Evolution of MongoDB Replicaset and Its Best Practices
0 likes736 views

There are several exciting and long-awaited features released from MongoDB 4.0. He will focus on the prime features, the kind of problem it solves, and the best practices for deploying replica sets.















![Replica Set Best Practices
db.collection.find().readPref('nearest', [ { 'dc': 'east' } ])
▪ Use hostnames when configuring replica set members rather than IP-addresses
▪ Ensure that the replica set has an odd number of voting members
▪ Oplog Recovery Window need to maintain minimum 24 hours
▪ 3 type of connection URI
▪ Consistency Read: primary
▪ Eventually Consistent: SecondaryPreferred, maxStalnessSeconds
▪ write Concern w: 1
▪ Nearest read preference , tag set and maxStalnessSeconds read setting need use in Geographically
Distributed Members](https://image.slidesharecdn.com/evolution-of-mongodb-replicaset-210829171645/85/Evolution-of-MongoDB-Replicaset-and-Its-Best-Practices-16-320.jpg)












![Mirrored Reads - From MongoDB 4.4
• The Primary node will copy the read traffic to the one secondary node at a certain ratio
• This helps to warm up the secondary node cache that is very similar to the Primary server cache
• When primary server node went down, the mirrored Secondary node take responsibility and
serve the traffic
• This feature helps reduce the "Cache Miss" and disk load. And it keeps the same query
performance all along as the previous primary.
• The mirrored reads are "fire-and-forget" operations by the primary; i.e., the primary does not
await the response for the mirrored reads.
• Electable <members[n].priority> secondary replica set member receive mirrored read
• A sampling rate of "0.0" disables mirrored reads.
• A sampling rate of a number between "0.0" and "1.0"
• sampling rate of "1.0" results in the primary forwarding all](https://image.slidesharecdn.com/evolution-of-mongodb-replicaset-210829171645/85/Evolution-of-MongoDB-Replicaset-and-Its-Best-Practices-30-320.jpg)


![Simultaneous Indexing - From MongoDB 4.4
Index Creation Command:
db.getSiblingDB("examples").invoices.createIndexes(
[
{ "invoices" : 1 },
{ "fulfillmentStatus" : 1 }
]
)
Setting Index Commit Quorum:
db.getSiblingDB("examples").runCommand(
{
"setIndexCommitQuorum" : "invoices",
"indexNames" : ["invoices_1", "fullfillmentStatus_1"],
"commitQuorum" : "majority"
}
)
• By default, index builds use "votingMembers" commit quorum, or all data-bearing voting replica set
members
• Do not use killOp to terminate an in-progress index builds in replica sets or sharded clusters
• Starting from 4.2 db.pets.dropIndex( "catIdx" ) to drop Index
• Run dropIndexes on the primary, it creates an associated "abortIndexBuild" oplog entry](https://image.slidesharecdn.com/evolution-of-mongodb-replicaset-210829171645/85/Evolution-of-MongoDB-Replicaset-and-Its-Best-Practices-33-320.jpg)














![[OpenStack Days Korea 2016] Track1 - 카카오는 오픈스택 기반으로 어떻게 5000VM을 운영하고 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/16kakao-160226171853-thumbnail.jpg?width=560&fit=bounds)








![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=560&fit=bounds)








Ad
More Related Content
What's hot (20)
Similar to Evolution of MongoDB Replicaset and Its Best Practices (20)


















Ad
More from Mydbops (20)




















Ad
Recently uploaded (20)




















