












































































Ad
More Related Content
What's hot (20)
Similar to Как читать и интерпретировать вывод команды EXPLAIN (20)


















Ad
Как читать и интерпретировать вывод команды EXPLAIN
- 1. Как читать и интерпретировать вывод команды EXPLAIN ? Алексей Ермаков [email protected]
- 2. 2 Как ускорить запрос? • “Очень долгий, очень пристальный и очень задумчивый взгляд” на запрос dataegret.com
- 3. 2 Как ускорить запрос? • “Очень долгий, очень пристальный и очень задумчивый взгляд” на запрос • EXPLAIN – основной инструмент анализа запросов dataegret.com
- 4. 3 Как ускорить запрос? • EXPLAIN без параметров показывает план запроса, но не выполняет1 запрос и не показывает статистику выполнения запроса 1 на самом деле может выполнить immutable/stable хранимки, но ведь они у вас ничего не меняют, правда? dataegret.com
- 5. 4 План запроса #1 explain select * from posts join categories on posts.category_id = categories.id where posts.rating < 15; -------------------------------------------------------------------------------------------- Nested Loop (cost=0.43..16.47 rows=1 width=32) -> Index Scan using posts_rating_idx on posts (cost=0.29..8.30 rows=1 width=28) Index Cond: (rating < 15) -> Index Only Scan using categories_pkey on categories (cost=0.14..8.16 rows=1 width=4) Index Cond: (id = posts.category_id) dataegret.com
- 6. 5 План запроса #2 explain select * from posts join categories on posts.category_id = categories.id where posts.rating < 35; Hash Join (cost=27.84..117.61 rows=601 width=32) Hash Cond: (posts.category_id = categories.id) -> Bitmap Heap Scan on posts (cost=12.94..94.46 rows=601 width=28) Recheck Cond: (rating < 35) -> Bitmap Index Scan on posts_rating_idx (cost=0.00..12.79 rows=601 width=0) Index Cond: (rating < 35) -> Hash (cost=13.64..13.64 rows=100 width=4) -> Index Only Scan using categories_pkey on categories (cost=0.14..13.64 rows=100 width=4) dataegret.com
- 7. 6 План запроса #2 explain select * from posts join categories on posts.category_id = categories.id where posts.rating < 35; Hash Join (cost=27.84..117.61 rows=601 width=32) Hash Cond: (posts.category_id = categories.id) -> Bitmap Heap Scan on posts (cost=12.94..94.46 rows=601 width=28) Recheck Cond: (rating < 35) -> Bitmap Index Scan on posts_rating_idx (cost=0.00..12.79 rows=601 width=0) Index Cond: (rating < 35) -> Hash (cost=13.64..13.64 rows=100 width=4) -> Index Only Scan using categories_pkey on categories (cost=0.14..13.64 rows=100 width=4) dataegret.com
- 8. 7 План запроса • Это дерево • Вышестоящие узлы запрашивают данные у нижестоящих • План запроса не меняется по мере выполнения, даже если оказалось что ожидания расходятся с реальностью на 6 порядков • База не хранит историю неудачных или медленных планов запросов. Так что, если если запрос получает неверный план - он будет получать его воспроизводимо2 2 если не меняются настройки базы, распределение данных, размеры таблиц и индексов, не используется geqo dataegret.com
- 9. 8 Мы любим ORM select website0_.websiteId as websiteI1_304_0_, website0_.websiteTitleType as websiteT2_304_0_, website0_.websiteUrl as websiteU3_304_0_, website0_.websiteLocalArticlePath as websiteL4_304_0_, ... (еще 14кб текста) from Website website0_ where website0_.websiteId=$1 dataegret.com
