




















![実行結果
以下のようになったらOK
・Using TensorFlow backend. という表示が出てくる
・左側の表示がIn[]→In[*]→In[1]のように変遷する
・エラーメッセージが出てこなければOK
・FutureWarning(次ページ)は今回は無視してOK](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-22-320.jpg)































![実行すると、左上がIn[] → In[*] → In[1] という風に変わっていく](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-56-320.jpg)

![左上のIn[]がIn[2]になればOK](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-58-320.jpg)
![ディープラーニングの実行
#モデルのコンパイル、学習実行
model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"])
hist = model.fit(X_train, y_train, batch_size=16, verbose=1, epochs=3 validation_split=0.3)](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-59-320.jpg)
![学習結果の評価
#学習結果の評価
score = model.evaluate(X_test, y_test, verbose=1)
print("正解率(acc):", score[1])
今回は正解率(どれだけ合ってたか、で評価)](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-60-320.jpg)






















![画像をトリミングする
#前略
cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1,
cv2.LINE_AA)
_, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化
th = cv2.bitwise_not(th) # 白黒反転
th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける
th = th[50:150, 50:150] # トリミング
cv2.imshow(“test”, image)
cv2.imshow(“gray”, gray)
cv2.imshow(“thres”, th)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.waitKey(1) # Macの人のみ](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-84-320.jpg)
![(0, 0) 50
50
150
150
th = th[50:150, 50:150]
トリミングの書き方
他と順番が逆(高さ, 幅)なので注意](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-85-320.jpg)
![画像をトリミングする
#前略
cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1,
cv2.LINE_AA)
_, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化
th = cv2.bitwise_not(th) # 白黒反転
th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける
th = th[50:150, 50:150] # トリミング
cv2.imshow(“test”, image)
cv2.imshow(“gray”, gray)
cv2.imshow(“thres”, th)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.waitKey(1) # Macの人のみ
Cell → Run Cells もしくはShift + Enter で実行](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-86-320.jpg)
![画像を縮小する
#前略
cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1,
cv2.LINE_AA)
_, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化
th = cv2.bitwise_not(th) # 白黒反転
th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける
th = th[50:150, 50:150] # トリミング
th = cv2.resize(th, (50,50), cv2.INTER_CUBIC) # 50×50にリサイズ
cv2.imshow(“test”, image)
cv2.imshow(“gray”, gray)
cv2.imshow(“thres”, th)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.waitKey(1) # Macの人のみ
Cell → Run Cells もしくはShift + Enter で実行](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-87-320.jpg)


![MNISTの中身を見てみよう
from keras.datasets import mnist
import cv2
(X_train, _), (_, _) = mnist.load_data() # MNISTをロード
cv2.imshow(“MNIST”, X_train[100]) # 画像を表示
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.waitKey(1) # Macの人のみ
・MNISTをロード(画像部分だけ)
・画像の高さと幅を取ってくる
・高さと幅を表示
・画像を表示](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-91-320.jpg)












![import cv2
cap = cv2.VideoCapture(1)
while(True):
ret, frame = cap.read()
#ここにコードを書く
h, w, _ = frame.shape[:3] # 画像の形(高さ,幅,チャンネル数)を取得
h_center = h//2 # y軸の中心点を取得
w_center = w//2 # x軸の中心点を取得
cv2.rectangle(frame, (w_center-71, h_center-71), (w_center+71, h_center+71), (255, 0, 0))
cv2.imshow(“frame”, frame)
k = cv2.waitKey(1) & 0xFF
#後略
中心点を求めて142×142サイズの四角を描く
※最終的に、140×140のサイズできれいに切り抜きたいので、四角は一回り大きくしておく
wとhの順番に注意](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-104-320.jpg)

![各種画像処理を加えていく
#前略
ret, frame = cap.read()
h, w, _ = frame.shape[:3] # 画像の形(高さ,幅,チャンネル数)を取得
