





























論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
- 1. 修士輪講 2016/07/13 豊田工業大学 知能数理研究室 (COMPUTATIONAL INTELLIGENCE LABORATORY) 16425 長野 直之 1/ 31
- 2. A table of Contents ・ Paper Overview ・ Abstract / 1. Introduction ・ 2. Neural Network Architecture ・ 3. Network Training ・ 4. Experiments ・ 6. Conclusion 2/ 31
- 3. Paper Overview ・タイトル 「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」 ・著者 1. Xuezhe Ma 2. Eduard Hovy (Language Technologies Institute Carnegie Mellon University) 3/ 31
- 4. 【提案手法】 Paper Overview ・概要 Bi-directional LSTM (Forward and Backward) CNN (Word embedding and Char Representation) CRF 系列ラベリングに有効な新たなニューラルネットワークの提案 4/ 31
- 5. Abstract / 1. Introduction ・提案(end-to-endモデル) 系列ラベリング(sequence labeling)の為の 新たなニューラルネットワークアーキテクチャ ・特徴(end-to-endモデル) 1.タスク固有の資源 2.素性エンジニアリング 3.ラベリングされていないコーパスの事前学習のデータ前処理 を必要としない 5/ 31
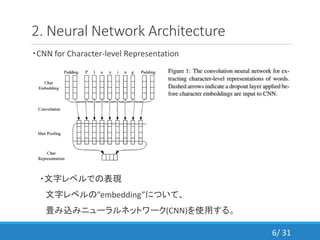
- 6. 2. Neural Network Architecture ・CNN for Character-level Representation ・文字レベルでの表現 文字レベルの”embedding”について、 畳み込みニューラルネットワーク(CNN)を使用する。 6/ 31
- 7. 2. Neural Network Architecture ・LSTM Unit 𝜎:要素ごとのシグモイド関数 :要素ごとの積 𝑥 𝑡:入力ベクトル ℎ 𝑡:隠れ層のベクトル 𝑈𝑖, 𝑈𝑓, 𝑈𝑐, 𝑈 𝑜, :重み関数(入力層) 𝑏𝑖, 𝑏𝑓, 𝑏 𝑐, 𝑏 𝑜, :バイアスベクトル 7/ 31
- 8. 2. Neural Network Architecture ・BLSTM ・過去(past)と未来(future)の文脈からLSTMで判断 →2つの隠れ層(Forward & Backward)を用意する必要がある PAST FUTURE 8/ 31
- 9. 2. Neural Network Architecture ・CRF 系列ラベリング(Sequence labeling)の問題に適用するために、 対数線形モデルの一つである条件付確率場(CRF)を適用する。 1. 入力データ 入力系列: , 系列ラベル: 2. 条件付き確率 ポテンシャル関数: 重みベクトル: , バイアス: 9/ 31
- 10. 2. Neural Network Architecture ・CRF 系列ラベリング(Sequence labeling)の問題に適用するために、 対数線形モデルの一つである条件付確率場(CRF)を適用する。 3. 条件付確率場の学習(Training) 学習データ: 目的関数(対数尤度): 4. 最大条件付確率 系列条件付確率場(a sequence CRF)のモデルは、 ビタビアルゴリズムを採用することで効率よく問題を解決できる。 10/ 31
- 11. 2. Neural Network Architecture ・提案手法(BLSTM-CNNs-CRF) Bi-directional LSTM (Forward and Backward) CNN (Word embedding and Char Representation) CRF :Dropout Layers (ドロップアウトによる学習) 11/ 31
- 12. 3. Network Training ・訓練(Training) ・ Theano library (Bergstra et al.,2010) ・ 単一モデルの計算において、GeForce GTX TITAN X GPUを使用 ・ POS tagging:12hours ・ NER:8hours ・単語埋め込み(Word Embedding) 1.GloVe: Global Vectors for Word Representation(Pennington et al., 2014) 100次元の埋め込みモデルを使用 Wikipediaやウェブテキストから60億語を訓練 12/ 31
- 13. 3. Network Training ・単語埋め込み(Word Embedding) 2.SENNA (Collobert et al., 2011) 50次元の埋め込みモデルを使用 WikipediaやロイターRCV-1から訓練 3. Google’s Word2Vec (Mikolov et al., 2013) 300次元の埋め込みモデルを使用 Google Newsから1000億語を訓練 13/ 31
- 14. 3. Network Training ・単語埋め込み(Word Embedding) Word Embeddingの有効性をテストする為に、 1. 100次元の埋め込み(embedding)をランダムに初期化し実験 2. 100次元の埋め込み(embedding)のサンプルについて、 ※dim:埋め込み(embedding)の次元数 ・文字埋め込み(Character Embedding) Character Embeddingの初期化のサンプルについて、 − 3 𝑑𝑖𝑚 , + 3 𝑑𝑖𝑚 − 3 𝑑𝑖𝑚 , + 3 𝑑𝑖𝑚 𝑑𝑖𝑚 = 30 14/ 31
- 15. 3. Network Training ・重み行列(Weight Matrices) 行列のパラーメータはランダムに初期化し、サンプルについて、 ・バイアスベクトル(Bias Vectors) 1. 0で初期化 2. LSTMの忘却ゲート(forget gate)については1.0で初期化 − 6 𝑟+𝑐 , + 6 𝑟+𝑐 ・ 𝑟 :行列内の行数 ・ 𝑐 :行列内の列数 15/ 31
