Exploratory Analysis in the Data Lab - Team-Sport or for Nerds only?
1 like867 views

Talk held at DOAG 2016 conference (2016.doag.org/de/home) discussing a data lab concept incl.architecture blueprint, collaboration and tool examples based on Oracle solutions like Oracle Big Data Discovery (in combination with Jupyter Notebook)





































































































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Exploratory Analysis in the Data Lab - Team-Sport or for Nerds only? (20)




















Ad
More from Harald Erb (12)












Recently uploaded (20)




















Exploratory Analysis in the Data Lab - Team-Sport or for Nerds only?
- 1. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Exploratory Analysis in the Data Lab Team-Sport or for Nerds only? Harald Erb Oracle Business Analytics & Big Data DOAG 2016 Konferenz, Nürnberg
- 2. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • Harald Erb • Principal Sales Consultant • Information Architect • Kontakt +49 (0)6103 397-403 • [email protected] Kontakt DOAG 2016 Konferenz, Nürnberg 2
- 3. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Characteristics of Digital Business Leaders DOAG 2016 Konferenz, Nürnberg 3 They ‘Reframe’ Challenges Looking at them from new perspectives and multiple angles They Sprint They work at pace - researching, testing and evaluating current ideas while generating new ones They Appreciate That Failure Can Be Good and are not afraid of new ideas They Convert Data Into Value They invest heavily in analyzing their own data and data from external sources to establish patterns and un-noticed opportunities
- 4. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Synergizing Skills 4 Perf. Mgmt. Knowledge Discovery Dynamic Dashboards and Reports Volume and Fixed Reporting Knowledge Driven Business Process Executive: Decisions effecting strategy and direction Business Analysts: Day-to-Day performance of a business unit Information Consumer: Reporting on individual transactions Automated Process: Decisions effecting execution of an indiv. transactions Insight Data Scientists: Information analysis to meet strategic goals BICC Analytical Competence Center (ACC) » Separate group reporting to CxO. not part of a Business Intelligence Competence Center (BICC) » Mission: broadening the adoption of Analytics across the organization » Skilled resource pool of Data Scientists, Statisticians and Business Experts » Data-driven approach (not development-driven) with privileged access to enterprise data sources » Group will be assigned to projects for a limited time ACC DOAG 2016 Konferenz, Nürnberg
- 5. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Enabling Data-driven Decisions 5 Identify(business)question Become clear about all aspects of the decision to be taken or the problem to be solved. Try to identify alternatives to your percep- tion Verifyearlierfindings Find out who has investi- gated such or a similar problem in the past and the approach that has been taken Designofasolutionmodel Formulate a detailled hypothesis how specific variables might influence the result of the chosen model Gatherallnecessarydata Analysethedata Present&implementresults Gather all available information about the variables of your hypo- thesis. The relevance of a dataset might address your business question directly or needs to be derived Apply a statistical model and evaluate the correctness of the approach. Repeat this procedure until the right method has been identified. Frame the results obtained in a compre- hensible story. This kind of presentation intends to motivate decision makers and relevant stake-holders to take action Non-Analysts & Executives: should take a closer look on steps 1 and 6 of the analysis process if they plan to make use of statistical analysis. DOAG 2016 Konferenz, Nürnberg Knowledge Discovery Adopted from Thomas H. Davenport, Harvard Business Manager 2013
- 6. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Projects: Process 6DOAG 2016 Konferenz, Nürnberg AdoptedfromHugenberg2011-S.168 Week Task Create Work Plan Hypothesis Business question Analysis Source Create Analysis Plan Structure Problem What? How? Hypothesis Yes No ? Why? Define Problem Fundamental business question to be solved: Problem area: Root of problem: Decision maker: Decision criteria: Boundaries of problem handling: Solution limitations: •Necessary information? •Available Information? Which quality? •Data owner? •Available data sets? •Business problem? •What is at issue? •What needs to be analyzed? •Precise goal definition •Deliminations •Useful data / structure? •Hypothesis definition •Verify correlations •Descriptive analysis •Data preparation •Select
- 7. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Lab: Key Requirements Based on Raw Data Full Access to Data Sources (Select only) Complete Sandbox Environment Agile Experimentation, Fail Fast 7DOAG 2016 Konferenz, Nürnberg
- 8. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Lab Scenario Sandbox Data Management DOAG 2016 Konferenz, Nürnberg 8
- 9. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Stages of Data Transformation Refinement of Raw Data DOAG 2016 Konferenz, Nürnberg Signal Data Information Knowledge Wisdom L0 - Ingestion L1 - Cleansed L2 - Normalised Accounts Parties Account Parties Party Addresses Party Contacts Party IDs Party Events Party Ratings Account Limits Party History Collaterals Account Collaterals Party Collaterals Account Balances Account Relations L3 – Presented Customer Dimension Account Dimension Currency Dimension Product Dimension Organization Dimension Calendar Dimension Account Daily Facts Account Transactions Transaction Types Channel Dimension CoA Dimension Company Dimension •Format/Domain checks •Completeness checks •Duplicates detection •Not null validations •Enrichment •Record level cleansing and business rules •Referential integrity •Context based business rules and quality checks •Aggregate level checks •Derived and enriched data for Self-service Business Intelligence •File validation •Row completeness •Raw Data Stores for Data Science Know nothing Know what Know how Know why Data WarehouseData Lake Source Systems Addressing a key requirement for Data Labs 9
- 10. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Management: Architecture (Logical View) DOAG 2016 Konferenz, Nürnberg 10 Line of Governance Data Lake Data Processing Data EnrichmentRaw Data Sets Curated & Transformed Data Sets Data Aggregation Data Lab Sandboxes Data Catalog Data Discovery Transformations Prototyping Analytic Tools Enterprise Information Store Operational Data Store Data Federation & Virtualization Layer CommonSQLAccessto ALLData Orchestration, Scheduling & Monitoring Metadata Management Data Ingestion Batch Integration Real-Time Integration Data Streaming Data Wrangling Reporting / Business Intelligence Data Driven Applications Advanced Analytics Non-structured Sources Logs Social Media External Data Interactions Structured Data Master Data Applications Channels Data Stores Adhoc Files or Relational Data Sets
- 11. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Management: Oracle Platform DOAG 2016 Konferenz, Nürnberg 11 Non-structured Sources Logs Social Media External Data Interactions Structured Data Master Data Applications Channels Data Stores Oracle Software Cloudera CDH 5.7+ / Apache Software Oracle Platform Oracle ExadataOracle Big Data Appliance Oracle Exalytics Oracle x86 Servers Orchestration, Scheduling & Monitoring Metadata Management Reporting / Business Intelligence Data Driven Applications Advanced Analytics
- 12. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Management: Functional Areas DOAG 2016 Konferenz, Nürnberg 12 Non-structured Sources Logs Social Media External Data Interactions Structured Data Master Data Applications Channels Data Stores Oracle Software Cloudera CDH 5.7+ / Apache Software Oracle Platform Orchestration, Scheduling & Monitoring Metadata Management Oracle ExadataOracle Big Data Appliance Data Ingestion Data Store Data Discovery & Analyze Unified Data Services Process Online Lifecycle/Governance Data Warehouse Reporting / Business Intelligence Data Driven Applications Advanced Analytics
- 13. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Management: Data Discovery & Analytics DOAG 2016 Konferenz, Nürnberg 13 Reporting / Business Intelligence Data Driven Applications Advanced Analytics Non-structured Sources Logs Social Media External Data Interactions Structured Data Master Data Applications Channels Data Stores Oracle Software Cloudera CDH 5.7+ / Apache Software Oracle Platform Oracle ExadataOracle Big Data Appliance Oracle GoldenGate for Big Data Flume & Kafka Oracle Data Integrator Oracle Stream Analytics Scoop Oracle NoSQL DB Kudu (Relational) Filesystem (HDFS) HBase (NoSQL) Oracle Data Integrator Batch (Map Reduce, Hive, Pig, Spark) Stream (Spark) HBase (NoSQL) WebHDFS, Fluentd, Storm, Tika .... Oracle Database Oracle SQL Database Security (Roles, View, VPD, …) Oracle Advanced Analytics Oracle Advanced Security In-Memory Data Ingestion Data Store Process Online Data WarehouseData Discovery & Analyze Security (Sentry+RecordService) ResourceManagement (Yarn) Unified Data Services Search (Solr) SQL (Impala) Model (Spark ML) Big Data Spatial & Graph Adv. Analytics for Hadoop Big Data Discovery Oracle Big Data SQL OracleBigData Connectors Cloudera Navigator Lifecycle/Governance Oracle Enterprise Metadata Management (OEMM) Oracle Data Factory Engine | Oracle Data Integrator | Oracle Enterprise Data Quality
- 14. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Lab Scenario Exploratory Analysis Oracle Big Data Discovery DOAG 2016 Konferenz, Nürnberg
- 15. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Activities Data Lab 15DOAG 2016 Konferenz, Nürnberg Download from: http://www.the-modeling-agency.com/crisp-dm.pdf Generic tasks (bold) and outputs (italic) CRISP-DM reference model