- 10. 8 Мы любим ORM select website0_.websiteId as websiteI1_304_0_, website0_.websiteTitleType as websiteT2_304_0_, website0_.websiteUrl as websiteU3_304_0_, website0_.websiteLocalArticlePath as websiteL4_304_0_, ... (еще 14кб текста) from Website website0_ where website0_.websiteId=$1 • Иногда план запроса читать проще, нежели сам запрос dataegret.com
- 11. 9 Виды элементарных операций Методы извлечения данных • seq scan – последовательное чтение таблицы • index scan – random io (чтение индекса + чтение таблицы) • index only scan – random io (чтение только3 индекса) • bitmap index scan + bitmap heap scan – компромисс между seq scan/index scan, возможность использования нескольких индексов в OR/AND условиях • CTE scan – чтение из CTE (блок WITH) • function scan – чтение строк из функции 3 Возможно и чтение таблицы, зависит от состояния visibility map dataegret.com
- 12. 10 Виды элементарных операций Методы соединения данных • nested loop – оптимален для небольших наборов данных • hash join – оптимален для больших наборов данных • merge join – оптимален для больших наборов данных, в случае, если они отсортированы dataegret.com
- 13. 11 Nested loop for each outer row: for each inner row: if join condition is true: output combined row dataegret.com
- 14. 12 Виды элементарных операций Методы обработки данных • sort – сортирует данные в памяти или на диске, есть более быстрый topN вариант • limit – ограничивает выборку • aggregate – используется в агрегирующих функциях • hash aggregate – используется в группировках • unique – отбрасывает дубликаты из отсортированных выборок • gather – используется для объединения данных с различных воркеров при одновременном выполнении dataegret.com
- 15. 13 Характеристики каждой операции explain select * from pg_database; QUERY PLAN ----------------------------------------------------------- Seq Scan on pg_database (cost=0.00..0.16 rows=6 width=271) (1 row) Seq Scan тип операции on pg_database объект, с которым проводится операция cost=0.00..0.16 стоимость операции (startup..total cost) rows=6 ожидаемое число строк width=271 средняя ширина строки в байтах dataegret.com
- 16. 14 startup..total cost explain select * from posts order by id limit 5; QUERY PLAN -------------------------------------------------------------------------------------- Limit (cost=0.29..0.46 rows=5 width=28) -> Index Scan using posts_pkey on posts (cost=0.29..347.29 rows=10000 width=28) (2 rows) dataegret.com
- 17. 14 startup..total cost explain select * from posts order by id limit 5; QUERY PLAN -------------------------------------------------------------------------------------- Limit (cost=0.29..0.46 rows=5 width=28) -> Index Scan using posts_pkey on posts (cost=0.29..347.29 rows=10000 width=28) (2 rows) • 0.29 + (347.29 - 0.29)*5/10000 = 0.4635 dataegret.com
- 18. 15 rows*width • rows*width у корневого узла дает примерный порядок объема результата в байтах • если запрос часто вызывается и при этом запрашивает большое число данных – то легко можно забить сеть между базой и приложением • передача данных по сети может занимать большее время, чем время выполнения запроса • не всегда стоит запрашивать все поля, что есть, особенно если они широкие и никак не используются dataegret.com
