Elastic 101 - Get started
Download as PPTX, PDF2 likes241 views

What is Elastic - Elasticsearch - Kibana - Elasticsearch indexes - Shard and Replica And a lot of exciting topics to be discussed
















































































Ad
More Related Content
What's hot (20)
Similar to Elastic 101 - Get started (20)


















Ad
More from Ismaeel Enjreny (20)




















Ad
Recently uploaded (20)




















Elastic 101 - Get started
- 1. Elastic 101 - Get started ENG. ISMAIL ANJRINI ELASTIC CERTIFIED ENGINEER CURRENT VERSION 7.6Elastic-Saudi-Arabia
- 2. ELASTIC STACK (ELK) CURRENT VERSION 7.6
- 3. About Me Ismail Anjrini More than 15 years experience Elasticsearch Certified Engineer CURRENT VERSION 7.6
- 8. Lucene Apache Lucene is an open source project available for free Lucene is a Java library Elasticsearch is built over Lucene and provides a JSON based REST API to refer to Lucene features Elasticsearch provides a distributed system on top of Lucene CURRENT VERSION 7.6
- 10. Elasticsearch Installation Download and unzip Elasticsearch Unix ◦ bin/elasticsearch Windows ◦ binelasticsearch.bat http://localhost:9200 Done CURRENT VERSION 7.6
- 11. Elasticsearch Installation Install elasticsearch as windows service ◦ elasticsearch-service.bat install ◦ Run the windows service ◦ Wait ◦ http://localhost:9200/ ◦ Done CURRENT VERSION 7.6
- 12. Kibana Installation Download and unzip Elasticsearch Unix ◦ bin/kibana Windows ◦ binkibana.bat http://localhost:5601 Done CURRENT VERSION 7.6
- 13. Kibana Installation Install Kibana as task ◦ Create new Task ◦ Run the new task ◦ Wait for a minute ◦ http://localhost:5601/ ◦ Done CURRENT VERSION 7.6
- 15. Index An index is a collection of documents that have somewhat similar characteristics ◦ Customer data ◦ Orders ◦ Log ◦ … An index is identified by a name (that must be all lowercase) ◦ Index name is used to refer to the index when performing indexing, search, update, and delete operations against the documents in it CURRENT VERSION 7.6
- 16. Document A document is a basic unit of information that can be indexed ◦ Single customer ◦ Single log line The document is expressed in JSON CURRENT VERSION 7.6
- 17. Shards & Replicas Each shard is in itself a fully-functional and independent "index" that can be hosted on any node in the cluster When you create an index, you can simply define the number of shards that you want Sharding is important for two primary reasons: ◦ It allows you to horizontally split/scale your content volume ◦ It allows you to distribute and parallelize operations across shards (potentially on multiple nodes) thus increasing performance/throughput CURRENT VERSION 7.6
- 20. Shards routing CURRENT VERSION 7.6
- 21. Shards & Replicas Replication is important for two primary reasons: ◦ It provides high availability in case a shard/node fails. ◦ It allows to scale out your search volume/throughput since searches can be executed on all replicas in parallel CURRENT VERSION 7.6
- 24. Index An index is like a ‘table’ in a relational database. It has a mapping which defines multiple types. An index is a logical namespace: ◦ Maps to one or more primary shards ◦ Can have zero or more replica shards RDBMS ES Database ? Table Index Columns/Rows Document CURRENT VERSION 7.6
- 26. Index Operations – create index We can update number of shards/number of replicas for existed indexes CURRENT VERSION 7.6
- 27. Index Operations – mapping CURRENT VERSION 7.6
- 28. Index Operations – mapping PUT names { "mappings": { "properties": { "name": { "type": "keyword“ }, "name_text": { "type": "text" } } } } CURRENT VERSION 7.6
- 29. Index Operations – mapping CURRENT VERSION 7.6
- 30. Index Operations – list all indexes GET _cat/indices GET /_cat/indices/twi*?v GET /_cat/indices/?v&health=green|yellow|red&h=col1,col2 CURRENT VERSION 7.6
- 31. Index Operations – read index details GET big-index GET big-index?format=yaml|json CURRENT VERSION 7.6
- 32. Index Operations – create document POST big-index/_doc/1 { "name": "Ismail Anjrini", "age": 27 } POST big-index/_doc/2 { "name": "Fadi Abdul Wahab", "age": 45, "country": "Saudi Arabia" } CURRENT VERSION 7.6
- 33. Index Operations – POST vs PUT POST big-index/_doc/ { "name": "Kasem", "age": 46 } PUT big-index/_doc/ { "name": "Riyadh", "age": 33 } CURRENT VERSION 7.6
- 34. Index Operations – read document GET big-index/_doc/2 CURRENT VERSION 7.6
- 35. Index Operations – update document POST big-index/_update/1 { "doc": { "name":"Ismail Hassan Anjrini" , "country": "Syria" } } CURRENT VERSION 7.6
- 36. Index Operations – delete document DELETE big-index/_doc/1 PUT big-index/_doc/1 { "name":"Ismail Anjrini", "age": 27 } CURRENT VERSION 7.6
- 37. Index Operations - Index aliases An index alias is a secondary name used to refer to one or more existing indices POST index-1/_alias/index-alias POST index-2/_alias/index-alias POST index-3/_alias/index-alias CURRENT VERSION 7.6
- 38. Index Operations - Index aliases filter: If specified, the index alias only applies to documents returned by the filter. POST index-*/_alias/index-Egypt { "filter": { "term": { "nationality": "egypt" } } } CURRENT VERSION 7.6
- 39. Index Operations - Index aliases DELETE index-1/_alias/index-alias DELETE index-*/_alias/index-alias GET index-alias/_search GET index-alias/_search CURRENT VERSION 7.6
- 40. Index Template Index templates define settings and mappings that you can automatically apply when creating new indices Elasticsearch applies templates to new indices based on an index pattern that matches the index name Changes to index templates do not affect existing indices Settings and mappings specified in create index API requests override any settings or mappings specified in an index template CURRENT VERSION 7.6
- 41. Index Template CURRENT VERSION 7.6 PUT elastic-log-sys1