- 16. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Oracle Big Data Discovery 16 Know nothing Know what Know how Know why Signal Data Information Knowledge Wisdom (Operational) Business Intelligence (100…1000+ User) Data WarehouseData Lake L0 - Ingestion L1 - Cleansed L2 - Normalised Accounts Parties Account Parties Party Addresses Party Contacts Party IDs Party Events Party Ratings Account Limits Party History Collaterals Account Collaterals Party Collaterals Account Balances Account Relations L3 – Presented Customer Dimension Account Dimension Currency Dimension Product Dimension Organization Dimension Calendar Dimension Account Daily Facts Account Transactions Transaction Types Channel Dimension CoA Dimension Company Dimension Source Systems Oracle BI Plattform Common Enterprise Information Model Oracle BI Data Visualization Oracle BI Dashboards, (Ad-hoc) Reports, … Data Projects (1…20+ User) Oracle Data Visualization Desktop DOAG 2016 Konferenz, Nürnberg Oracle Big Data Discovery
- 17. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Team Sport: One tool for Business Analysts and Data Scientists Oracle Big Data Discovery 17 DWH / OLTP Databases Database Administrator (Enterprise IT) Hadoop Data Integration Specialist (Enterprise IT) Data Engineer Data Science Discovery Output Business Analyst New KPI, Report Requirement Data Scientist New Data Set (cleaned / enriched) Members of the same Data Project DOAG 2016 Konferenz, Nürnberg
- 18. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Analysis Scenario 1: Prototype Testing
- 19. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Analysis Scenario 1: Prototype Testing 1. A flexible environment to exploit all available data for prototype testing discovery 2. Can driver comments really add value to our prototype testing discovery? 3. What is the relationship between errors? Oracle Confidential – Internal/Restricted/Highly Restricted Telemetry 3 1 2 Errors Driver Comments Analysis & Dashboarding Discovery Lab 1.2 Billion rows at 100Hz Data Platform FactoryStorage
- 20. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | DOAG 2016 Konferenz, Nürnberg 20 Analysis Scenario 2: Investigate Car Complaints
- 21. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | DOAG 2016 Konferenz, Nürnberg 21 M I S S I O N Analysis Scenario 2: Investigate Car Complaints Help the Quality Team to trace back warranty claims and support issues to reduce warranty cost and minimize supplier risk, in order to improve product quality and customer satisfaction.
- 22. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Available Data DOAG 2016 Konferenz, Nürnberg 22 hadoop fs -cat /user/oracle/warranty/claims_full.txt | less Internal Data (Warranty Claims) Additional Data (i.e. demographics)
- 23. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Processing Workflow Oracle Big Data Discovery mit Daten versorgen 23 File Upload BDD Studio Big Data Discovery Data Proc. Client New Data Set in BDD Data Catalog
- 24. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | 24 1 2 5 43 Data Loading – Data Ingest Overview 1. Data ingest is triggered by data upload, the command line interface, or the Hive Table detector 2. Records are read and sampled into Spark 3. Data profiling occurs, to determine schema, search configuration and which enrichment apply 4. Auto enrichments are performed 5. Data is ingested into Big Data Discovery
- 25. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | About the Sampling technique 25DOAG 2016 Konferenz, Nürnberg • BDD leverages a Simple Random Sampling algorithm – Each individual is chosen randomly and entirely by chance with the same probability of being chosen at any stage during the sampling process. Each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals • Sampling is dependable – Accuracy is about the size of the sample, not the size of the source • A 1M random sample provides more than 99% confidence that the answer is within 0.2 % of the value shown, no matter how big the source dataset is (1B/1T/1Q+). • Sampling makes interactivity cheap – Will you pay 10, 100, 1000x the cost to get the last <<1% of the confidence? • Maybe sometimes, but not in discovery and not for every dataset
- 26. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Profiling & Enrichments 26DOAG 2016 Konferenz, Nürnberg • Profiling is a process that determines the characteristics (columns) in the Hive tables, for each source Hive table discovered by Big Data Discovery during data processing. – Attribute type determination (discovery) • Includes strings to dates, geocodes, long or boolean – Attribute value distributions – Determines attribute searchability – Provides “hints” to Studio as to what content (components) should be on the default Project page • Enrichments are derived from a data set's additional information such as terms, locations, the language used, sentiment, and views. Big Data Discovery determines which enrichments are useful for each discovered data set, and automatically runs them on samples of the data. As a result of automatically applied enrichments, additional derived metadata (columns) are added to the data set, such as geographic data, a suggestion of the detected language, or positive or negative sentiment.