- 16. 3. Network Training ・ 最適化アルゴリズム(Optimization Algorithm) ・ 確率的勾配降下法(SGD)を使用 バッチサイズは10で更新量は0.9 学習係数:𝜂0 = 0.01(POS Tagging), 𝜂0 = 0.015(NER) ・ 確率的勾配降下法(SGD)の学習係数は以下の式で更新 𝜂 𝑡 = 𝜂0 1+𝜌𝑡 ※減衰率:𝜌 = 0.05 ・ 「勾配爆発(Gradient Exploding)」の影響を低減させるのに、 5.0のクリッピングを使用(Pascanu et al., 2012) 16/ 31
- 17. 3. Network Training ・ 最適化アルゴリズム(Optimization Algorithm) 1. Early Stopping(Giles,2001; Graves et al., 2013) 最良のパラーメータは50epochであるので、本実験にて使用 2. Fine Tuning(Collobert et al., 2011; Peng and Dredze, 2015) それぞれの埋め込み(embedding)の初期の微調整は、 ニューラルネットの勾配更新時に、 誤差逆伝搬法(back propagation)を使用 3. Dropout(Srivastava et al., 2014) 過学習を軽減する為に、 CNNの入力前とLSTMの入力前と出力後に適用する 本実験では出力を0にする割合を0.5とする 17/ 31
- 18. 3. Network Training ・ ハイパーパラメータの調整(Tuning Hyper-Parameters) 1. LSTMのサイズを200次元 2. CNNのウィンドウサイズを3 3. CNNのフィルタ数を30 に設定する 前回までのスライドで説明 18/ 31
- 19. 4. Experiments ・ DataSets 1. POS Tagging ・ Wall Street Journal (WSJ) portion of Penn Treebank (PTB) 45個の品詞が上記のデータセットに含まれている。 (Marcus et al., 1993) データセットの分割については標準的な手法を採用 ・セクション0-18を訓練データ ・セクション19-21を開発データ ・セクション22-24をテストデータ (Manning, 2011; Søgaard, 2011) 19/ 31
- 20. 4. Experiments ・ DataSets 1. NER ・ CoNLL 2003(Tjong Kim Sang and De Meulder, 2003) 4つの異なった固有表現が含まれている。 ・PERSON ・LOCATION ・ORGANIZATION ・MISC ・ BIOES タグ付けを従来のBIO2の代わりに使用 (Ratinov and Roth, 2009;Dai et al., 2015; Lample et al., 2016) 20/ 31
- 22. 4. Experiments ・ Main Results 提案手法(BRNN-CNN-CRF)では、 過去の研究結果(Santos and Zadrozny, 2014; Chiu and Nichols, 2015)よりも 良い結果を得ることができた。 BLSTM-CNNにCRF層を追加することは有効である 22/ 31
- 23. 4. Experiments ・ Comparison with Previous Work 1. POS Tagging 0.23%向上 CharWNN SENNA (Collobert et al., 2011)で比較 23/ 31
- 24. 4. Experiments ・ Comparison with Previous Work 1. POS Tagging 0.05%向上 BLSTM-CRFのモデルで比較 24/ 31
- 25. 4. Experiments ・ Comparison with Previous Work 2. NER LSTM-CRF CoNLL-2003で比較 LSTM-CNNs 25/ 31
- 26. 4. Experiments ・ Word Embedding Word Embeddingの有効性をテストした結果 ランダム抽出を実施 GloVeで良い結果を得た 【Word2VecのNERでスコアが良くなかった理由】 ・語彙の不一致 →句読点や数字といった一般的な記号を除き、 大文字と小文字を区別した訓練を実施した。 26/ 31
- 27. 4. Experiments ・ Effect of Dropout Dropoutの有効性をテストした結果 Dropoutの適用はスコアの向上に有効である 27/ 31
- 28. 4. Experiments ・ OOV Error Analysis 提案手法の挙動を確認するために、 Out-of-Vocabulary words (OOV)によるエラー解析を実施 28/ 31
- 29. 4. Experiments ・ OOV Error Analysis Out-of-Vocabulary words (OOV)によるエラー解析を実施 【用語】 ・IV :in-vocabulary words 学習(Training)と埋め込み(Embedding)に出現する単語 ・OOTV:out-of-training-vocabulary words 埋め込み(Embedding)に出現する単語 ・OOEV: out-of-embedding-vocabulary words 学習(Training)に出現する単語 ・OOBV: out-of-both-vocabulary words 学習(Training)と埋め込み(Embedding)に出現しない単語 29/ 31
- 30. 4. Experiments ・ OOV Error Analysis OOBVで大幅に向上した OOBVの学習や埋め込みにおいて良い結果を得ることが出来る 30/ 31
- 31. 6. Conclusion ・ 今後の展望 1. 複数のタスクでの学習でのアプローチ より有用かつ関連性のある情報を考えることで、 POS taggingとNERの両方のニューラルネットを改善できる。 2. ソーシャルメディア(Twitter and Weibo)への適用 ドメイン依存やタスク固有の知識を必要としないので、 TwitterやWeiboといったソーシャルメディアの学習に適用する。 31/ 31