End-to-End Spark/TensorFlow/PyTorch Pipelines with Databricks Delta
5 likes2,186 views

The document discusses the importance of data in machine learning and presents an overview of tools like Hopsworks, Databricks Delta, and various feature stores. It highlights advancements in data lakes with ACID transactions, incremental ingestion, and efficient querying using frameworks such as Delta, Hudi, and Iceberg. The Hopsworks feature store is emphasized as the world's first open-source feature store, supporting end-to-end ML pipelines with reliable and timely data access.



![Where does the Data come from?
5
“Data is the hardest part of ML and the most important piece to get
right. Modelers spend most of their time selecting and transforming
features at training time and then building the pipelines to deliver
those features to production models.” [Uber on Michelangelo]](https://image.slidesharecdn.com/jimdowlingkimhammar-191101052517/85/End-to-End-Spark-TensorFlow-PyTorch-Pipelines-with-Databricks-Delta-5-320.jpg)




































End-to-End Spark/TensorFlow/PyTorch Pipelines with Databricks Delta
- 1. WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
- 2. Kim Hammar, Logical Clocks AB KimHammar1 Jim Dowling, Logical Clocks AB jim_dowling End-to-End ML Pipelines with Databricks Delta and Hopsworks Feature Store #UnifiedDataAnalytics #SparkAISummit
- 3. Machine Learning in the Abstract 3
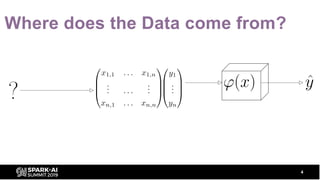
- 4. Where does the Data come from? 4
- 5. Where does the Data come from? 5 “Data is the hardest part of ML and the most important piece to get right. Modelers spend most of their time selecting and transforming features at training time and then building the pipelines to deliver those features to production models.” [Uber on Michelangelo]
- 6. Data comes from the Feature Store 6
- 7. How do we feed the Feature Store? 7
- 8. Outline 8 1. Hopsworks 2. Databricks Delta 3. Hopsworks Feature Store 4. Demo 5. Summary
- 9. 9 Datasources Applications API Dashboards Hopsworks Apache Beam Apache Spark Pip Conda Tensorflow scikit-learn Keras J upyter Notebooks Tensorboard Apache Beam Apache Spark Apache Flink Kubernetes Batch Distributed ML &DL Model Serving Hopsworks Feature Store Kafka + Spark Streaming Model Monitoring Orchestration in Airflow Data Preparation &Ingestion Experimentation &Model Training Deploy &Productionalize Streaming Filesystem and Metadata storage HopsFS
- 10. 10
- 11. 11
- 12. 12
- 13. 13
- 14. 14
- 15. 15
- 16. Next-Gen Data Lakes Data Lakes are starting to resemble databases: – Apache Hudi, Delta, and Apache Iceberg add: • ACID transactional layers on top of the data lake • Indexes to speed up queries (data skipping) • Incremental Ingestion (late data, delete existing records) • Time-travel queries 16
- 17. Problems: No Incremental Updates, No rollback on failure, No Time-Travel, No Isolation. 17
- 18. Solution: Incremental ETL with ACID Transactions 18
- 19. Upsert & Time Travel Example 19
- 20. Upsert & Time Travel Example 20
- 21. Upsert ==Insert or Update 21
- 22. Version Data By Commits 22
- 23. Delta Lake by Databricks • Delta Lake is a Transactional Layer that sits on top of your Data Lake: – ACID Transactions with Optimistic Concurrency Control – Log-Structured Storage – Open Format (Parquet-based storage) – Time-travel 23
- 27. Mutual Exclusion for Writers 27