- 19. 16 Опции команды EXPLAIN EXPLAIN (ANALYZE,VERBOSE,COSTS,BUFFERS,TIMING4) select * from t1; QUERY PLAN ------------------------------------------------------------------- Seq Scan on public.t1 (cost=0.00..104424.80 rows=10000000 width=8) (actual time=0.218..2316.688 rows=10000000 loops=1) Output: f1, f2 Buffers: shared read=44248 I/O Timings: read=322.7145 Planning time: 0.024 ms Execution time: 3852.588 ms 4 COSTS и TIMING опции включены по-умолчанию 5 I/O Timings отображается, когда track_io_timing включен dataegret.com
- 20. 17 План запроса #3 Gather (cost=100.57..1338637.12 rows=2346550 width=1526) (actual time=4489.134..4855.942 rows=79061 loops=1) Workers Planned: 4 Workers Launched: 4 -> Nested Loop (cost=0.57..1103882.12 rows=2346550 width=1526) (actual time=4482.217..4810.097 rows=15812 loops=5) -> Parallel Seq Scan on deferred_report r (cost=0.00..97294.45 rows=1345386 width=8) (actual time=0.026..702.618 rows=1098890 loops=5) Filter: (("timestamp" < ’2017-02-26 21:00:00’::timestamp without time zone) AND (proxy_id = 37) AND Rows Removed by Filter: 2709566 -> Index Scan using transactions_pkey on transactions t (cost=0.57..0.74 rows=1 width=1526) (actual time=0.004..0.004 rows=0 loops=5494451) Index Cond: (id = r.tx_id) Filter: (status = ’ok’::status) Rows Removed by Filter: 1 Planning time: 0.736 ms Execution time: 4861.460 ms dataegret.com
- 21. 18 Filter -> Parallel Seq Scan on deferred_report r (cost=0.00..97294.45 rows=1345386 width=8) (actual time=0.026..702.618 rows=1098890 loops=5) Filter: (("timestamp" < ’2017-02-26 21:00:00’::timestamp without time zone) AND (proxy_id = 37 Rows Removed by Filter: 2709566 • Оправдано ли использование seq scan в данном случае? dataegret.com
- 22. 18 Filter -> Parallel Seq Scan on deferred_report r (cost=0.00..97294.45 rows=1345386 width=8) (actual time=0.026..702.618 rows=1098890 loops=5) Filter: (("timestamp" < ’2017-02-26 21:00:00’::timestamp without time zone) AND (proxy_id = 37 Rows Removed by Filter: 2709566 • Оправдано ли использование seq scan в данном случае? • worker извлек 1098890 1098890+2709566 ≈ 28% строк dataegret.com
- 23. 18 Filter -> Parallel Seq Scan on deferred_report r (cost=0.00..97294.45 rows=1345386 width=8) (actual time=0.026..702.618 rows=1098890 loops=5) Filter: (("timestamp" < ’2017-02-26 21:00:00’::timestamp without time zone) AND (proxy_id = 37 Rows Removed by Filter: 2709566 • Оправдано ли использование seq scan в данном случае? • worker извлек 1098890 1098890+2709566 ≈ 28% строк • вероятно да, bitmap index scan может и был бы быстрее, но в 9.6 его еще нельзя распараллелить по воркерам dataegret.com
- 24. 19 Filter -> Index Scan using transactions_pkey on transactions t (cost=0.57..0.74 rows=1 width=1526) (actual time=0.004..0.004 rows=0 loops=5494451) Index Cond: (id = r.tx_id) Filter: (status = ’ok’::status) Rows Removed by Filter: 1 • Используется ли оптимальный индекс в данном случае? dataegret.com
- 25. 19 Filter -> Index Scan using transactions_pkey on transactions t (cost=0.57..0.74 rows=1 width=1526) (actual time=0.004..0.004 rows=0 loops=5494451) Index Cond: (id = r.tx_id) Filter: (status = ’ok’::status) Rows Removed by Filter: 1 • Используется ли оптимальный индекс в данном случае? • Большинство строк отбрасываются по условию status = ‘ok’::status dataegret.com
- 26. 19 Filter -> Index Scan using transactions_pkey on transactions t (cost=0.57..0.74 rows=1 width=1526) (actual time=0.004..0.004 rows=0 loops=5494451) Index Cond: (id = r.tx_id) Filter: (status = ’ok’::status) Rows Removed by Filter: 1 • Используется ли оптимальный индекс в данном случае? • Большинство строк отбрасываются по условию status = ‘ok’::status • Вероятно нет, может быть тут более уместен индекс по (id, status) или частичный индекс по id where status = ‘ok’ dataegret.com