h_center = h//2 # y軸の中心点を取得
w_center = w//2 # x軸の中心点を取得
cv2.rectangle(frame, (w_center-71, h_center-71), (w_center+71, h_center+71), (255, 0, 0))
#ここにコードを書く
im = frame[h_center-70:h_center+70, w_center-70:w_center+70] # トリミング
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) # グレースケール化
_, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU) # 二値化
th = cv2.bitwise_not(th) # 白黒反転
th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける
th = cv2.resize(th,(28,28), cv2.INTER_CUBIC) # 28×28にリサイズ
cv2.imshow(“frame”, frame)
cv2.imshow(“im”, im )# 途中経過を見るために追記
k = cv2.waitKey(1) & 0xFF
#後略
th](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-106-320.jpg)


![学習させたデータと比較できるように、カメラの映像データを加工する
import cv2
from keras.models import load_model
import numpy as np
model = load_model(“mnist.h5")
cap = cv2.VideoCapture(1)
while(True):
# 判定用データを格納する配列の初期化
Xt = []
Yt = []
ret, frame = cap.read()
#後略](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-109-320.jpg)
![判定できるように形を変換する・判定する
#前略
im = frame[h_center-70:h_center+70, w_center-70:w_center+70]
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
_, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU)
th = cv2.bitwise_not(th)
th = cv2.GaussianBlur(th,(9,9),0)
th = cv2.resize(th,(28,28), cv2.INTER_CUBIC)
Xt.append(th)
Xt = np.array(Xt)/255
Xt = np.expand_dims(Xt, axis=-1)
result = model.predict(Xt, batch_size=1) # Xtと学習したデータを比較して判定結果を返す
cv2.imshow(“frame”, frame)
#後略](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-110-320.jpg)
![predictがどういう値を返すか
配布データの中の、predict_test.ipynb
※手元で実行する必要はありません。
MNISTの場合、左上から[0の可能性 1の可能性 2の可能性 …]という風に並んでいる
1番近い可能性だけ返してほしい](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-111-320.jpg)
![resultの中には、順番に0~9に一致する確率がセットされている
該当する数字(0~9)までと、その確率をセットにして、確率が高いものが右端に並
ぶようにソートする
[ [ 3, 0.1 ] [ 0 , 0.2 ] [2, 0.6] [ 1, 0.7 ] ]
[ [ 0 , 0.2 ] [ 1, 0.7 ] [2, 0.6] [ 3, 0.1 ] ]
例)
確率順で並べ替えておけば、表示するときに呼び出しやすくなる!](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-112-320.jpg)
![表示用データの作成・判定結果のソート
#前略
Xt.append(th)
Xt = np.array(Xt)/255
result = model.predict(Xt, batch_size=1)
for i in range(10):
r = round(result[0,i],2) # 小数点以下第2位までで四捨五入
r = “{0:0.2f}”.format(r) # OpenCVで表示できる型に変換
Yt.append([i, r]) # その数字が何かと一致する確率をセットで格納
Yt = sorted(Yt, key=lambda x:(x[1]))# ソート実行
cv2.imshow(“frame”, frame)
#後略
一番一致してる確率が高いものがYt[9]に[数字,一致する確率]という形で収納される
for内のインデントは下げる!](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-113-320.jpg)
![判定結果の上位1番目を画面上に表示
#前略
for i in range(10):
r = round(result[0,i],2)
r = "{0:.2f}".format(r)
Yt.append([i, r])
Yt = sorted(Yt, key=lambda x:(x[1]))
cv2.putText(frame, "1st:"+str(Yt[9]), (10,40), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(255,255,255), 1, cv2.LINE_AA)
cv2.imshow(“frame”, frame)
#後略](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-114-320.jpg)

![判定結果の上位3番目までを画面上に表示
#前略
for i in range(10):
r = round(result[0,i],2)
r = "{0:.2f}".format(r)
Yt.append([i, r])
Yt = sorted(Yt, key=lambda x:(x[1]))
cv2.putText(frame, "1st:"+str(Yt[9]), (10,40), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(255,255,255), 1, cv2.LINE_AA)
cv2.putText(frame, "2nd:"+str(Yt[8]), (220,40), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(255,255,255), 1, cv2.LINE_AA)
cv2.putText(frame, "3rd:"+str(Yt[7]), (360,40), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(255,255,255), 1, cv2.LINE_AA)
cv2.imshow(“frame”, frame)
#後略](https://image.slidesharecdn.com/enjoymnist-200217014817/85/Enjoy-handwritten-digits-recognition-AI-116-320.jpg)
Enjoy handwritten digits recognition AI !!