Evolution of MongoDB Replicaset and Its Best Practices
- 1. Evolution of MongoDB Replica Set and Its Best Practices Manosh Malai CTO, Mydbops 28Th August 2021 Mydbops 8th Webinar
- 2. Interested in Open Source technologies Interested in MongoDB, DevOps & DevOpSec Practices Tech Speaker/Blogger CTO, Mydbops IT Solution Manosh Malai About Me
- 3. Consulting Services Managed Services Focuses on MySQL, MongoDB and PostgreSQL Mydbops Services
- 4. 500 + Clients In 5 Yrs. of Operations Our Clients
- 5. MongoDB Evolution and Its Exciting Features 4.0 to 5.0 MongoDB Replica Set Implementation Best Practices Introduction Agenda
- 6. INTRODUCTION
- 7. Scaling MongoDB MongoDB is designed to effectienly handle large dataset through vertical and horizontal scaling Additional node to share the load, MongoDB achieved primarily through Sharding Vertical scaling refers to the use of CPU, RAM, and I/O to increase the processing capability of a single server or cluster(Replica Set). Is MongoDB fit for large data Horizontal Scaling Vertical Scaling
- 8. Vertical and Horizontal Scaling Vertical Scaling Horizontal Scaling
- 9. MONGODB REPLICATION AND IT'S BEST PRACTICES
- 11. Automatic Failover PRIMARY SECONDARY SECONDARY Heartbeat SECONDARY Heartbeat PRIMARY REPL electionTimeoutMillis 10 Sec(Default) + 2 sec to select New Primary = 12 Sec Median to elect New Primary
- 12. Odd Number Of Replica Member 50 Members Max 7 Members Only can Vote Members count always Odd
- 13. Cont... Number of Voting Member Majority Numberof Tolerable Failure 1 1 0 2 2 0 3 2 1 4 3 1 5 3 2 6 4 2 7 4 3 Even Node: (N/2)+1 = Majority Node Odd Node: (N+1)/2 = Majority Node 6/2+1 = 4 7+1/2 = 4 Number Of Members Alive Majority = Cannot Elect Primary And Write Fail
- 14. READ And WRITE Replica Settings Read Preference • Primary • Primary Preferred • Secondary • Secondary Preferred • Nearest Write Preference • w: majority • w: <N> • j: true
- 15. Secondary Member Type Type Read Accept Vote Become Primary Priority 0 Yes Yes No Hidden No Yes No Delay No Yes No Arbiter No Yes No
- 16. Replica Set Best Practices db.collection.find().readPref('nearest', [ { 'dc': 'east' } ]) ▪ Use hostnames when configuring replica set members rather than IP-addresses ▪ Ensure that the replica set has an odd number of voting members ▪ Oplog Recovery Window need to maintain minimum 24 hours ▪ 3 type of connection URI ▪ Consistency Read: primary ▪ Eventually Consistent: SecondaryPreferred, maxStalnessSeconds ▪ write Concern w: 1 ▪ Nearest read preference , tag set and maxStalnessSeconds read setting need use in Geographically Distributed Members
- 17. Replica Set Best Practices - 2 ▪ Use x.509 Certificate for Membership Authentication security: clusterAuthMode: x509 net: tls: mode: requireTLS certificateKeyFile: <path to its TLS/SSL certificate and key file> CAFile: <path to root CA PEM file to verify received certificate> clusterFile: <path to its certificate key file for membership authentication> bindIp: localhost,<hostname(s)|ip address(es)>
- 18. Replica Set Best Practices - 3 • Enable Authorization • Create different role for Database Administration, Operation and Admin OPS User DBA User Super User List Database (show dbs) List Database (show dbs) ALL ACCESS(root) List collections (show collections) except admin,local,config database. List collections (show collections) except admin,local,config database. Read collection data (db.coll.find()) Read collection data (db.coll.find()) Able to check collection stats (db.coll.stats()) Able to check collection stats (db.coll.stats()) Able to check db stats (db.stats()) Able to check db stats (db.stats()) Able to create Index Able to create Index Able to see the current running queries (db.currentOp()) Able to see the current running queries (db.currentOp()) Able to kill the queries Able to kill the queries Able to see the replication status Able to see the replication status Able to see the list of users Able to see the list of users Able to see the inherited privileges of each role Able to see the inherited privileges of each role Able to rotate the log file Able to rotate the log file Able to drop Index Able to shutdown mongo Able to Lock writes Able to configure the replica set Able to change the replica set IP Able to run compaction against collection
- 19. Replica Set Best Practices - 4 ▪ Mongod services should run in a non-privileged account with nologin/false shell. ▪ DO NOT Allow MongoDB to talk to the internet at all costs ▪ Configure security groups to block outbound connections to internet(Network Level) ▪ Configure IPTABLES/UFW to block/control outbound traffic(Instance Level) ▪ use the XFS filesystem ▪ Turn off atime for the storage volume with the database files ▪ <MongoDB Data Partition> xfs rw,noatime,attr2,inode64,noquota 0 0 ▪ Do not use huge pages virtual memory pages, MongoDB performs better with normal virtual memory pages. ▪ $ echo "never" > /sys/kernel/mm/transparent_hugepage/enabled ▪ $ echo "never" > /sys/kernel/mm/transparent_hugepage/defrag
- 20. Replica Set Best Practices - 5 ▪ Disable NUMA in your BIOS or invoke mongod with NUMA disabled. ▪ Edit /etc/systemd/system/multi-user.target.wants/mongod.service ▪ ExecStart=/usr/bin/numactl --interleave=all /usr/bin/mongod --config /etc/mongod.conf ▪ Ensure that readahead settings for the block devices that store the database files are relatively small as most access is non-sequential. For example, setting readahead to 32 (16KB) is a good starting point. ▪ ulimit to apply these settings: -f(filesize):unlimited -t(cputime):unlimited -v(virtualmemory):unlimited • -n(openfiles):64000 -m(memorysize):unlimited -u(processes/threads):32000
