

















































Ad
More Related Content
Similar to ETL Pipeline for the snowflake problem statement (20)
Recently uploaded (20)


















Ad
ETL Pipeline for the snowflake problem statement
- 1. Introduction Training Healthcare Analysis Project Telecom Customer Revenue Analysis Conclusio n 1 2 3 4 5 Overview
- 2. Introduction Data engineering involves designing and maintaining systems for handling and analyzing large volumes of data from diverse sources, crucial for enabling data-driven decision-making across industries. Sigmoid excels in Data Engineering and Data Science services, delivering innovative solutions tailored to diverse industries. Leading in ML and AI, we specialize in providing top- tier data solutions.
- 3. source : medium block by narendrababuoggu
- 4. Training • Python • Sq l • Data Extraction • AWS • Snowflake • Scal a • Data Pipeline • Mongodb • Spar k Programming Languages Database Data Engineering Tools
- 5. Data Processing OLTP (Online Transaction Processing): • Tailored for handling a high volume of small, straightforward transactions in real-time. • Commonly employed in transactional systems like e-commerce platforms, banking applications, and inventory management systems. • Geared towards supporting real-time, interactive operations necessitating high concurrency, minimal latency, and data consistency. • Utilizes normalized data schema, efficient indexing techniques, and adheres to ACID principles. OLAP (Online Analytical Processing): • Specialized in managing extensive and intricate datasets. • Primarily utilized in analytical systems such as business intelligence platforms, data mining tools, and decision support systems. • Geared towards facilitating ad-hoc querying, data analysis, and generating reports. • Operates with lower concurrency requirements but higher throughput, focusing on data aggregation and complex analytics. • Typically relies on data warehousing solutions, ETL processes, and dedicated OLAP servers for data processing and analysis.
- 6. Monitoring, Reporting and Analytics Data Lake: • Serves as a comprehensive storage solution for raw, unprocessed data from diverse sources, maintaining its original format. • Acts as a centralized hub for scalable data ingestion, storage, and processing. • Facilitates schema flexibility and exploratory data analysis, enabling dynamic insights and late-binding analytics. • Tailored for big data processing and real-time ingestion, commonly leveraging Hadoop-based technologies. Data Warehouse: • Functions as a centralized repository for structured and processed data, harmonized into a unified schema for efficient querying and analysis. • Employs ETL processes to transform and load data into a standardized schema, enabling complex SQL queries and OLAP operations. • Designed for historical data analysis and strategic decision-making. • Typically utilizes traditional RDBMS solutions like Oracle, SQL Server, or PostgreSQL for data warehousing needs.
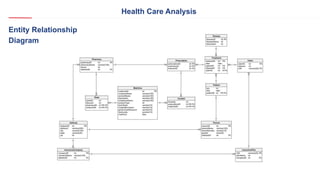
- 7. Health Care Analysis Entity Relationship Diagram
- 8. Solution Architecture Sources ETL tools Storage/Analysis Visualization
- 11. A report that shows for each state how many people underwent treatment for the disease “Autism”.
- 13. For each age(in years), how many patients have gone for treatment?
- 14. For each age(in years), how many patients have gone for treatment?
- 15. Telecom Customer Revenue Analysis Project • This project focuses on analyzing customer behavior and revenue generation for a telecom company. • It involves gathering and processing data from multiple sources, including call records, billing data, demographics, and other relevant information, which has already been provided. • The primary goal is to uncover patterns and trends in consumer behavior and usage, aiming to enhance profitability and enhance customer satisfaction.
- 17. Phase 1 : Analyzing Data Quality Data Cleaning Upload data to MongoDB • Use Pandas DataFram to identify columns with missing values, null values • Fill missing values with appropriate strategies like mean, median, mode, forward/backward filling. • Perform any additional data cleaning tasks such as converting data types or removing duplicates as needed. • Using pymongo, establish a connnection with mongoDB • Iterate through the JSON data and insert each row into the appropriate MongoDB collection. Extraction, Transform, Load
- 18. Phase 2 : Create a Producer System • A Kafka producer application is developed using Python to interact with the Kafka cluster • We use the argparse module to parse command-line arguments to specify the interval between producing messages (in seconds).
- 19. Phase 3 : Setup Data Warehouse and Load cleansed data Define Database and Schema Define Tables Load Data • Create a database and schema to organize your data • Create tables within the schema to represent your cleansed data. • Define appropriate column names, data types, and constraints based on data requirements • Use Snowsql to load data into Snowflake. • Use COPY INTO method.
- 20. Phase 4 : Enrich Data • Using Apache Spark, the data stream from, Kafka is consumed. • Joins are performed with the datasets based on the unique identification numbers. Kafka Snowflake Spark Snowflake
- 21. Phase 5 : Data Analysis • Using Snowflake to derive actionable insights and uncover meaningful patterns from the enriched dataset. • By aggregating and summarizing the data at different granularities, such as overall and week- wise, comprehensive insights into customer behavior and revenue generation trends are obtained. • Snowflake’s ability to handle complex queries and process large volumes of data efficiently enabled to make informed decisions regarding revenue optimization, customer retention strategies, and service enhancements.
- 22. Phase 6 : Workflow Orchestration • Using Airflow’s Directed Acyclic Graphs (DAGs), a series of tasks are defined to encompass the entire data pipeline, from data ingestion to analysis and visualization. • By defining dependencies between tasks, Airflow ensures that each step wis executed in the correct order and that subsequent tasks are only triggered upon successful completion of prerequisite tasks. • Snowflake’s ability to handle complex queries and process large volumes of data efficiently enabled to make informed decisions regarding revenue optimization, customer retention strategies, and service enhancements.