- 2. 作業環境・必要機材 • JupyterNotebook(Python環境) • TensorFlow、Keras、h5py、OpenCV for Pythonのインストール・動作 確認済みを前提 • カメラ付きのマシンまたは外付け(USB)カメラ+マシン なお、ぼくの環境はWin10ですので、それを前提にお話していきます。
- 3. • 甲斐 研造(Ka-k) 名前 • 福岡県産業・科学技術振興財団(ふくおかIST) • システム開発技術カレッジ事務局 所属 • ゲーム、イラスト 趣味 • 色彩検定1級、UC級 • パーソナルカラー検定モジュール3 特技 自己紹介 大分県のマスコット めじろん Qiita ID:Ka-k 今日の内容とほぼ同じものを載せてます いいねよろしくお願いします
- 7. 今日つくるコンテンツ
- 8. 環境の準備
- 12. 必要なライブラリのインストール
- 13. pip install tensorflow==1.14 pip install h5py pip install keras pip install opencv-python 必要なライブラリのインストール Pythonターミナル(黒い画面)上で、以下のコマンドを順番に実行 ※プロンプト(こういうやつ→ >_ )が返ってきてから、次のコマンド、という風に実行 Pythonターミナル画面
- 14. Jupyter Notebookの準備 ①左のメニューからHomeを選択 ②Jupyterのアイコン下にある 「Install」をクリック ③「Install」が「Launch」に変 わったらOK
- 22. 実行結果 以下のようになったらOK ・Using TensorFlow backend. という表示が出てくる ・左側の表示がIn[]→In[*]→In[1]のように変遷する ・エラーメッセージが出てこなければOK ・FutureWarning(次ページ)は今回は無視してOK
- 24. Kerasのimportでエラーが出る場合 pip uninstall tensorflow pip install tensorflow==1.14 Pythonターミナル上で、以下のコマンドを順番に実行 ※Kerasで動作するバージョンのTensorFlowをインストールし直す
- 25. AIと機械学習と深層学習
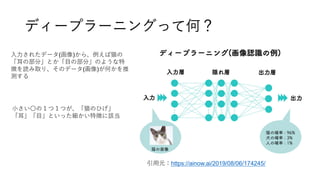
- 26. コンピュータの得意な事と不得意な事 • 2×3=?と聞いて、「6」と回答させる • 「猫の画像を見せて」と言われたらあらかじめ用意した「猫の画像」を見せる コンピュータは、既知の情報に既知の答えを返すのは強い • デジタルでも手書きでも、「6」という数字は人間から見れば「6」だけど、 コンピュータは手書きの数字を「6」と認識するのが苦手 • 「猫の絵を描いて」と言われても返せない 一方で、未知のデータに対して、答えを返すのは弱い
- 31. ディープラーニングのざっくりした理解 試験勉強用の問題集を用意 する • 学習用データセット • 正解ラベル 問題集を使って、コン ピュータに試験勉強させる • ディープラーニング 大学入試を受けさせる • 画像判別 • 数値予測 Q.これは誰? A.ガッキー 試験勉強の仕方は、人間が指示する (モデル構築) 独学だったり ・独自モデル 有名な塾だったり ・既存モデル引用:https://qiita.com/tokkuman/items/1d83cd84bf2731f11774
- 32. ディープラーニングのプロセス • データ収集 • 学習モデルセット作成 予想問題集を作る • ディープラーニングモデル構築 勉強の仕方を教える • ディープラーニング 勉強をさせる • テストデータで学習精度を評価 実際にテストを受けさせる
- 33. ディープラーニングの注意点 • 配列データでないといけない • 配列の要素の値が0~1じゃないといけない 等 Kerasで扱える形は決まっている • 例えば画像判別なら最低でも以下は揃えないといけない • 白黒か、フルカラーか • 解像度(120px×120pxで統一、みたいな感じ) 学習したデータと同じ形じゃないと判別できない
- 34. TensorFlowとKeras
- 35. TensorFlow • 読み方は「テンソルフロー」または「テンサーフロー」。 • Googleが提供している機械学習ライブラリ • 自分で1からコーディングしなくてもDLモデルを構築できる • CPUだけじゃなくてGPUも使える テンソル 出典: フリー百科事典『ウィキペディア(Wikipedia)』 ナビゲーションに移動検索に移動 テンソル(英: tensor, 独: Tensor)とは、線形的な量または線形的な幾何概念を一般化したもので、基底を選べば、多次元の配列として表現できるようなも のである。しかし、テンソル自身は、特定の座標系によらないで定まる対象である。個々のテンソルについて、対応する量を記述するのに必要な配列の添 字の組の数は、そのテンソルの階数とよばれる。 例えば、質量や温度などのスカラー量は階数0のテンソルだと理解される。同様にして力や運動量などのベクトル的な量は階数1のテンソルであり、力や加 速度ベクトルの間の異方的な関係などをあらわす線型変換は階数2のテンソルで表される。 物理学や工学においてしばしば「テンソル」と呼ばれているものは、実際には位置や時刻を引数としテンソル量を返す関数である「テンソル場」であるこ とに注意しなければならない。いずれにせよテンソル場の理解のためにはテンソルそのものの概念の理解が不可欠である。
- 38. Kerasとは • データ収集 • 学習モデルセット作成 予想問題集を作る • ディープラーニングモデル構築 勉強の仕方を教える • ディープラーニング 勉強をさせる • テストデータで学習精度を評価 実際にテストを受けさせる 主にこの部分をやって くれるのがTensorFlow とKeras
- 39. まずはKerasを体験
- 40. まずはKerasを体験 • Kerasにはディープラーニングを体験するための、いくつかの データセットが用意されている • そのうちの1つが「MNIST」と呼ばれる、手書き数字のデータ セット • 今回は、この「MNIST」を遊びつくそう、というのがコンセプ ト
- 43. MNISTとは • データ収集 • 学習モデルセット作成 予想問題集を作る • ディープラーニングモデル構築 勉強の仕方を教える • ディープラーニングの実行 勉強をさせる • テストデータで学習精度を評価 実際にテストを受けさせる この部分にあたるの がMNIST
- 53. ディープラーニングの注意点 • 配列データでないといけない • 配列の要素の値が0~1じゃないといけない 等 Kerasで扱える形は決まっている • 例えば画像判別なら最低でも以下は揃えないといけない • 白黒か、フルカラーか • 解像度(120px×120pxで統一、みたいな感じ) 学習したデータと同じ形じゃないと判別できない
- 54. MNISTをKerasで使える形に整える import numpy as np from keras.datasets import mnist from keras.utils import np_utils #MNISTデータセット呼び出し (X_train, y_train), (X_test, y_test) = mnist.load_data() #データの正規化 X_train = np.array(X_train)/255. X_test = np.array(X_test)/255. #CNNに入れるために次元を追加 X_train = np.expand_dims(X_train, axis=-1) X_test = np.expand_dims(X_test, axis=-1) #ラベルのバイナリ化 y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) ※初回はMNISTのロードが入ります
- 56. 実行すると、左上がIn[] → In[*] → In[1] という風に変わっていく
- 57. DLモデルの構築 from keras.layers import Input, Dense, Conv2D, MaxPooling2D from keras.models import Model from keras.layers.core import Flatten inputs = Input(shape=(28,28,1)) #入力層 conv1 = Conv2D(16, (3, 3), padding='same', activation='relu')(inputs) #畳込み層1 pool1 = MaxPooling2D((2, 2))(conv1) conv2 = Conv2D(32, (3, 3), padding='same', activation='relu')(pool1) #畳込み層2 pool2 = MaxPooling2D((2, 2))(conv2) flat = Flatten()(pool2) #全結合層に渡すため配列を一次元化 dense1 = Dense(784, activation='relu')(flat) #全結合層 predictions = Dense(10, activation='softmax')(dense1) #出力層 model = Model(inputs=inputs, outputs=predictions) #モデルの宣言(入力と出力を指定)
- 59. ディープラーニングの実行 #モデルのコンパイル、学習実行 model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"]) hist = model.fit(X_train, y_train, batch_size=16, verbose=1, epochs=3 validation_split=0.3)
- 60. 学習結果の評価 #学習結果の評価 score = model.evaluate(X_test, y_test, verbose=1) print("正解率(acc):", score[1]) 今回は正解率(どれだけ合ってたか、で評価)
- 65. ディープラーニングの実行と、モデルの保存で、コンピュータが手書 き数字を認識できるAI(脳の部分)が完成した 自分で書いた手書き数字を認識させ、答えさせるためには、画像を 取得する「目の部分」が必要
- 66. ディープラーニングの注意点をおさらい • 例えば画像判別なら最低でも以下は一致していないといけない • 白黒か、フルカラーか • 解像度(120px×120px等) 学習したデータと同じ形じゃないと判別できない
- 69. MNISTの画像としての特徴 • 28×28サイズ • グレースケール • 黒バックに白い文字 • 白い部分は少しぼやけてる • 背景の黒は「完全に黒」(値がゼロ) • 画像の縦横が同じ正方形、白い部分は完 全に白のところとグレーのところが混在 ポイント 引用元:https://www.codexa.net/cnn-mnist-keras-beginner/
- 70. 画像加工処理 トリミング・ グレースケール化 2値化 白黒反転 ブラー 28×28に縮小 カメラから映像を取得して、Kerasで認識でき るように加工するまでのプロセスイメージ
- 73. OpenCVとは • 画像処理用のライブラリ • カメラの呼び出しや加工が簡単に行える • 動画を扱うことができる
- 77. 画像を表示 import cv2 # OpenCVのインポート image = cv2.imread(“Lenna.png”, 1) # 画像のロード cv2.imshow(“test”, image) # 画像の表示 cv2.waitKey(0) # 何かしらの操作があるまで待つ cv2.destroyAllWindows()# ウィンドウを破棄する cv2.waitKey(1) # Macの人はこの行が必要 ※ウィンドウはバックエンドに出てくることがあります Cell → Run Cells もしくはShift + Enter で実行 コメントは書かなくてOK (以降も同じ)
- 78. 読み込んだ画像をグレーに変える import cv2 image = cv2.imread(“Lenna.png”, 1) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # グレースケールに変換 cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) # 別のウィンドウで表示 cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 79. 画像に四角を描く import cv2 image = cv2.imread(“Lenna.png”, 1) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) cv2.rectangle(image, (50, 50), (100, 100), (255,0,0)) cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ (0, 0) 50 50 100 100 OpenCVは左上の座標が原点(0,0) Cell → Run Cells もしくはShift + Enter で実行