- 21. Replica Set Best Practices - 6 net.core.somaxconn = 4096 net.ipv4.tcp_fin_timeout = 30 net.ipv4.tcp_keepalive_intvl = 30 net.ipv4.tcp_keepalive_time = 120 net.ipv4.tcp_max_syn_backlog = 4096 net.ipv4.tcp_keepalive_probes = 6 • Network Stack Tuning • Dirty Ratio vm.dirty_ratio = 15 vm.dirty_background_ratio = 5
- 22. MONGODB EVOLUTION AND ITS RECENT EXCITING FEATURES
- 23. Evolution of MongoDB Replica Set
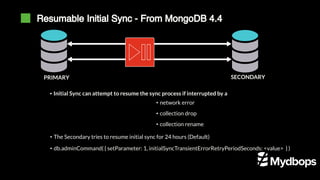
- 24. Resumable Initial Sync - From MongoDB 4.4 PRIMARY SECONDARY ▪ Initial Sync can attempt to resume the sync process if interrupted by a • network error • collection drop • collection rename • The Secondary tries to resume initial sync for 24 hours (Default) • db.adminCommand( { setParameter: 1, initialSyncTransientErrorRetryPeriodSeconds: <value> } )
- 25. Resumable Initial Sync Monitoring - From MongoDB 4.4
- 26. Streaming Replication - From MongoDB 4.4
- 27. Streaming Replication - From MongoDB 4.4 Before 4.4: • Single OplogFetcher thread actively send getMore command to the Primary Oplog Collection • If there is data, a batch of upto 16MB is returned • Each batch acquisition needs to go through a complete network RTT • In the case of a bad replica set network, the performance of replica is severely limited by network latency From 4.4: • Incremental Oplog is constantly flowing into the secondary node, instead of relying on the active poll by the Secondary node • Compared with the previous method, at least half of the RTT is saved in the Oplog sync process. • The majority write performance increases by 50% on average db.adminCommand( { setParameter: 1, initialSyncTransientErrorRetryPeriodSeconds: <value> } ) True/False
- 28. Minimum Oplog Retention Period - From MongoDB 4.4 • { replSetResizeOplog: <boolean>, size: <num MB> } • db.adminCommand({replSetResizeOplog:1, size: 16384}) • db.getSiblingDB("local").oplog.rs.stats(1024*1024).maxSize 3.6 • db.adminCommand({replSetResizeOplog: <int>, size: <double>, minRetentionHours: <double>}) • db.adminCommand({replSetResizeOplog: 1, size: 20000, minRetentionHours: 1.5}) • db.getSiblingDB("local").oplog.rs.stats(1024*1024).maxSize • db.getSiblingDB("admin").serverStatus().oplogTruncation.minRetentionHours 4.4
- 29. Minimum Oplog Retention Period - From MongoDB 4.4 • In a longer retention time configured scenario, Because of a combination of high write volume, The oplog may grow beyond its maximum size to keep the Oplog entires. • From MongoDB 4.0 onward, MongoDB forbids you from dropping the local.oplog.rs collection • We can specify a size of 990 megabytes to 1 petabyte. • Reducing the oplog size does not automatically reclaim disk space. Compact must be performed on the local database's oplog.rs collection.
- 30. Mirrored Reads - From MongoDB 4.4 • The Primary node will copy the read traffic to the one secondary node at a certain ratio • This helps to warm up the secondary node cache that is very similar to the Primary server cache • When primary server node went down, the mirrored Secondary node take responsibility and serve the traffic • This feature helps reduce the "Cache Miss" and disk load. And it keeps the same query performance all along as the previous primary. • The mirrored reads are "fire-and-forget" operations by the primary; i.e., the primary does not await the response for the mirrored reads. • Electable <members[n].priority> secondary replica set member receive mirrored read • A sampling rate of "0.0" disables mirrored reads. • A sampling rate of a number between "0.0" and "1.0" • sampling rate of "1.0" results in the primary forwarding all
- 31. Mirrored Reads - From MongoDB 4.4 • db.adminCommand( { setParameter: 1, mirrorReads: { samplingRate: 0.10 } } ) • db.runCommand( { serverStatus: 1, mirroredReads: 1 } ) • Mirrored reads support the following operations: • Count • Distinct • Find • findAndModify (Specifically, the filter is sent as a mirrored read) • update (Specifically, the filter is sent as a mirrored read)
- 32. Simultaneous Indexing - From MongoDB 4.4 • Before version 4.4, the index creation must be copied to the Secondary node to run once the primary node is complete • From 4.4, Indexes Build Simultaneously on Data-Bearing Replica Set Members • Index build process "startIndexBuild" oplog entry commitIndexBuild abortIndexBuild Primary check for Quorum Vote and any key constraint violations CreateIndex Command Each Member Vote commit for its finished index Secondary "startIndexBuild"
- 33. Simultaneous Indexing - From MongoDB 4.4 Index Creation Command: db.getSiblingDB("examples").invoices.createIndexes( [ { "invoices" : 1 }, { "fulfillmentStatus" : 1 } ] ) Setting Index Commit Quorum: db.getSiblingDB("examples").runCommand( { "setIndexCommitQuorum" : "invoices", "indexNames" : ["invoices_1", "fullfillmentStatus_1"], "commitQuorum" : "majority" } ) • By default, index builds use "votingMembers" commit quorum, or all data-bearing voting replica set members • Do not use killOp to terminate an in-progress index builds in replica sets or sharded clusters • Starting from 4.2 db.pets.dropIndex( "catIdx" ) to drop Index • Run dropIndexes on the primary, it creates an associated "abortIndexBuild" oplog entry
- 34. Reach Us : [email protected] Thank You