- 42. Index Template - Order Multiple index templates can potentially match an index Both the settings and mappings are merged into the final configuration of the index The order of the merging can be controlled using the order parameter With lower order being applied first, and higher orders overriding them CURRENT VERSION 7.6
- 43. Index Template - Order CURRENT VERSION 7.6 PUT elastic-log-sys1
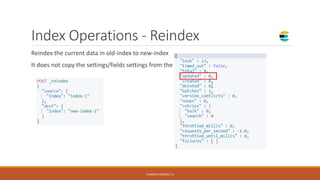
- 44. Index Operations - Reindex Reindex the current data in old-index to new-index It does not copy the settings/fields settings from the source index to destination CURRENT VERSION 7.6
- 45. Index Operations - Reindex version_type: internal or empty: ◦ Update any document that have the same _id regardless the version number in the target index ◦ Increase the version number for the documents with the same _id CURRENT VERSION 7.6
- 46. Index Operations - Reindex CURRENT VERSION 7.6
- 47. Index Operations - Reindex version_type: external ◦ Elasticsearch to preserve the version from the source ◦ Create any documents that are missing ◦ The _id value is not matched ◦ Update any documents that have an older version in the destination index than they do in the source index ◦ The document with older version will get the same version number from the source index CURRENT VERSION 7.6
- 48. Index Operations - Reindex Created index-1 Add data to index-1 Delete new-index-1 CURRENT VERSION 7.6
- 49. Index Operations - Reindex Add document to index-1 Do reindex CURRENT VERSION 7.6
- 50. Index Operations - Reindex op_type: create ◦ _reindex to only create missing documents in the target index ◦ All existing documents will cause a version conflict max_docs ◦ To limit the number of processed documents from source to dest CURRENT VERSION 7.6
Editor's Notes
- #5: 1 - The heart of the Elastic Stack 2 - Run it on your laptop. Or hundreds of servers with petabytes of data. 3 - Search across everything. Find that specific thing
- #6: Kibana should be configured to run against an Elasticsearch node of the same version. This is the officially supported configuration. https://www.elastic.co/guide/en/kibana/current/setup.html You can’t use Kibana without Elasticsearch
- #7: 1 - Beats is the platform for single-purpose data shippers. They send data from hundreds or thousands of machines and systems to Logstash or Elasticsearch. 2 - Beats are great for gathering data. They sit on your servers, with your containers, or deploy as functions — and then centralize data in Elasticsearch. And if you want more processing muscle, Beats can also ship to Logstash for transformation and parsing. 3 - The cornerstone of every open source Beat is libbeat, the common library for forwarding data. Have a specialized protocol you need to monitor? Build it
- #8: 1 - Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite "stash.“ 2 - Ingest Data of All Shapes, Sizes, and Sources 3 - Parse & Transform Your Data On the Fly 4 - Choose Your Stash, Transport Your Data
- #18: Every node is implicitly a coordinating node. This means that a node that has all three node.master, node.data and node.ingest set to false will only act as a coordinating node, which cannot be disabled. As a result, such a node needs to have enough memory and CPU in order to deal with the gather phase.
- #22: Iit is important to note that a replica shard is never allocated on the same node as the original/primary shard that it was copied from.
- #23: Iit is important to note that a replica shard is never allocated on the same node as the original/primary shard that it was copied from.
- #25: Table Type (deprecated)
- #26: refresh_interval: How often to perform a refresh operation, which makes recent changes to the index visible to search. Defaults to 1s
- #31: Health values: green|yellow|red (Optional, string) Health status used to limit returned indices h: (Optional, string) Comma-separated list of column names to display. s: (Optional, string) Comma-separated list of column names or column aliases used to sort the response.
- #33: Script 1: Where is the Nationality field? It is not here because we didn’t pass it during the document creation Script 2: Note the country column in the mappings section
- #34: PUT 1 - updates a full document, not only the field you're sending. 2 - can not create document without id POST 1 - will do a partial update and only update the fields you're sending, and not touch the other ones already present in the document. 2 - creates document with/without id
- #36: 1 - Note that we didn’t touch the field age and still appears 2 – You can add new field to the document
- #37: Check _version: 6 Versioning: Each document indexed is versioned. When deleting a document, the version can be specified to make sure the relevant document we are trying to delete is actually being deleted and it has not changed in the meantime. Every write operation executed on a document, deletes included, causes its version to be incremented. The version number of a deleted document remains available for a short time after deletion to allow for control of concurrent operations. The length of time for which a deleted document’s version remains available is determined by the index.gc_deletes index setting and defaults to 60 seconds.
- #41: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-templates.html
- #42: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-templates.html
- #43: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-templates.html
- #44: https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-templates.html
- #45: Great articles https://developers.soundcloud.com/blog/how-to-reindex-1-billion-documents-in-1-hour-at-soundcloud https://engineering.carsguide.com.au/elasticsearch-zero-downtime-reindexing-e3a53000f0ac Full reference https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-reindex.html
- #47: 1 – Reindex documents already exists in the dest index 2 – The version will be increased with the updated data