- 80. 画像に文字を書く import cv2 image = cv2.imread(“Lenna.png”, 1) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) cv2.rectangle(image, (50, 50), (100, 100), (255,0,0)) cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) # (窓, 書き込む文字列, 座標, フォント, サイズ, 色, 太さ, 線の種類) cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 81. 画像を二値化する #前略 cv2.rectangle(image, (50, 50), (100, 100), (255,0,0)) cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) _, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化 cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.imshow(“thres”, th) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 82. 画像を白黒反転する #前略 cv2.rectangle(image, (50, 50), (100, 100), (255,0,0)) cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) _, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化 th = cv2.bitwise_not(th) # 白黒反転 cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.imshow(“thres”, th) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 83. 画像にブラーをかける #前略 cv2.rectangle(image, (50, 50), (100, 100), (255,0,0)) cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) _, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化 th = cv2.bitwise_not(th) # 白黒反転 th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.imshow(“thres”, th) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 84. 画像をトリミングする #前略 cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) _, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化 th = cv2.bitwise_not(th) # 白黒反転 th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける th = th[50:150, 50:150] # トリミング cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.imshow(“thres”, th) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ
- 85. (0, 0) 50 50 150 150 th = th[50:150, 50:150] トリミングの書き方 他と順番が逆(高さ, 幅)なので注意
- 86. 画像をトリミングする #前略 cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) _, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化 th = cv2.bitwise_not(th) # 白黒反転 th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける th = th[50:150, 50:150] # トリミング cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.imshow(“thres”, th) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 87. 画像を縮小する #前略 cv2.putText(image, “Hello World”, (0,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 1, cv2.LINE_AA) _, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU) # 大津の方法で二値化 th = cv2.bitwise_not(th) # 白黒反転 th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける th = th[50:150, 50:150] # トリミング th = cv2.resize(th, (50,50), cv2.INTER_CUBIC) # 50×50にリサイズ cv2.imshow(“test”, image) cv2.imshow(“gray”, gray) cv2.imshow(“thres”, th) cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ Cell → Run Cells もしくはShift + Enter で実行
- 88. コードを保存!
- 91. MNISTの中身を見てみよう from keras.datasets import mnist import cv2 (X_train, _), (_, _) = mnist.load_data() # MNISTをロード cv2.imshow(“MNIST”, X_train[100]) # 画像を表示 cv2.waitKey(0) cv2.destroyAllWindows() cv2.waitKey(1) # Macの人のみ ・MNISTをロード(画像部分だけ) ・画像の高さと幅を取ってくる ・高さと幅を表示 ・画像を表示
- 93. カメラにアクセスしてみる import cv2 cap = cv2.VideoCapture(1) # カメラを指定 ret, frame = cap.read() # カメラから読み込み cv2.imshow(“frame”, frame) # 表示 cv2.waitKey(0) # 操作されるまで待機 cap.release() cv2.waitKey(1) # Macの人は追記 cv2.destroyAllWindows() cv2.waitKey(1) # Macの人は追記
- 94. OpenCVの動画の考え方 • カメラから画像を取得できたが、静止画だった • カメラにアクセスした瞬間の画像を表示させているだけ • 動画として表示させるためには、カメラにアクセスしている間、 表示させた画像を更新し続ける必要がある
- 95. カメラからの映像を動画として表示する import cv2 cap = cv2.VideoCapture(1) #ここに追記 while(True): ret, frame = cap.read() cv2.imshow(“frame”, frame) cv2.waitKey(0) cap.release() cv2.waitKey(1) # Macの人は追記 cv2.destroyAllWindows() cv2.waitKey(1) # Macの人は追記 インデント下げる ret, frame = cap.read() cv2.imshow(“frame”, frame) Pythonでは、whileやif等の中に処理を入れる場合、インデントを下げるというルール
- 96. カメラからの映像を動画として表示する import cv2 cap = cv2.VideoCapture(1) while(True): ret, frame = cap.read() cv2.imshow(“frame”, frame) cv2.waitKey(0) if k == ord(“q”) : break cap.release() cv2.waitKey(1) # Macの人は追記 cv2.destroyAllWindows() cv2.waitKey(1) # Macの人は追記 ループの終了条件 キーボードの「q」が押されたらループを抜ける ようにする k = cv2.waitKey(1) & 0xFF
- 97. コードを保存!
- 98. リアルタイム認識
- 101. コーディング • カメラから画像を取得するコードを拡張する import cv2 cap = cv2.VideoCapture(1) while(True): ret, frame = cap.read() cv2.imshow(“frame”, frame) k = cv2.waitKey(1) & 0xFF if k == ord(“q”) : break cap.release() cv2.waitKey(1) # Macの人は追記 cv2.destroyAllWindows() cv2.waitKey(1) # Macの人は追記
- 102. まずは、カメラの映像を加工する処理を加えていく トリミング・ グレースケール化 2値化 白黒反転 ブラー 28×28に縮小
- 103. カメラの映像の中心に、四角を描く OpenCVでは、左上の点が原点(0, 0)になり、右下の座標が画像の幅と高さの値になる。 (0, 0) (800, 600) 800 600 画像の幅と高さを取得して、2で割れば、画像の 中心点がわかる! 400 300 中心が分かれば、そこから「どれだけ離れているか」 を指定すれば、中心に四角が描ける 画像の真ん中を(x,y)として、中心に100×100の四角を描きたい場合、左上の点 (x-50, y-50)と右下の点(x+50, y+50)を指定してやれば、四角を描ける (400,300) (400-50, 300-50) (400+50, 300+50)
- 104. import cv2 cap = cv2.VideoCapture(1) while(True): ret, frame = cap.read() #ここにコードを書く h, w, _ = frame.shape[:3] # 画像の形(高さ,幅,チャンネル数)を取得 h_center = h//2 # y軸の中心点を取得 w_center = w//2 # x軸の中心点を取得 cv2.rectangle(frame, (w_center-71, h_center-71), (w_center+71, h_center+71), (255, 0, 0)) cv2.imshow(“frame”, frame) k = cv2.waitKey(1) & 0xFF #後略 中心点を求めて142×142サイズの四角を描く ※最終的に、140×140のサイズできれいに切り抜きたいので、四角は一回り大きくしておく wとhの順番に注意
- 106. 各種画像処理を加えていく #前略 ret, frame = cap.read() h, w, _ = frame.shape[:3] # 画像の形(高さ,幅,チャンネル数)を取得 h_center = h//2 # y軸の中心点を取得 w_center = w//2 # x軸の中心点を取得 cv2.rectangle(frame, (w_center-71, h_center-71), (w_center+71, h_center+71), (255, 0, 0)) #ここにコードを書く im = frame[h_center-70:h_center+70, w_center-70:w_center+70] # トリミング im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) # グレースケール化 _, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU) # 二値化 th = cv2.bitwise_not(th) # 白黒反転 th = cv2.GaussianBlur(th,(9,9),0) # ブラーをかける th = cv2.resize(th,(28,28), cv2.INTER_CUBIC) # 28×28にリサイズ cv2.imshow(“frame”, frame) cv2.imshow(“im”, im )# 途中経過を見るために追記 k = cv2.waitKey(1) & 0xFF #後略 th
- 107. コードを保存!
- 108. ディープラーニングさせたモデルを読み込む • モデルデータを読み込む処理を加える • 学習させた「mnist.h5」をソースと同じディレクトリに保存 import cv2 #ここに処理を加える from keras.models import load_model import numpy as np model = load_model(“mnist.h5") cap = cv2.VideoCapture(1) while(True): ret, frame = cap.read() #後略
- 109. 学習させたデータと比較できるように、カメラの映像データを加工する import cv2 from keras.models import load_model import numpy as np model = load_model(“mnist.h5") cap = cv2.VideoCapture(1) while(True): # 判定用データを格納する配列の初期化 Xt = [] Yt = [] ret, frame = cap.read() #後略
- 110. 判定できるように形を変換する・判定する #前略 im = frame[h_center-70:h_center+70, w_center-70:w_center+70] im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) _, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU) th = cv2.bitwise_not(th) th = cv2.GaussianBlur(th,(9,9),0) th = cv2.resize(th,(28,28), cv2.INTER_CUBIC) Xt.append(th) Xt = np.array(Xt)/255 Xt = np.expand_dims(Xt, axis=-1) result = model.predict(Xt, batch_size=1) # Xtと学習したデータを比較して判定結果を返す cv2.imshow(“frame”, frame) #後略
- 111. predictがどういう値を返すか 配布データの中の、predict_test.ipynb ※手元で実行する必要はありません。 MNISTの場合、左上から[0の可能性 1の可能性 2の可能性 …]という風に並んでいる 1番近い可能性だけ返してほしい
- 112. resultの中には、順番に0~9に一致する確率がセットされている 該当する数字(0~9)までと、その確率をセットにして、確率が高いものが右端に並 ぶようにソートする [ [ 3, 0.1 ] [ 0 , 0.2 ] [2, 0.6] [ 1, 0.7 ] ] [ [ 0 , 0.2 ] [ 1, 0.7 ] [2, 0.6] [ 3, 0.1 ] ] 例) 確率順で並べ替えておけば、表示するときに呼び出しやすくなる!
- 113. 表示用データの作成・判定結果のソート #前略 Xt.append(th) Xt = np.array(Xt)/255 result = model.predict(Xt, batch_size=1) for i in range(10): r = round(result[0,i],2) # 小数点以下第2位までで四捨五入 r = “{0:0.2f}”.format(r) # OpenCVで表示できる型に変換 Yt.append([i, r]) # その数字が何かと一致する確率をセットで格納 Yt = sorted(Yt, key=lambda x:(x[1]))# ソート実行 cv2.imshow(“frame”, frame) #後略 一番一致してる確率が高いものがYt[9]に[数字,一致する確率]という形で収納される for内のインデントは下げる!
- 114. 判定結果の上位1番目を画面上に表示 #前略 for i in range(10): r = round(result[0,i],2) r = "{0:.2f}".format(r) Yt.append([i, r]) Yt = sorted(Yt, key=lambda x:(x[1])) cv2.putText(frame, "1st:"+str(Yt[9]), (10,40), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255,255,255), 1, cv2.LINE_AA) cv2.imshow(“frame”, frame) #後略
- 115. 遊んでみよう
- 116. 判定結果の上位3番目までを画面上に表示 #前略 for i in range(10): r = round(result[0,i],2) r = "{0:.2f}".format(r) Yt.append([i, r]) Yt = sorted(Yt, key=lambda x:(x[1])) cv2.putText(frame, "1st:"+str(Yt[9]), (10,40), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255,255,255), 1, cv2.LINE_AA) cv2.putText(frame, "2nd:"+str(Yt[8]), (220,40), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255), 1, cv2.LINE_AA) cv2.putText(frame, "3rd:"+str(Yt[7]), (360,40), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,255), 1, cv2.LINE_AA) cv2.imshow(“frame”, frame) #後略