- 30. Other Frameworks: Apache Hudi, Apache Iceberg • Hudi was developed by Uber for their Hadoop Data Lake (HDFS first, then S3 support) • Iceberg was developed by Netflix with S3 as target storage layer • All three frameworks (Delta, Hudi, Iceberg) have common goals of adding ACID updates, incremental ingestion, efficient queries. 30
- 31. Next-Gen Data Lakes Compared 31 Delta Hudi Iceberg Incremental Ingestion Spark Spark Spark ACID updates HDFS, S3* HDFS S3, HDFS File Formats Parquet Avro, Parquet Parquet, ORC Data Skipping (File-Level Indexes) Min-Max Stats+Z-Order Clustering* File-Level Max-Min stats + Bloom Filter File-Level Max-Min Filtering Concurrency Control Optimistic Optimistic Optimistic Data Validation Expectations (coming soon) In Hopsworks N/A Merge-on-Read No Yes (coming soon) No Schema Evolution Yes Yes Yes File I/O Cache Yes* No No Cleanup Manual Automatic, Manual No Compaction Manual Automatic No *Databricks version only (not open-source)
- 32. 32 How can a Feature Store leverage Log-Structured Storage (e.g., Delta or Hudi or Iceberg)?
- 33. Hopsworks Feature Store 33 Feature Mgmt Storage Access Statistics Online Features Discovery Offline Features Data Scientist Online Apps Data Engineer MySQL Cluster (Metadata, Online Features) Apache Hive Columnar DB (Offline Features) Feature Data Ingestion Hopsworks Feature Store Training Data (S3, HDFS) Batch Apps Discover features, create training data, save models, read online/offline/on- demand features, historical feature values. Models HopsFS JDBC (SAS, R, etc) Feature CRUD Add/remove features, access control, feature data validation. Access Control Time Travel Data Validation Pandas or PySpark DataFrame External DB Feature Defn Țselect ..Ț AWS Sagemaker and Databricks Integration • Computation engine (Spark) • Incremental ACID Ingestion • Time-Travel • Data Validation • On-Demand or Cached Features • Online or Offline Features
- 34. Incremental Feature Engineering with Hudi 34
- 35. Point-in-Time Correct Feature Data 35
- 36. Feature Time Travel with Hudi and Hopsworks Feature Store 36
- 37. Demo: Hopsworks Featurestore + Databricks Platform 37
- 38. Summary • Delta, Hudi, Iceberg bring Reliability, Upserts & Time-Travel to Data Lakes – Functionalities that are well suited for Feature Stores • Hopsworks Feature Store builds on Hudi/Hive and is the world’s first open-source Feature Store (released 2018) • The Hopsworks Platform also supports End-to-End ML pipelines using the Feature Store and Spark/Beam/Flink, Tensorflow/PyTorch, and Airflow 38
- 39. Thank you! 470 Ramona St, Palo Alto Kista, Stockholm https://www.logicalclocks.com Register for a free account at www.hops.site Twitter @logicalclocks @hopsworks GitHub https://github.com/logicalclocks/hopswo rks https://github.com/hopshadoop/hops
- 40. References • Feature Store: the missing data layer in ML pipelines? https://www.logicalclocks.com/feature-store/ • Python-First ML Pipelines with Hopsworks https://hops.readthedocs.io/en/latest/hopsml/hopsML.html. • Hopsworks white paper. https://www.logicalclocks.com/whitepapers/hopsworks • HopsFS: Scaling Hierarchical File System Metadata Using NewSQL Databases. https://www.usenix.org/conference/fast17/technical-sessions/presentation/niazi • Open Source: https://github.com/logicalclocks/hopsworks https://github.com/hopshadoop/hops • Thanks to Logical Clocks Team: Jim Dowling, Seif Haridi, Theo Kakantousis, Fabio Buso, Gautier Berthou, Ermias Gebremeskel, Mahmoud Ismail, Salman Niazi, Antonios Kouzoupis, Robin Andersson, Alex Ormenisan, Rasmus Toivonen, Steffen Grohsschmiedt, and Moritz Meister 40
- 41. DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT