Accelerate Big Data Processing with High-Performance Computing Technologies
2 likes440 views

Learn about opportunities and challenges for accelerating big data middleware on modern high-performance computing (HPC) clusters by exploiting HPC technologies.






































































































Ad
More Related Content
What's hot (20)
Similar to Accelerate Big Data Processing with High-Performance Computing Technologies (20)


















Ad
More from Intel® Software (20)




















Ad
Recently uploaded (20)




















Accelerate Big Data Processing with High-Performance Computing Technologies
- 1. Exploiting HPC Technologies to Accelerate Big Data Processing (Hadoop, Spark, and Memcached) Dhabaleswar K. (DK) Panda The Ohio State University E-mail: [email protected] http://www.cse.ohio-state.edu/~panda Talk at Intel HPC Developer Conference (SC ‘16) by Xiaoyi Lu The Ohio State University E-mail: [email protected] http://www.cse.ohio-state.edu/~luxi
- 2. Intel HPC Dev Conf (SC ‘16) 2Network Based Computing Laboratory • Big Data has become the one of the most important elements of business analytics • Provides groundbreaking opportunities for enterprise information management and decision making • The amount of data is exploding; companies are capturing and digitizing more information than ever • The rate of information growth appears to be exceeding Moore’s Law Introduction to Big Data Applications and Analytics
- 3. Intel HPC Dev Conf (SC ‘16) 3Network Based Computing Laboratory • Substantial impact on designing and utilizing data management and processing systems in multiple tiers – Front-end data accessing and serving (Online) • Memcached + DB (e.g. MySQL), HBase – Back-end data analytics (Offline) • HDFS, MapReduce, Spark Data Management and Processing on Modern Clusters
- 4. Intel HPC Dev Conf (SC ‘16) 4Network Based Computing Laboratory 0 10 20 30 40 50 60 70 80 90 100 0 50 100 150 200 250 300 350 400 450 500 PercentageofClusters NumberofClusters Timeline Percentage of Clusters Number of Clusters Trends for Commodity Computing Clusters in the Top 500 List (http://www.top500.org) 85%
- 5. Intel HPC Dev Conf (SC ‘16) 5Network Based Computing Laboratory Drivers of Modern HPC Cluster Architectures Tianhe – 2 Titan Stampede Tianhe – 1A • Multi-core/many-core technologies • Remote Direct Memory Access (RDMA)-enabled networking (InfiniBand and RoCE) • Solid State Drives (SSDs), Non-Volatile Random-Access Memory (NVRAM), NVMe-SSD • Accelerators (NVIDIA GPGPUs and Intel Xeon Phi) Accelerators / Coprocessors high compute density, high performance/watt >1 TFlop DP on a chip High Performance Interconnects - InfiniBand <1usec latency, 100Gbps Bandwidth>Multi-core Processors SSD, NVMe-SSD, NVRAM
- 6. Intel HPC Dev Conf (SC ‘16) 6Network Based Computing Laboratory • Advanced Interconnects and RDMA protocols – InfiniBand – 10-40 Gigabit Ethernet/iWARP – RDMA over Converged Enhanced Ethernet (RoCE) • Delivering excellent performance (Latency, Bandwidth and CPU Utilization) • Has influenced re-designs of enhanced HPC middleware – Message Passing Interface (MPI) and PGAS – Parallel File Systems (Lustre, GPFS, ..) • SSDs (SATA and NVMe) • NVRAM and Burst Buffer Trends in HPC Technologies
- 7. Intel HPC Dev Conf (SC ‘16) 7Network Based Computing Laboratory Interconnects and Protocols in OpenFabrics Stack for HPC (http://openfabrics.org) Kernel Space Application / Middleware Verbs Ethernet Adapter Ethernet Switch Ethernet Driver TCP/IP 1/10/40/100 GigE InfiniBand Adapter InfiniBand Switch IPoIB IPoIB Ethernet Adapter Ethernet Switch Hardware Offload TCP/IP 10/40 GigE- TOE InfiniBand Adapter InfiniBand Switch User Space RSockets RSockets iWARP Adapter Ethernet Switch TCP/IP User Space iWARP RoCE Adapter Ethernet Switch RDMA User Space RoCE InfiniBand Switch InfiniBand Adapter RDMA User Space IB Native Sockets Application / Middleware Interface Protocol Adapter Switch InfiniBand Adapter InfiniBand Switch RDMA SDP SDP
- 8. Intel HPC Dev Conf (SC ‘16) 8Network Based Computing Laboratory • 205 IB Clusters (41%) in the Jun’16 Top500 list – (http://www.top500.org) • Installations in the Top 50 (21 systems): Large-scale InfiniBand Installations 220,800 cores (Pangea) in France (11th) 74,520 cores (Tsubame 2.5) at Japan/GSIC (31st) 462,462 cores (Stampede) at TACC (12th) 88,992 cores (Mistral) at DKRZ Germany (33rd) 185,344 cores (Pleiades) at NASA/Ames (15th) 194,616 cores (Cascade) at PNNL (34th) 72,800 cores Cray CS-Storm in US (19th) 76,032 cores (Makman-2) at Saudi Aramco (39th) 72,800 cores Cray CS-Storm in US (20th) 72,000 cores (Prolix) at Meteo France, France (40th) 124,200 cores (Topaz) SGI ICE at ERDC DSRC in US (21st ) 42,688 cores (Lomonosov-2) at Russia/MSU (41st) 72,000 cores (HPC2) in Italy (22nd) 60,240 cores SGI ICE X at JAEA Japan (43rd) 152,692 cores (Thunder) at AFRL/USA (25th) 70,272 cores (Tera-1000-1) at CEA France (44th) 147,456 cores (SuperMUC) in Germany (27th) 54,432 cores (Marconi) at CINECA Italy (46th) 86,016 cores (SuperMUC Phase 2) in Germany (28th) and many more!
- 9. Intel HPC Dev Conf (SC ‘16) 9Network Based Computing Laboratory • Introduced in Oct 2000 • High Performance Data Transfer – Interprocessor communication and I/O – Low latency (<1.0 microsec), High bandwidth (up to 12.5 GigaBytes/sec -> 100Gbps), and low CPU utilization (5-10%) • Multiple Operations – Send/Recv – RDMA Read/Write – Atomic Operations (very unique) • high performance and scalable implementations of distributed locks, semaphores, collective communication operations • Leading to big changes in designing – HPC clusters – File systems – Cloud computing systems – Grid computing systems Open Standard InfiniBand Networking Technology
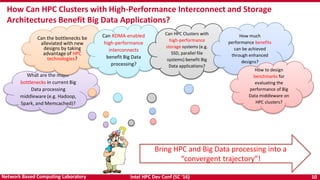
- 10. Intel HPC Dev Conf (SC ‘16) 10Network Based Computing Laboratory How Can HPC Clusters with High-Performance Interconnect and Storage Architectures Benefit Big Data Applications? Bring HPC and Big Data processing into a “convergent trajectory”! What are the major bottlenecks in current Big Data processing middleware (e.g. Hadoop, Spark, and Memcached)? Can the bottlenecks be alleviated with new designs by taking advantage of HPC technologies? Can RDMA-enabled high-performance interconnects benefit Big Data processing? Can HPC Clusters with high-performance storage systems (e.g. SSD, parallel file systems) benefit Big Data applications? How much performance benefits can be achieved through enhanced designs? How to design benchmarks for evaluating the performance of Big Data middleware on HPC clusters?
- 11. Intel HPC Dev Conf (SC ‘16) 11Network Based Computing Laboratory Designing Communication and I/O Libraries for Big Data Systems: Challenges Big Data Middleware (HDFS, MapReduce, HBase, Spark and Memcached) Networking Technologies (InfiniBand, 1/10/40/100 GigE and Intelligent NICs) Storage Technologies (HDD, SSD, and NVMe-SSD) Programming Models (Sockets) Applications Commodity Computing System Architectures (Multi- and Many-core architectures and accelerators) Other Protocols? Communication and I/O Library Point-to-Point Communication QoS Threaded Models and Synchronization Fault-ToleranceI/O and File Systems Virtualization Benchmarks Upper level Changes?
- 12. Intel HPC Dev Conf (SC ‘16) 12Network Based Computing Laboratory • Sockets not designed for high-performance – Stream semantics often mismatch for upper layers – Zero-copy not available for non-blocking sockets Can Big Data Processing Systems be Designed with High- Performance Networks and Protocols? Current Design Application Sockets 1/10/40/100 GigE Network Our Approach Application OSU Design 10/40/100 GigE or InfiniBand Verbs Interface
- 13. Intel HPC Dev Conf (SC ‘16) 13Network Based Computing Laboratory • RDMA for Apache Spark • RDMA for Apache Hadoop 2.x (RDMA-Hadoop-2.x) – Plugins for Apache, Hortonworks (HDP) and Cloudera (CDH) Hadoop distributions • RDMA for Apache HBase • RDMA for Memcached (RDMA-Memcached) • RDMA for Apache Hadoop 1.x (RDMA-Hadoop) • OSU HiBD-Benchmarks (OHB) – HDFS, Memcached, and HBase Micro-benchmarks • http://hibd.cse.ohio-state.edu • Users Base: 195 organizations from 27 countries • More than 18,500 downloads from the project site • RDMA for Impala (upcoming) The High-Performance Big Data (HiBD) Project Available for InfiniBand and RoCE
- 14. Intel HPC Dev Conf (SC ‘16) 14Network Based Computing Laboratory • High-Performance Design of Hadoop over RDMA-enabled Interconnects – High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for HDFS, MapReduce, and RPC components – Enhanced HDFS with in-memory and heterogeneous storage – High performance design of MapReduce over Lustre – Memcached-based burst buffer for MapReduce over Lustre-integrated HDFS (HHH-L-BB mode) – Plugin-based architecture supporting RDMA-based designs for Apache Hadoop, CDH and HDP – Easily configurable for different running modes (HHH, HHH-M, HHH-L, HHH-L-BB, and MapReduce over Lustre) and different protocols (native InfiniBand, RoCE, and IPoIB) • Current release: 1.1.0 – Based on Apache Hadoop 2.7.3 – Compliant with Apache Hadoop 2.7.1, HDP 2.5.0.3 and CDH 5.8.2 APIs and applications – Tested with • Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR) • RoCE support with Mellanox adapters • Various multi-core platforms • Different file systems with disks and SSDs and Lustre RDMA for Apache Hadoop 2.x Distribution http://hibd.cse.ohio-state.edu
- 15. Intel HPC Dev Conf (SC ‘16) 15Network Based Computing Laboratory • HHH: Heterogeneous storage devices with hybrid replication schemes are supported in this mode of operation to have better fault-tolerance as well as performance. This mode is enabled by default in the package. • HHH-M: A high-performance in-memory based setup has been introduced in this package that can be utilized to perform all I/O operations in- memory and obtain as much performance benefit as possible. • HHH-L: With parallel file systems integrated, HHH-L mode can take advantage of the Lustre available in the cluster. • HHH-L-BB: This mode deploys a Memcached-based burst buffer system to reduce the bandwidth bottleneck of shared file system access. The burst buffer design is hosted by Memcached servers, each of which has a local SSD. • MapReduce over Lustre, with/without local disks: Besides, HDFS based solutions, this package also provides support to run MapReduce jobs on top of Lustre alone. Here, two different modes are introduced: with local disks and without local disks. • Running with Slurm and PBS: Supports deploying RDMA for Apache Hadoop 2.x with Slurm and PBS in different running modes (HHH, HHH-M, HHH- L, and MapReduce over Lustre). Different Modes of RDMA for Apache Hadoop 2.x
- 16. Intel HPC Dev Conf (SC ‘16) 16Network Based Computing Laboratory • High-Performance Design of Spark over RDMA-enabled Interconnects – High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for Spark – RDMA-based data shuffle and SEDA-based shuffle architecture – Non-blocking and chunk-based data transfer – Easily configurable for different protocols (native InfiniBand, RoCE, and IPoIB) • Current release: 0.9.1 – Based on Apache Spark 1.5.1 – Tested with • Mellanox InfiniBand adapters (DDR, QDR and FDR) • RoCE support with Mellanox adapters • Various multi-core platforms • RAM disks, SSDs, and HDD – http://hibd.cse.ohio-state.edu RDMA for Apache Spark Distribution
- 17. Intel HPC Dev Conf (SC ‘16) 17Network Based Computing Laboratory • RDMA for Apache Hadoop 2.x and RDMA for Apache Spark are installed and available on SDSC Comet. – Examples for various modes of usage are available in: • RDMA for Apache Hadoop 2.x: /share/apps/examples/HADOOP • RDMA for Apache Spark: /share/apps/examples/SPARK/ – Please email [email protected] (reference Comet as the machine, and SDSC as the site) if you have any further questions about usage and configuration. • RDMA for Apache Hadoop is also available on Chameleon Cloud as an appliance – https://www.chameleoncloud.org/appliances/17/ HiBD Packages on SDSC Comet and Chameleon Cloud M. Tatineni, X. Lu, D. J. Choi, A. Majumdar, and D. K. Panda, Experiences and Benefits of Running RDMA Hadoop and Spark on SDSC Comet, XSEDE’16, July 2016
- 18. Intel HPC Dev Conf (SC ‘16) 18Network Based Computing Laboratory • High-Performance Design of HBase over RDMA-enabled Interconnects – High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for HBase – Compliant with Apache HBase 1.1.2 APIs and applications – On-demand connection setup – Easily configurable for different protocols (native InfiniBand, RoCE, and IPoIB) • Current release: 0.9.1 – Based on Apache HBase 1.1.2 – Tested with • Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR) • RoCE support with Mellanox adapters • Various multi-core platforms – http://hibd.cse.ohio-state.edu RDMA for Apache HBase Distribution
- 19. Intel HPC Dev Conf (SC ‘16) 19Network Based Computing Laboratory • High-Performance Design of Memcached over RDMA-enabled Interconnects – High performance RDMA-enhanced design with native InfiniBand and RoCE support at the verbs-level for Memcached and libMemcached components – High performance design of SSD-Assisted Hybrid Memory – Non-Blocking Libmemcached Set/Get API extensions – Support for burst-buffer mode in Lustre-integrated design of HDFS in RDMA for Apache Hadoop-2.x – Easily configurable for native InfiniBand, RoCE and the traditional sockets-based support (Ethernet and InfiniBand with IPoIB) • Current release: 0.9.5 – Based on Memcached 1.4.24 and libMemcached 1.0.18 – Compliant with libMemcached APIs and applications – Tested with • Mellanox InfiniBand adapters (DDR, QDR, FDR, and EDR) • RoCE support with Mellanox adapters • Various multi-core platforms • SSD – http://hibd.cse.ohio-state.edu RDMA for Memcached Distribution
- 20. Intel HPC Dev Conf (SC ‘16) 20Network Based Computing Laboratory • Micro-benchmarks for Hadoop Distributed File System (HDFS) – Sequential Write Latency (SWL) Benchmark, Sequential Read Latency (SRL) Benchmark, Random Read Latency (RRL) Benchmark, Sequential Write Throughput (SWT) Benchmark, Sequential Read Throughput (SRT) Benchmark – Support benchmarking of • Apache Hadoop 1.x and 2.x HDFS, Hortonworks Data Platform (HDP) HDFS, Cloudera Distribution of Hadoop (CDH) HDFS • Micro-benchmarks for Memcached – Get Benchmark, Set Benchmark, and Mixed Get/Set Benchmark, Non-Blocking API Latency Benchmark, Hybrid Memory Latency Benchmark • Micro-benchmarks for HBase – Get Latency Benchmark, Put Latency Benchmark • Current release: 0.9.1 • http://hibd.cse.ohio-state.edu OSU HiBD Micro-Benchmark (OHB) Suite – HDFS, Memcached, and HBase
- 21. Intel HPC Dev Conf (SC ‘16) 21Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 22. Intel HPC Dev Conf (SC ‘16) 22Network Based Computing Laboratory • Enables high performance RDMA communication, while supporting traditional socket interface • JNI Layer bridges Java based HDFS with communication library written in native code Design Overview of HDFS with RDMA HDFS Verbs RDMA Capable Networks (IB, iWARP, RoCE ..) Applications 1/10/40/100 GigE, IPoIB Network Java Socket Interface Java Native Interface (JNI) WriteOthers OSU Design • Design Features – RDMA-based HDFS write – RDMA-based HDFS replication – Parallel replication support – On-demand connection setup – InfiniBand/RoCE support N. S. Islam, M. W. Rahman, J. Jose, R. Rajachandrasekar, H. Wang, H. Subramoni, C. Murthy and D. K. Panda , High Performance RDMA-Based Design of HDFS over InfiniBand , Supercomputing (SC), Nov 2012 N. Islam, X. Lu, W. Rahman, and D. K. Panda, SOR-HDFS: A SEDA-based Approach to Maximize Overlapping in RDMA-Enhanced HDFS, HPDC '14, June 2014
- 23. Intel HPC Dev Conf (SC ‘16) 23Network Based Computing Laboratory Triple-H Heterogeneous Storage • Design Features – Three modes • Default (HHH) • In-Memory (HHH-M) • Lustre-Integrated (HHH-L) – Policies to efficiently utilize the heterogeneous storage devices • RAM, SSD, HDD, Lustre – Eviction/Promotion based on data usage pattern – Hybrid Replication – Lustre-Integrated mode: • Lustre-based fault-tolerance Enhanced HDFS with In-Memory and Heterogeneous Storage Hybrid Replication Data Placement Policies Eviction/Promotion RAM Disk SSD HDD Lustre N. Islam, X. Lu, M. W. Rahman, D. Shankar, and D. K. Panda, Triple-H: A Hybrid Approach to Accelerate HDFS on HPC Clusters with Heterogeneous Storage Architecture, CCGrid ’15, May 2015 Applications
- 24. Intel HPC Dev Conf (SC ‘16) 24Network Based Computing Laboratory Design Overview of MapReduce with RDMA MapReduce Verbs RDMA Capable Networks (IB, iWARP, RoCE ..) OSU Design Applications 1/10/40/100 GigE, IPoIB Network Java Socket Interface Java Native Interface (JNI) Job Tracker Task Tracker Map Reduce • Enables high performance RDMA communication, while supporting traditional socket interface • JNI Layer bridges Java based MapReduce with communication library written in native code • Design Features – RDMA-based shuffle – Prefetching and caching map output – Efficient Shuffle Algorithms – In-memory merge – On-demand Shuffle Adjustment – Advanced overlapping • map, shuffle, and merge • shuffle, merge, and reduce – On-demand connection setup – InfiniBand/RoCE support M. W. Rahman, X. Lu, N. S. Islam, and D. K. Panda, HOMR: A Hybrid Approach to Exploit Maximum Overlapping in MapReduce over High Performance Interconnects, ICS, June 2014
- 25. Intel HPC Dev Conf (SC ‘16) 25Network Based Computing Laboratory 0 50 100 150 200 250 300 350 400 80 120 160 ExecutionTime(s) Data Size (GB) IPoIB (EDR) OSU-IB (EDR) 0 100 200 300 400 500 600 700 800 80 160 240 ExecutionTime(s) Data Size (GB) IPoIB (EDR) OSU-IB (EDR) Performance Numbers of RDMA for Apache Hadoop 2.x – RandomWriter & TeraGen in OSU-RI2 (EDR) Cluster with 8 Nodes with a total of 64 maps • RandomWriter – 3x improvement over IPoIB for 80-160 GB file size • TeraGen – 4x improvement over IPoIB for 80-240 GB file size RandomWriter TeraGen Reduced by 3x Reduced by 4x
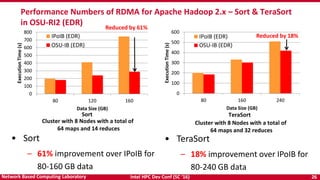
- 26. Intel HPC Dev Conf (SC ‘16) 26Network Based Computing Laboratory 0 100 200 300 400 500 600 700 800 80 120 160 ExecutionTime(s) Data Size (GB) IPoIB (EDR) OSU-IB (EDR) Performance Numbers of RDMA for Apache Hadoop 2.x – Sort & TeraSort in OSU-RI2 (EDR) Cluster with 8 Nodes with a total of 64 maps and 32 reduces • Sort – 61% improvement over IPoIB for 80-160 GB data • TeraSort – 18% improvement over IPoIB for 80-240 GB data Reduced by 61% Reduced by 18% Cluster with 8 Nodes with a total of 64 maps and 14 reduces Sort TeraSort 0 100 200 300 400 500 600 80 160 240 ExecutionTime(s) Data Size (GB) IPoIB (EDR) OSU-IB (EDR)
- 27. Intel HPC Dev Conf (SC ‘16) 27Network Based Computing Laboratory Evaluation of HHH and HHH-L with Applications HDFS (FDR) HHH (FDR) 60.24 s 48.3 s CloudBurstMR-MSPolyGraph 0 200 400 600 800 1000 4 6 8 ExecutionTime(s) Concurrent maps per host HDFS Lustre HHH-L Reduced by 79% • MR-MSPolygraph on OSU RI with 1,000 maps – HHH-L reduces the execution time by 79% over Lustre, 30% over HDFS • CloudBurst on TACC Stampede – With HHH: 19% improvement over HDFS
- 28. Intel HPC Dev Conf (SC ‘16) 28Network Based Computing Laboratory Evaluation with Spark on SDSC Gordon (HHH vs. Tachyon/Alluxio) • For 200GB TeraGen on 32 nodes – Spark-TeraGen: HHH has 2.4x improvement over Tachyon; 2.3x over HDFS-IPoIB (QDR) – Spark-TeraSort: HHH has 25.2% improvement over Tachyon; 17% over HDFS-IPoIB (QDR) 0 20 40 60 80 100 120 140 160 180 8:50 16:100 32:200 ExecutionTime(s) Cluster Size : Data Size (GB) IPoIB (QDR) Tachyon OSU-IB (QDR) 0 100 200 300 400 500 600 700 8:50 16:100 32:200 ExecutionTime(s) Cluster Size : Data Size (GB) Reduced by 2.4x Reduced by 25.2% TeraGen TeraSort N. Islam, M. W. Rahman, X. Lu, D. Shankar, and D. K. Panda, Performance Characterization and Acceleration of In-Memory File Systems for Hadoop and Spark Applications on HPC Clusters, IEEE BigData ’15, October 2015
- 29. Intel HPC Dev Conf (SC ‘16) 29Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 30. Intel HPC Dev Conf (SC ‘16) 30Network Based Computing Laboratory Performance Numbers of RDMA for Apache HBase – OHB in SDSC-Comet 0 2000 4000 6000 8000 10000 12000 14000 2 8 32 128 512 2k 8k 32k 128k 512k Latency(us) Message Size Put IPoIB RDMA 0 1000 2000 3000 4000 5000 2 8 32 128 512 2k 8k 32k 128k512k Latency(us) Message Size Get IPoIB RDMA • Up to 8.6x improvement over IPoIB Reduced by 8.6x • Up to 5.3x improvement over IPoIB Reduced by 3.8x Reduced by 5.3x Reduced by 8.6x Evaluation with OHB Put and Get Micro-Benchmarks (1 Server, 1 Client)
- 31. Intel HPC Dev Conf (SC ‘16) 31Network Based Computing Laboratory Performance Numbers of RDMA for Apache HBase – YCSB in SDSC-Comet 0 20000 40000 60000 80000 100000 120000 4 8 16 32 64 128 Throughput(Operations/sec) Number of clients Workload A (50% read, 50% update) IPoIB RDMA 0 100000 200000 300000 400000 500000 4 8 16 32 64 128 Throughput(Operations/sec) Number of clients Workload C (100% read) IPoIB RDMA • Up to 2.4x improvement over IPoIB Increased by 83% • Up to 3.6x improvement over IPoIB Increased by 3.6x Evaluation with YCSB Workloads A and C (4 Servers)
- 32. Intel HPC Dev Conf (SC ‘16) 32Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 33. Intel HPC Dev Conf (SC ‘16) 33Network Based Computing Laboratory • Design Features – RDMA based shuffle plugin – SEDA-based architecture – Dynamic connection management and sharing – Non-blocking data transfer – Off-JVM-heap buffer management – InfiniBand/RoCE support Design Overview of Spark with RDMA • Enables high performance RDMA communication, while supporting traditional socket interface • JNI Layer bridges Scala based Spark with communication library written in native code X. Lu, M. W. Rahman, N. Islam, D. Shankar, and D. K. Panda, Accelerating Spark with RDMA for Big Data Processing: Early Experiences, Int'l Symposium on High Performance Interconnects (HotI'14), August 2014 X. Lu, D. Shankar, S. Gugnani, and D. K. Panda, High-Performance Design of Apache Spark with RDMA and Its Benefits on Various Workloads, IEEE BigData ‘16, Dec. 2016. Spark Core RDMA Capable Networks (IB, iWARP, RoCE ..) Apache Spark Benchmarks/Applications/Libraries/Frameworks 1/10/40/100 GigE, IPoIB Network Java Socket Interface Java Native Interface (JNI) Native RDMA-based Comm. Engine Shuffle Manager (Sort, Hash, Tungsten-Sort) Block Transfer Service (Netty, NIO, RDMA-Plugin) Netty Server NIO Server RDMA Server Netty Client NIO Client RDMA Client
- 34. Intel HPC Dev Conf (SC ‘16) 34Network Based Computing Laboratory • InfiniBand FDR, SSD, 64 Worker Nodes, 1536 Cores, (1536M 1536R) • RDMA-based design for Spark 1.5.1 • RDMA vs. IPoIB with 1536 concurrent tasks, single SSD per node. – SortBy: Total time reduced by up to 80% over IPoIB (56Gbps) – GroupBy: Total time reduced by up to 74% over IPoIB (56Gbps) Performance Evaluation on SDSC Comet – SortBy/GroupBy 64 Worker Nodes, 1536 cores, SortByTest Total Time 64 Worker Nodes, 1536 cores, GroupByTest Total Time 0 50 100 150 200 250 300 64 128 256 Time(sec) Data Size (GB) IPoIB RDMA 0 50 100 150 200 250 64 128 256 Time(sec) Data Size (GB) IPoIB RDMA 74%80%
- 35. Intel HPC Dev Conf (SC ‘16) 35Network Based Computing Laboratory • InfiniBand FDR, SSD, 32/64 Worker Nodes, 768/1536 Cores, (768/1536M 768/1536R) • RDMA-based design for Spark 1.5.1 • RDMA vs. IPoIB with 768/1536 concurrent tasks, single SSD per node. – 32 nodes/768 cores: Total time reduced by 37% over IPoIB (56Gbps) – 64 nodes/1536 cores: Total time reduced by 43% over IPoIB (56Gbps) Performance Evaluation on SDSC Comet – HiBench PageRank 32 Worker Nodes, 768 cores, PageRank Total Time 64 Worker Nodes, 1536 cores, PageRank Total Time 0 50 100 150 200 250 300 350 400 450 Huge BigData Gigantic Time(sec) Data Size (GB) IPoIB RDMA 0 100 200 300 400 500 600 700 800 Huge BigData Gigantic Time(sec) Data Size (GB) IPoIB RDMA 43%37%
- 36. Intel HPC Dev Conf (SC ‘16) 36Network Based Computing Laboratory Performance Evaluation on SDSC Comet: Astronomy Application • Kira Toolkit1: Distributed astronomy image processing toolkit implemented using Apache Spark. • Source extractor application, using a 65GB dataset from the SDSS DR2 survey that comprises 11,150 image files. • Compare RDMA Spark performance with the standard apache implementation using IPoIB. 1. Z. Zhang, K. Barbary, F. A. Nothaft, E.R. Sparks, M.J. Franklin, D.A. Patterson, S. Perlmutter. Scientific Computing meets Big Data Technology: An Astronomy Use Case. CoRR, vol: abs/1507.03325, Aug 2015. 0 20 40 60 80 100 120 RDMA Spark Apache Spark (IPoIB) 21 % Execution times (sec) for Kira SE benchmark using 65 GB dataset, 48 cores. M. Tatineni, X. Lu, D. J. Choi, A. Majumdar, and D. K. Panda, Experiences and Benefits of Running RDMA Hadoop and Spark on SDSC Comet, XSEDE’16, July 2016
- 37. Intel HPC Dev Conf (SC ‘16) 37Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs and Studies – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 38. Intel HPC Dev Conf (SC ‘16) 38Network Based Computing Laboratory 1 10 100 1000 1 2 4 8 16 32 64 128 256 512 1K 2K 4K Time(us) Message Size OSU-IB (FDR) 0 200 400 600 800 16 32 64 128 256 512 102420484080 Thousandsof Transactionsper Second(TPS) No. of Clients • Memcached Get latency – 4 bytes OSU-IB: 2.84 us; IPoIB: 75.53 us, 2K bytes OSU-IB: 4.49 us; IPoIB: 123.42 us • Memcached Throughput (4bytes) – 4080 clients OSU-IB: 556 Kops/sec, IPoIB: 233 Kops/s, Nearly 2X improvement in throughput Memcached GET Latency Memcached Throughput Memcached Performance (FDR Interconnect) Experiments on TACC Stampede (Intel SandyBridge Cluster, IB: FDR) Latency Reduced by nearly 20X 2X J. Jose, H. Subramoni, M. Luo, M. Zhang, J. Huang, M. W. Rahman, N. Islam, X. Ouyang, H. Wang, S. Sur and D. K. Panda, Memcached Design on High Performance RDMA Capable Interconnects, ICPP’11 J. Jose, H. Subramoni, K. Kandalla, M. W. Rahman, H. Wang, S. Narravula, and D. K. Panda, Scalable Memcached design for InfiniBand Clusters using Hybrid Transport, CCGrid’12
- 39. Intel HPC Dev Conf (SC ‘16) 39Network Based Computing Laboratory • Illustration with Read-Cache-Read access pattern using modified mysqlslap load testing tool • Memcached-RDMA can - improve query latency by up to 66% over IPoIB (32Gbps) - throughput by up to 69% over IPoIB (32Gbps) Micro-benchmark Evaluation for OLDP workloads 0 1 2 3 4 5 6 7 8 64 96 128 160 320 400 Latency(sec) No. of Clients Memcached-IPoIB (32Gbps) Memcached-RDMA (32Gbps) 0 1000 2000 3000 4000 64 96 128 160 320 400 Throughput(Kq/s) No. of Clients Memcached-IPoIB (32Gbps) Memcached-RDMA (32Gbps) D. Shankar, X. Lu, J. Jose, M. W. Rahman, N. Islam, and D. K. Panda, Can RDMA Benefit On-Line Data Processing Workloads with Memcached and MySQL, ISPASS’15 Reduced by 66%
- 40. Intel HPC Dev Conf (SC ‘16) 40Network Based Computing Laboratory • RDMA-based Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs and Studies – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 41. Intel HPC Dev Conf (SC ‘16) 41Network Based Computing Laboratory • The current benchmarks provide some performance behavior • However, do not provide any information to the designer/developer on: – What is happening at the lower-layer? – Where the benefits are coming from? – Which design is leading to benefits or bottlenecks? – Which component in the design needs to be changed and what will be its impact? – Can performance gain/loss at the lower-layer be correlated to the performance gain/loss observed at the upper layer? Are the Current Benchmarks Sufficient for Big Data?
- 42. Intel HPC Dev Conf (SC ‘16) 42Network Based Computing Laboratory Big Data Middleware (HDFS, MapReduce, HBase, Spark and Memcached) Networking Technologies (InfiniBand, 1/10/40/100 GigE and Intelligent NICs) Storage Technologies (HDD, SSD, and NVMe-SSD) Programming Models (Sockets) Applications Commodity Computing System Architectures (Multi- and Many-core architectures and accelerators) Other Protocols? Communication and I/O Library Point-to-Point Communication QoS Threaded Models and Synchronization Fault-ToleranceI/O and File Systems Virtualization Benchmarks RDMA Protocols Challenges in Benchmarking of RDMA-based Designs Current Benchmarks No Benchmarks Correlation?
- 43. Intel HPC Dev Conf (SC ‘16) 43Network Based Computing Laboratory Big Data Middleware (HDFS, MapReduce, HBase, Spark and Memcached) Networking Technologies (InfiniBand, 1/10/40/100 GigE and Intelligent NICs) Storage Technologies (HDD, SSD, and NVMe-SSD) Programming Models (Sockets) Applications Commodity Computing System Architectures (Multi- and Many-core architectures and accelerators) Other Protocols? Communication and I/O Library Point-to-Point Communication QoS Threaded Models and Synchronization Fault-ToleranceI/O and File Systems Virtualization Benchmarks RDMA Protocols Iterative Process – Requires Deeper Investigation and Design for Benchmarking Next Generation Big Data Systems and Applications Applications-Level Benchmarks Micro- Benchmarks
- 44. Intel HPC Dev Conf (SC ‘16) 44Network Based Computing Laboratory • HDFS Benchmarks – Sequential Write Latency (SWL) Benchmark – Sequential Read Latency (SRL) Benchmark – Random Read Latency (RRL) Benchmark – Sequential Write Throughput (SWT) Benchmark – Sequential Read Throughput (SRT) Benchmark • Memcached Benchmarks – Get, Set and Mixed Get/Set Benchmarks – Non-blocking and Hybrid Memory Latency Benchmarks • HBase Benchmarks – Get and Put Latency Benchmarks • Available as a part of OHB 0.9.1 OSU HiBD Benchmarks (OHB) N. S. Islam, X. Lu, M. W. Rahman, J. Jose, and D. K. Panda, A Micro-benchmark Suite for Evaluating HDFS Operations on Modern Clusters, Int'l Workshop on Big Data Benchmarking (WBDB '12), December 2012 D. Shankar, X. Lu, M. W. Rahman, N. Islam, and D. K. Panda, A Micro-Benchmark Suite for Evaluating Hadoop MapReduce on High- Performance Networks, BPOE-5 (2014) X. Lu, M. W. Rahman, N. Islam, and D. K. Panda, A Micro-Benchmark Suite for Evaluating Hadoop RPC on High-Performance Networks, Int'l Workshop on Big Data Benchmarking (WBDB '13), July 2013 To be Released
- 45. Intel HPC Dev Conf (SC ‘16) 45Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 46. Intel HPC Dev Conf (SC ‘16) 46Network Based Computing Laboratory • Design Features – Memcached-based burst-buffer system • Hides latency of parallel file system access • Read from local storage and Memcached – Data locality achieved by writing data to local storage – Different approaches of integration with parallel file system to guarantee fault-tolerance Accelerating I/O Performance of Big Data Analytics through RDMA-based Key-Value Store Application I/O Forwarding Module Map/Reduce Task DataNode Local Disk Data LocalityFault-tolerance Lustre Memcached-based Burst Buffer System
- 47. Intel HPC Dev Conf (SC ‘16) 47Network Based Computing Laboratory Evaluation with PUMA Workloads Gains on OSU RI with our approach (Mem-bb) on 24 nodes • SequenceCount: 34.5% over Lustre, 40% over HDFS • RankedInvertedIndex: 27.3% over Lustre, 48.3% over HDFS • HistogramRating: 17% over Lustre, 7% over HDFS 0 500 1000 1500 2000 2500 3000 3500 4000 4500 SeqCount RankedInvIndex HistoRating ExecutionTime(s) Workloads HDFS (32Gbps) Lustre (32Gbps) Mem-bb (32Gbps) 48.3% 40% 17% N. S. Islam, D. Shankar, X. Lu, M. W. Rahman, and D. K. Panda, Accelerating I/O Performance of Big Data Analytics with RDMA- based Key-Value Store, ICPP ’15, September 2015
- 48. Intel HPC Dev Conf (SC ‘16) 48Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 49. Intel HPC Dev Conf (SC ‘16) 49Network Based Computing Laboratory • ohb_memlat & ohb_memthr latency & throughput micro-benchmarks • Memcached-RDMA can - improve query latency by up to 70% over IPoIB (32Gbps) - improve throughput by up to 2X over IPoIB (32Gbps) - No overhead in using hybrid mode when all data can fit in memory Performance Benefits of Hybrid Memcached (Memory + SSD) on SDSC-Gordon 0 2 4 6 8 10 64 128 256 512 1024 Throughput(milliontrans/sec) No. of Clients IPoIB (32Gbps) RDMA-Mem (32Gbps) RDMA-Hybrid (32Gbps) 0 100 200 300 400 500 Averagelatency(us) Message Size (Bytes) 2X
- 50. Intel HPC Dev Conf (SC ‘16) 50Network Based Computing Laboratory – Memcached latency test with Zipf distribution, server with 1 GB memory, 32 KB key-value pair size, total size of data accessed is 1 GB (when data fits in memory) and 1.5 GB (when data does not fit in memory) – When data fits in memory: RDMA-Mem/Hybrid gives 5x improvement over IPoIB-Mem – When data does not fit in memory: RDMA-Hybrid gives 2x-2.5x over IPoIB/RDMA-Mem Performance Evaluation on IB FDR + SATA/NVMe SSDs (Hybrid Memory) 0 500 1000 1500 2000 2500 Set Get Set Get Set Get Set Get Set Get Set Get Set Get Set Get IPoIB-Mem RDMA-Mem RDMA-Hybrid-SATA RDMA-Hybrid- NVMe IPoIB-Mem RDMA-Mem RDMA-Hybrid-SATA RDMA-Hybrid- NVMe Data Fits In Memory Data Does Not Fit In Memory Latency(us) slab allocation (SSD write) cache check+load (SSD read) cache update server response client wait miss-penalty
- 51. Intel HPC Dev Conf (SC ‘16) 51Network Based Computing Laboratory – Data does not fit in memory: Non-blocking Memcached Set/Get API Extensions can achieve • >16x latency improvement vs. blocking API over RDMA-Hybrid/RDMA-Mem w/ penalty • >2.5x throughput improvement vs. blocking API over default/optimized RDMA-Hybrid – Data fits in memory: Non-blocking Extensions perform similar to RDMA-Mem/RDMA-Hybrid and >3.6x improvement over IPoIB-Mem Performance Evaluation with Non-Blocking Memcached API 0 500 1000 1500 2000 2500 Set Get Set Get Set Get Set Get Set Get Set Get IPoIB-Mem RDMA-Mem H-RDMA-Def H-RDMA-Opt-Block H-RDMA-Opt-NonB- i H-RDMA-Opt-NonB- b AverageLatency(us) MissPenalty(BackendDBAccessOverhead) ClientWait ServerResponse CacheUpdate Cachecheck+Load(Memoryand/orSSDread) SlabAllocation(w/SSDwriteonOut-of-Mem) H = Hybrid Memcached over SATA SSD Opt = Adaptive slab manager Block = Default Blocking API NonB-i = Non-blocking iset/iget API NonB-b = Non-blocking bset/bget API w/ buffer re-use guarantee
- 52. Intel HPC Dev Conf (SC ‘16) 52Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 53. Intel HPC Dev Conf (SC ‘16) 53Network Based Computing Laboratory • Locality and Storage type-aware data access • Enhanced data access strategies for Hadoop and Spark for clusters with heterogeneous storage characteristics – different nodes have different types of storage devices • Re-design HDFS to incorporate the proposed strategies – Upper-level frameworks can transparently leverage the benefits Efficient Data Access Strategies with Heterogeneous Storage Hadoop/Spark Workloads Access Strategy Selector Weight Distributor Locality Detector Storage Type Fetcher DataNode Selector DataNode SSD HDD Storage Monitor Connection Tracker N. Islam, M. W. Rahman, X. Lu, and D. K. Panda, Efficient Data Access Strategies for Hadoop and Spark on HPC Clusters with Heterogeneous Storage, accepted at BigData ’16, December 2016
- 54. Intel HPC Dev Conf (SC ‘16) 54Network Based Computing Laboratory Evaluation with Sort Benchmark OSU RI2 EDR Cluster • Hadoop – 32% improvement for 320GB data size on 16 nodes • Spark – 18% improvement for 320GB data size on 16 nodes Hadoop Sort Spark Sort Reduced by 32% Reduced by 18% 0 100 200 300 400 500 600 700 4:80 8:160 16:320 ExecutionTime(s) Cluster Size: Data Size (GB) HDFS OSU-Design 0 50 100 150 200 250 300 350 400 450 4:80 8:160 16:320 ExecutionTime(s) Cluster Size: Data Size (GB)
- 55. Intel HPC Dev Conf (SC ‘16) 55Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 56. Intel HPC Dev Conf (SC ‘16) 56Network Based Computing Laboratory • Hybrid and resilient key-value store- based Burst-Buffer system Over Lustre • Overcome limitations of local storage on HPC cluster nodes • Light-weight transparent interface to Hadoop/Spark applications • Accelerating I/O-intensive Big Data workloads – Non-blocking Memcached APIs to maximize overlap – Client-based replication for resilience – Asynchronous persistence to Lustre parallel file system Burst-Buffer Over Lustre for Accelerating Big Data I/O (Boldio) D. Shankar, X. Lu, D. K. Panda, Boldio: A Hybrid and Resilient Burst-Buffer over Lustre for Accelerating Big Data I/O, IEEE Big Data 2016. DirectoverLustre Hadoop Applications/Benchmarks (E.g. MapReduce, Spark) Hadoop File System Class Abstraction (LocalFileSystem) Burst-Buffer Memcached Cluster Burst-Buffer Libmemcached Client RDMA-enhanced Communication Engine Non-Blocking API Blocking API RDMA-enhanced Comm. Engine Hyb-Mem Manager (RAM/SSD) Persistence Mgr. RDMA-enhanced Comm. Engine Hyb-Mem Manager (RAM/SSD) Persistence Mgr. Boldio ….. Co-Design BoldioFileSystem Abs. Lustre Parallel File System MDS OSS OSS OSS MDT MDT OST OST OST OST OST OST BoldioServerBoldioClient
- 57. Intel HPC Dev Conf (SC ‘16) 57Network Based Computing Laboratory • Based on RDMA-based Libmemcached/Memcached 0.9.3, Hadoop-2.6.0 • InfiniBand QDR, 24GB RAM + PCIe-SSDs, 12 nodes, 32/48 Map/Reduce Tasks, 4-node Memcached cluster • Boldio can improve – throughput over Lustre by about 3x for write throughput and 7x for read throughput – execution time of Hadoop benchmarks over Lustre, e.g. Wordcount, Cloudburst by >21% • Contrasting with Alluxio (formerly Tachyon) – Performance degrades about 15x when Alluxio cannot leverage local storage (Alluxio-Local vs. Alluxio-Remote) – Boldio can improve throughput over Alluxio with all remote workers by about 3.5x - 8 .8x (Alluxio-Remote vs. Boldio) Performance Evaluation with Boldio Hadoop/Spark Workloads 21% 0 50 100 150 200 250 300 350 400 450 WordCount InvIndx CloudBurst Spark TeraGen Latency(sec) Lustre-Direct Alluxio-Remote Boldio DFSIO Throughput 0.00 10000.00 20000.00 30000.00 40000.00 50000.00 60000.00 70000.00 20 GB 40 GB 20 GB 40 GB Write Read Agg.Throughput(MBps) Lustre-Direct Alluxio-Local Alluxio-Remote Boldio ~3x ~7x
- 58. Intel HPC Dev Conf (SC ‘16) 58Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 59. Intel HPC Dev Conf (SC ‘16) 59Network Based Computing Laboratory • Challenges – Operations on Distributed Ordered Table (DOT) with indexing techniques are network intensive – Additional overhead of creating and maintaining secondary indices – Can RDMA benefit indexing techniques (Apache Phoenix and CCIndex) on HBase? • Results – Evaluation with Apache Phoenix and CCIndex – Up to 2x improvement in query throughput – Up to 35% reduction in application workload execution time Collaboration with Institute of Computing Technology, Chinese Academy of Sciences Accelerating Indexing Techniques on HBase with RDMA S. Gugnani, X. Lu, L. Zha, and D. K. Panda, Characterizing and Accelerating Indexing Techniques on HBase for Distributed Ordered Table-based Queries and Applications (Under review) 0 5000 10000 15000 Query1 Query2 THROUGHPUT TPC-H Query Benchmarks HBase RDMA-HBase HBase-Phoenix RDMA-HBase-Phoenix HBase-CCIndex RDMA-HBase-CCIndex Increased by 2x 0 100 200 300 400 500 600 Workload1 Workload2 Workload3 Workload4 EXECUTIONTIME Ad Master Application Workloads HBase-Phoenix RDMA-HBase-Phoenix HBase-CCIndex RDMA-HBase-CCIndex Reduced by 35%
- 60. Intel HPC Dev Conf (SC ‘16) 60Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 61. Intel HPC Dev Conf (SC ‘16) 61Network Based Computing Laboratory Challenges of Tuning and Profiling • MapReduce systems have different configuration parameters based on the underlying component that uses these • The parameter files vary across different MapReduce stacks • Proposed a generalized parameter space for HPC clusters • Two broad dimensions: user space and system space; existing parameters can be categorized in the proposed spaces
- 62. Intel HPC Dev Conf (SC ‘16) 62Network Based Computing Laboratory MR-Advisor Overview • A generalized framework for Big Data processing engines to perform tuning, profiling, and prediction • Current framework can work with Hadoop, Spark, and RDMA MapReduce (OSU-MR) • Can also provide tuning for different file systems (e.g. HDFS, Lustre, Tachyon), resource managers (e.g. YARN), and applications
- 63. Intel HPC Dev Conf (SC ‘16) 63Network Based Computing Laboratory Execution Details in MR-Advisor • Workload Generator maps the input parameters to the appropriate configuration and generates workload for each tuning test • Job submitter deploys small clusters for each experiment and runs the workload on these deployments • Job Tuning Tracker monitors failed jobs and re-launches, if necessary Workload Preparation and Deployment Unit Workload Generator Job Submitter Job Tuning Tracker Compute Nodes Lustre Installation MDS OSS InfiniBand/ Ethernet App Master Map/Reduce NM DN RM/Spark Master Tachyon Master/ NN Spark Worker Tachyon Worker DN App Master Map/Reduce NM LC M. W. Rahman , N. S. Islam, X. Lu, D. Shankar, and D. K. Panda, MR-Advisor: A Comprehensive Tuning Tool for Advising HPC Users to Accelerate MapReduce Applications on Supercomputers, SBAC-PAD, 2016.