- 27. 20 Инструменты, позволяющие визуализировать план запроса • https://explain.depesz.com/ • http://tatiyants.com/pev/ dataegret.com
- 29. 22 Filter WHERE dispatch_time + INTERVAL ’1 hour’ > now() WHERE (DATE(o.created) >= ’2017-03-23’ AND DATE(o.created) <= ’2017-04-21’) • конструкции такого вида не могут использовать обычный индекс по соответствующему полю • необходимо привести их к виду индексируемое_поле индексируемый_оператор выражение dataegret.com
- 30. 23 Опция buffers -> Index Only Scan using user_balance_id_type on user_balance ub (cost=0.00..0.56 rows=1 width=8) (actual time=0.031..1.453 rows=1 loops=29721) Index Cond: ((id = o.user_balance_id) AND (type = 1)) Heap Fetches: 7192482 Buffers: shared hit=7608576 • Что-то пошло не так... dataegret.com
- 31. 23 Опция buffers -> Index Only Scan using user_balance_id_type on user_balance ub (cost=0.00..0.56 rows=1 width=8) (actual time=0.031..1.453 rows=1 loops=29721) Index Cond: ((id = o.user_balance_id) AND (type = 1)) Heap Fetches: 7192482 Buffers: shared hit=7608576 • Что-то пошло не так... • Читаем 7608576 29721 = 256 страниц, чтобы извлечь одну строку dataegret.com
- 32. 23 Опция buffers -> Index Only Scan using user_balance_id_type on user_balance ub (cost=0.00..0.56 rows=1 width=8) (actual time=0.031..1.453 rows=1 loops=29721) Index Cond: ((id = o.user_balance_id) AND (type = 1)) Heap Fetches: 7192482 Buffers: shared hit=7608576 • Что-то пошло не так... • Читаем 7608576 29721 = 256 страниц, чтобы извлечь одну строку • Вероятно, очень большой bloat в таблице/индексе dataegret.com
- 33. 23 Опция buffers -> Index Only Scan using user_balance_id_type on user_balance ub (cost=0.00..0.56 rows=1 width=8) (actual time=0.031..1.453 rows=1 loops=29721) Index Cond: ((id = o.user_balance_id) AND (type = 1)) Heap Fetches: 7192482 Buffers: shared hit=7608576 • Что-то пошло не так... • Читаем 7608576 29721 = 256 страниц, чтобы извлечь одну строку • Вероятно, очень большой bloat в таблице/индексе • Длинные транзакции? Не справляется автовакуум? dataegret.com
- 34. 23 Опция buffers -> Index Only Scan using user_balance_id_type on user_balance ub (cost=0.00..0.56 rows=1 width=8) (actual time=0.031..1.453 rows=1 loops=29721) Index Cond: ((id = o.user_balance_id) AND (type = 1)) Heap Fetches: 7192482 Buffers: shared hit=7608576 • Что-то пошло не так... • Читаем 7608576 29721 = 256 страниц, чтобы извлечь одну строку • Вероятно, очень большой bloat в таблице/индексе • Длинные транзакции? Не справляется автовакуум? • Отстающая реплика с hot_standby_feedback = on ! dataegret.com
- 35. 24 I/O timings -> Bitmap Heap Scan on delivery fi (cost=872967.27..4196621.37 rows=32425255 width=36) (actual time=30842.138..37818.082 rows=6674571 loops=1) Recheck Cond: ((datetime_start >= ’2017-05-11 00:00:00’::timestamp without time zone) AND (datetime_end <= ’2 Filter: ((NOT is_deleted) OR (qty > 0)) Rows Removed by Filter: 60545 Heap Blocks: exact=667323 Buffers: shared hit=47584 read=827816 dirtied=1 written=2292 I/O Timings: read=30152.376 write=42.134 -> Bitmap Index Scan on delivery_datetime_start_datetime_end_idx (cost=0.00..864860.96 rows=32514577 width= Index Cond: ((datetime_start >= ’2017-05-11 00:00:00’::timestamp without time zone) AND (datetime_end < Buffers: shared hit=80 read=207997 I/O Timings: read=27315.687 dataegret.com
