StoreSubmit
- 22. a
- 23. query Manage
- 25. a
- 26. query send
- 27. tasks
- 28. monitor
- 29. send
- 30. tasks
- 31. monitor
- 33. Background: Query Optimization Phases
- 34. BLK 1 BLK 5 BLK 3 BLK 4 BLK 2 BLK 6 Task Assigning with Locality Worker Worker Worker HDFS Cluster Node1 Node2 Node3 Tajo Cluster… … … • Each task is assigned to a node according to its locality. Background: Task Execution
- 35. • Physical operators are assembled into a tree and their execution pipelined in the same machine. • Leaf operators must be scanners. • Tajo provides abstraction scanner, allowing to read different physical tables. Background: Local Execution
- 37. Motivation • Unified Interface • Data Integration • In-‐situ Processing HDFS NoSQL S3 Openstack Swift Apache Tajo
- 38. Sequence File RCFile Protocol Buffer Datasets stored in Various Formats/Storages
- 39. Design Considerations • More Storage Properties • Splittable, compressible (codecs), indexable, seekable, projectable, aggregatable, … • Query Optimization • Pluggable Storage and Data Format • More operation pushdown
- 40. Sequence File RCFile Protocol Buffer Separation between Storage and Format Data Formats Storage Types
- 41. Relationships between Storage and Format Storages Data Format Text RCFile Parquet Avro Hbase Serialization Protobuf Local File System Swift ….. JSON . . . .
- 42. Tablespace • Tablespace • Each table space is identified by a URI. • Hdfs://host:port/warehouse, hbase:zk://quorum1:2171,quorum2:2171, … • All tables in the same tablespace shares the same physical configuration. • URI scheme indicates storage type. • Hdfs, hbase, jdbc, … • Multiple tablespaces is possible in single storage namespace. • HDFS-‐2832: Enable support for heterogeneous in HDFS. • e.g., • /warehouse/ (disk) • /today/ (ssd)
- 43. Storage Configuration Storage Type Name and URI scheme Storage Handler Class
- 45. Format Configuration Format names The relationship between formats and storages
- 46. CREATE Table using Tablespace CREATE TABLE uptodate (key TEXT, …) TABLESPACE hbase1; CREATE TABLE archive (l_orderkey bigint, …) TABLESPACE warehouse USING text WITH (‘text.delimiter’ = ‘|’); Tablespace Name Format name
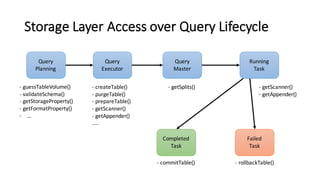
- 47. Storage Layer Access over Query Lifecycle Query Planning Query Executor Running Task Completed Task Failed Task Query Master -‐ guessTableVolume() -‐ validateSchema() -‐ getStorageProperty() -‐ getFormatProperty() -‐ … -‐ createTable() -‐ purgeTable() -‐ prepareTable() -‐ getScanner() -‐ getAppender() ….. -‐ getSplits() -‐ commitTable() -‐ rollbackTable() -‐ getScanner() -‐ getAppender()
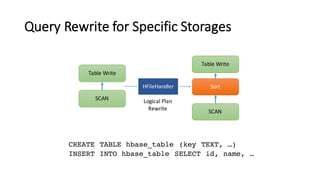
- 48. Query Rewrite for Specific Storages CREATE TABLE hbase_table (key TEXT, …) INSERT INTO hbase_table SELECT id, name, … SCAN Table Write SCAN Table Write Sort Logical Plan Rewrite HFileHandler
- 49. Operation Push Down SELECT X, SUM(Y) FROM table1 WHERE x 100 GROUP BY x Underlying Storage Filter and Projection can be pushed down into Underlying storages (like RDBMS, Hbase, Elasticsearch, …)
- 50. Current Status • Storages: • HDFS support • Amazon S3 and Openstack Swift • Hbase Scanner and Writer -‐ Hfile and Put Mode • JDBC-‐based Scanner and Writer (Working) • Kafka Scanner (Patch Available) • Elastic Search (Patch Available) • Data Formats • Text, JSON, RCFile, SequenceFile, Avro, Parquet, and ORC (Patch Available)
- 51. Get Involved! • We are recruiting contributors! • General • http://tajo.apache.org • Getting Started • http://tajo.apache.org/docs/0.10.0/getting_started.html • Downloads • http://tajo.apache.org/downloads.html • Jira – Issue Tracker • https://issues.apache.org/jira/browse/TAJO • Join the mailing list • dev-‐[email protected] • issues-‐[email protected]
- 52. QA