- 64. Intel HPC Dev Conf (SC ‘16) 64Network Based Computing Laboratory Tuning Experiments with MR-Advisor (TACC Stampede) Apache MR over HDFS OSU-MR over HDFS Apache Spark over HDFS Apache MR over Lustre OSU-MR over Lustre Apache Spark over Lustre 23% 17% 34% 46% 58% 28% Performance improvements compared to current best practice values
- 65. Intel HPC Dev Conf (SC ‘16) 65Network Based Computing Laboratory • Basic Designs – HDFS, MapReduce, and RPC – HBase – Spark – Memcached – OSU HiBD Benchmarks (OHB) • Advanced Designs – HDFS+Memcached-based Burst-Buffer – Memcached with Hybrid Memory and Non-blocking APIs – Data Access Strategies with Heterogeneous Storage (Hadoop and Spark) – Accelerating Big Data I/O (Lustre + Burst-Buffer) – Efficient Indexing with RDMA-HBase – MR-Advisor • BigData + HPC Cloud Acceleration Case Studies and Performance Evaluation
- 66. Intel HPC Dev Conf (SC ‘16) 66Network Based Computing Laboratory • Motivation – Performance attributes of Big Data workloads when using SR-IOV are not known – Impact of VM subscription policies, data size, and type of workload on performance of workloads with SR-IOV not evaluated in systematic manner • Results – Evaluation on Chameleon Cloud with RDMA- Hadoop – Only 0.3 – 13% overhead with SR-IOV compared to native execution – Best VM subscription policy depends on type of workload Performance Characterization of Hadoop Workloads on SR- IOV-enabled Clouds S. Gugnani, X. Lu, and D. K. Panda, Performance Characterization of Hadoop Workloads on SR-IOV-enabled Virtualized InfiniBand Clusters, accepted at BDCAT’16, December 2016 0 200 400 40 GB 60 GB 40 GB 60 GB EXECUTIONTIME Hadoop Workloads Native (1 DN, 1 NM) Native (2 DN, 2 NM) VM per node VM per socket TeraGen WordCount 0 500 1000 Sample Data 1 GB 60 GB 90 GB EXECUTIONTIME Applications Native (1 DN, 1 NM) Native (2 DN, 2 NM) VM per node VM per socket CloudBurst Self-join
- 67. Intel HPC Dev Conf (SC ‘16) 67Network Based Computing Laboratory • Challenges – Existing designs in Hadoop not virtualization- aware – No support for automatic topology detection • Design – Automatic Topology Detection using MapReduce-based utility • Requires no user input • Can detect topology changes during runtime without affecting running jobs – Virtualization and topology-aware communication through map task scheduling and YARN container allocation policy extensions Virtualization-aware and Automatic Topology Detection Schemes in Hadoop on InfiniBand S. Gugnani, X. Lu, and D. K. Panda, Designing Virtualization-aware and Automatic Topology Detection Schemes for Accelerating Hadoop on SR-IOV-enabled Clouds, CloudCom’16, December 2016 0 2000 4000 6000 40 GB 60 GB 40 GB 60 GB 40 GB 60 GB EXECUTIONTIME Hadoop Benchmarks RDMA-Hadoop Hadoop-Virt 0 100 200 300 400 Default Mode Distributed Mode Default Mode Distributed Mode EXECUTIONTIME Hadoop Applications RDMA-Hadoop Hadoop-Virt CloudBurst Self-join Sort WordCount PageRank Reduced by 55% Reduced by 34%
- 68. Intel HPC Dev Conf (SC ‘16) 68Network Based Computing Laboratory • Upcoming Releases of RDMA-enhanced Packages will support – Upgrades to the latest versions of Hadoop and Spark – Streaming – MR-Advisor – Impala • Upcoming Releases of OSU HiBD Micro-Benchmarks (OHB) will support – MapReduce, RPC and Spark • Advanced designs with upper-level changes and optimizations – Boldio – Efficient Indexing On-going and Future Plans of OSU High Performance Big Data (HiBD) Project
- 69. Intel HPC Dev Conf (SC ‘16) 69Network Based Computing Laboratory • Discussed challenges in accelerating Big Data middleware with HPC technologies • Presented basic and advanced designs to take advantage of InfiniBand/RDMA for HDFS, MapReduce, RPC, HBase, Memcached, and Spark • Results are promising • Many other open issues need to be solved • Will enable Big Data community to take advantage of modern HPC technologies to carry out their analytics in a fast and scalable manner • Looking forward to collaboration with the community Concluding Remarks
- 70. Intel HPC Dev Conf (SC ‘16) 70Network Based Computing Laboratory Funding Acknowledgments Funding Support by Equipment Support by
- 71. Intel HPC Dev Conf (SC ‘16) 71Network Based Computing Laboratory Personnel Acknowledgments Current Students – A. Awan (Ph.D.) – M. Bayatpour (Ph.D.) – S. Chakraborthy (Ph.D.) – C.-H. Chu (Ph.D.) Past Students – A. Augustine (M.S.) – P. Balaji (Ph.D.) – S. Bhagvat (M.S.) – A. Bhat (M.S.) – D. Buntinas (Ph.D.) – L. Chai (Ph.D.) – B. Chandrasekharan (M.S.) – N. Dandapanthula (M.S.) – V. Dhanraj (M.S.) – T. Gangadharappa (M.S.) – K. Gopalakrishnan (M.S.) – R. Rajachandrasekar (Ph.D.) – G. Santhanaraman (Ph.D.) – A. Singh (Ph.D.) – J. Sridhar (M.S.) – S. Sur (Ph.D.) – H. Subramoni (Ph.D.) – K. Vaidyanathan (Ph.D.) – A. Vishnu (Ph.D.) – J. Wu (Ph.D.) – W. Yu (Ph.D.) Past Research Scientist – S. Sur Past Post-Docs – D. Banerjee – X. Besseron – H.-W. Jin – W. Huang (Ph.D.) – W. Jiang (M.S.) – J. Jose (Ph.D.) – S. Kini (M.S.) – M. Koop (Ph.D.) – K. Kulkarni (M.S.) – R. Kumar (M.S.) – S. Krishnamoorthy (M.S.) – K. Kandalla (Ph.D.) – P. Lai (M.S.) – J. Liu (Ph.D.) – M. Luo (Ph.D.) – A. Mamidala (Ph.D.) – G. Marsh (M.S.) – V. Meshram (M.S.) – A. Moody (M.S.) – S. Naravula (Ph.D.) – R. Noronha (Ph.D.) – X. Ouyang (Ph.D.) – S. Pai (M.S.) – S. Potluri (Ph.D.) – S. Guganani (Ph.D.) – J. Hashmi (Ph.D.) – N. Islam (Ph.D.) – M. Li (Ph.D.) – J. Lin – M. Luo – E. Mancini Current Research Scientists – K. Hamidouche – X. Lu – H. Subramoni Past Programmers – D. Bureddy – M. Arnold – J. Perkins Current Research Specialist – J. Smith – M. Rahman (Ph.D.) – D. Shankar (Ph.D.) – A. Venkatesh (Ph.D.) – J. Zhang (Ph.D.) – S. Marcarelli – J. Vienne – H. Wang
- 72. Intel HPC Dev Conf (SC ‘16) 72Network Based Computing Laboratory The 3rd International Workshop on High-Performance Big Data Computing (HPBDC) HPBDC 2017 will be held with IEEE International Parallel and Distributed Processing Symposium (IPDPS 2017), Orlando, Florida USA, May, 2017 Tentative Submission Deadline Abstract: January 10, 2017 Full Submission: January 17, 2017 HPBDC 2016 was held in conjunction with IPDPS’16 Keynote Talk: Dr. Chaitanya Baru, Senior Advisor for Data Science, National Science Foundation (NSF); Distinguished Scientist, San Diego Supercomputer Center (SDSC) Panel Moderator: Jianfeng Zhan (ICT/CAS) Panel Topic: Merge or Split: Mutual Influence between Big Data and HPC Techniques Six Regular Research Papers and Two Short Research Papers http://web.cse.ohio-state.edu/~luxi/hpbdc2016
- 73. Intel HPC Dev Conf (SC ‘16) 73Network Based Computing Laboratory • Three Conference Tutorials (IB+HSE, IB+HSE Advanced, Big Data) • HP-CAST • Technical Papers (SC main conference; Doctoral Showcase; Poster; PDSW- DISC, PAW, COMHPC, and ESPM2 Workshops) • Booth Presentations (Mellanox, NVIDIA, NRL, PGAS) • HPC Connection Workshop • Will be stationed at Ohio Supercomputer Center/OH-TECH Booth (#1107) – Multiple presentations and demos • More Details from http://mvapich.cse.ohio-state.edu/talks/ OSU Team Will be Participating in Multiple Events at SC ‘16
- 74. Intel HPC Dev Conf (SC ‘16) 74Network Based Computing Laboratory {panda, luxi}@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda http://www.cse.ohio-state.edu/~luxi Thank You! Network-Based Computing Laboratory http://nowlab.cse.ohio-state.edu/ The High-Performance Big Data Project http://hibd.cse.ohio-state.edu/