- 36. 24 I/O timings -> Bitmap Heap Scan on delivery fi (cost=872967.27..4196621.37 rows=32425255 width=36) (actual time=30842.138..37818.082 rows=6674571 loops=1) Recheck Cond: ((datetime_start >= ’2017-05-11 00:00:00’::timestamp without time zone) AND (datetime_end <= ’2 Filter: ((NOT is_deleted) OR (qty > 0)) Rows Removed by Filter: 60545 Heap Blocks: exact=667323 Buffers: shared hit=47584 read=827816 dirtied=1 written=2292 I/O Timings: read=30152.376 write=42.134 -> Bitmap Index Scan on delivery_datetime_start_datetime_end_idx (cost=0.00..864860.96 rows=32514577 width= Index Cond: ((datetime_start >= ’2017-05-11 00:00:00’::timestamp without time zone) AND (datetime_end < Buffers: shared hit=80 read=207997 I/O Timings: read=27315.687 • 30c из 37с ушло на чтение с диска dataegret.com
- 37. 24 I/O timings -> Bitmap Heap Scan on delivery fi (cost=872967.27..4196621.37 rows=32425255 width=36) (actual time=30842.138..37818.082 rows=6674571 loops=1) Recheck Cond: ((datetime_start >= ’2017-05-11 00:00:00’::timestamp without time zone) AND (datetime_end <= ’2 Filter: ((NOT is_deleted) OR (qty > 0)) Rows Removed by Filter: 60545 Heap Blocks: exact=667323 Buffers: shared hit=47584 read=827816 dirtied=1 written=2292 I/O Timings: read=30152.376 write=42.134 -> Bitmap Index Scan on delivery_datetime_start_datetime_end_idx (cost=0.00..864860.96 rows=32514577 width= Index Cond: ((datetime_start >= ’2017-05-11 00:00:00’::timestamp without time zone) AND (datetime_end < Buffers: shared hit=80 read=207997 I/O Timings: read=27315.687 • 30c из 37с ушло на чтение с диска • Отфильтровалось относительно мало строк dataegret.com
- 38. 25 I/O timings • 30c из 37с ушло на чтение с диска • Отфильтровалось относительно мало строк • Происходит ли значительная фильтрация строк на более высоком уровне ? dataegret.com
- 39. 25 I/O timings • 30c из 37с ушло на чтение с диска • Отфильтровалось относительно мало строк • Происходит ли значительная фильтрация строк на более высоком уровне ? • Если да - возможно нужно соединять таблицы каким-то другим способом, чтобы приходилось меньше читать данных dataegret.com
- 40. 26 Sort explain analyze select distinct f1 from test_ndistinct ; QUERY PLAN ------------------------------------------------------------------------------------------- Unique (cost=1571431.43..1621431.49 rows=100000 width=4) (actual time=4791.872..7551.150 rows=90020 loops=1) -> Sort (cost=1571431.43..1596431.46 rows=10000012 width=4) (actual time=4791.870..6893.413 rows=10000000 loops=1) Sort Key: f1 Sort Method: external merge Disk: 101648kB -> Seq Scan on test_ndistinct (cost=0.00..135314.12 rows=10000012 width=4) (actual time=0.041..938.093 rows=10000000 loops=1) Planning time: 0.099 ms Execution time: 7714.701 ms dataegret.com
- 41. 27 HashAggregate set work_mem = ’8MB’; SET explain analyze select distinct f1 from test_ndistinct ; QUERY PLAN ------------------------------------------------------------------------------------------- HashAggregate (cost=160314.15..161314.15 rows=100000 width=4) (actual time=2371.902..2391.415 rows=90020 loops=1) Group Key: f1 -> Seq Scan on test_ndistinct (cost=0.00..135314.12 rows=10000012 width=4) (actual time=0.093..871.619 rows=10000000 loops=1) Planning time: 0.048 ms Execution time: 2396.186 ms dataegret.com
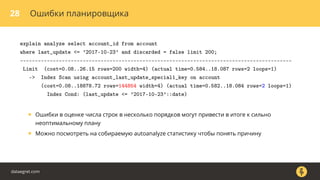
- 42. 28 Ошибки планировщика explain analyze select account_id from account where last_update <= ’2017-10-23’ and discarded = false limit 200; ------------------------------------------------------------------------------------------- Limit (cost=0.08..26.15 rows=200 width=4) (actual time=0.584..18.087 rows=2 loops=1) -> Index Scan using account_last_update_special1_key on account (cost=0.08..18878.72 rows=144854 width=4) (actual time=0.582..18.084 rows=2 loops=1) Index Cond: (last_update <= ’2017-10-23’::date) dataegret.com
- 43. 28 Ошибки планировщика explain analyze select account_id from account where last_update <= ’2017-10-23’ and discarded = false limit 200; ------------------------------------------------------------------------------------------- Limit (cost=0.08..26.15 rows=200 width=4) (actual time=0.584..18.087 rows=2 loops=1) -> Index Scan using account_last_update_special1_key on account (cost=0.08..18878.72 rows=144854 width=4) (actual time=0.582..18.084 rows=2 loops=1) Index Cond: (last_update <= ’2017-10-23’::date) • Ошибки в оценке числа строк в несколько порядков могут привести в итоге к сильно неоптимальному плану dataegret.com
- 44. 28 Ошибки планировщика explain analyze select account_id from account where last_update <= ’2017-10-23’ and discarded = false limit 200; ------------------------------------------------------------------------------------------- Limit (cost=0.08..26.15 rows=200 width=4) (actual time=0.584..18.087 rows=2 loops=1) -> Index Scan using account_last_update_special1_key on account (cost=0.08..18878.72 rows=144854 width=4) (actual time=0.582..18.084 rows=2 loops=1) Index Cond: (last_update <= ’2017-10-23’::date) • Ошибки в оценке числа строк в несколько порядков могут привести в итоге к сильно неоптимальному плану • Можно посмотреть на собираемую autoanalyze статистику чтобы понять причину dataegret.com
- 45. 28 Ошибки планировщика explain analyze select account_id from account where last_update <= ’2017-10-23’ and discarded = false limit 200; ------------------------------------------------------------------------------------------- Limit (cost=0.08..26.15 rows=200 width=4) (actual time=0.584..18.087 rows=2 loops=1) -> Index Scan using account_last_update_special1_key on account (cost=0.08..18878.72 rows=144854 width=4) (actual time=0.582..18.084 rows=2 loops=1) Index Cond: (last_update <= ’2017-10-23’::date) • Ошибки в оценке числа строк в несколько порядков могут привести в итоге к сильно неоптимальному плану • Можно посмотреть на собираемую autoanalyze статистику чтобы понять причину • Можно посмотреть переписать запрос каким-то иным способом, заставив планировщик соединять таблицы нужным образом и использовать нужные индексы dataegret.com
- 46. 29 Что можно делать ? • Если запрос выполняется за разумное время, смотрим его explain analyze • Пытаемся найти узлы, на которые больше всего уходит времени • Нет ли у нас где-то явно пропущенных индесов, в местах где много строк фильтруется ? • Нет ли проблем с bloat ? Смотрим explain (analyze, buffers) • Нет ли проблем с дисками (track_io_timing)? • Хватает ли work_mem ? • Не ошибается ли планировщик в оценке числа строк на порядки? • Не сильно ли велико время планирования? dataegret.com
- 47. 30 Что можно почитать? • depesz: Explaining the unexplainable • PostgreSQL Manual 14.1. Using EXPLAIN • Bruce Momjian – Explaining the Postgres Query Optimizer • www.slideshare.net/alexius2/ dataegret.com