- 27. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find 27 • A rich, interactive catalog of all data in Hadoop • Familiar search and guided navigation for ease of use • Data set summaries, user annotation and recommendations • Personal and enterprise data upload to Hadoop via self-service DOAG 2016 Konferenz, Nürnberg
- 28. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find 28 • A rich, interactive catalog of all data in Hadoop • Familiar search and guided navigation for ease of use • Data set summaries, user annotation and recommendations • Personal and enterprise data upload to Hadoop via self-service DOAG 2016 Konferenz, Nürnberg
- 29. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Like shopping online for your data Find – Data Sets Tab 29 Navigate • Project or Dataset – by Author and Tags • Contains – datetime or Geo • Number of records or attributes • Recently Viewed, Most Popular, Newly Added Data Quick Look • Data Set Info – Tags, Views, Last Updated – Project, used, created by • Actions – Explore, Add to project, Edit Tags, Delete • Related Data Sets by data source – “Often used with these data sets” • Preview – First 15 rows, all columns Search • Keyword • Data Sets • Projects • Data Set Metadata • Project Metadata • Recently Viewed, Most Popular, Newly Added DOAG 2016 Konferenz, Nürnberg
- 30. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find (Catalog) – Data Set Quick Look 30DOAG 2016 Konferenz, Nürnberg • Data Set Info – Tag • Actions – Explore – Add to project – Edit Tags – Delete • Summary – Views – Last Updated Data Set Info Quick Look
- 31. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find (Catalog) – Data Set Quick Look 31DOAG 2016 Konferenz, Nürnberg • Used in Projects – Project name – Data Sets used – Created by Data Set Used in Project Quick Look
- 32. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find (Catalog) – Navigation & Search 32DOAG 2016 Konferenz, Nürnberg • Searches – Keyword – Data Sets – Projects – Data Set Metadata – Project Metadata – Attribute Metadata Search Everything
- 33. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Like shopping online for your data Find – Projects Tab 33 Projects Tab • Search and navigate • Project Categories –Recently Viewed –Most Popular –View all Projects Quick Look • Add Tags, attributes, data sets, pages • Open Project, Edit Tags, Delete • Summary DOAG 2016 Konferenz, Nürnberg
- 34. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find (Catalog) - Projects Tab 34DOAG 2016 Konferenz, Nürnberg • Searchable • Navigable • Project Categories – Recently Viewed – Most Popular – View all Search Everything Discover Analytical Projects Navigate by Metadata
- 35. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Find (Catalog) - Project Quick Look • Add Tags • Attributes • Data Sets • Pages • Actions – Open Project – Edit Tags – Delete • Summary 35 Project Quick Look DOAG 2016 Konferenz, Nürnberg
- 36. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Explore 36 • Visualize all attributes by type • Sort attributes by information potential • Assess attribute statistics, data quality and outliers • Use scratch pad to uncover correlations between attributes DOAG 2016 Konferenz, Nürnberg
- 37. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Quicklook by Geocode • Overview • Details • Summary stats • Refineable Explore Scratchpad • Graphic type changes as additional attributes are added • Autoselects best visualization • Offers next best graphics option(s) Intuitive, machine-guided data exploration Search, Navigate, Sort • Attributes, refinements, keyword • Sort by: – Name (alpha) – Information Potential – Relationship to an attribute 37DOAG 2016 Konferenz, Nürnberg
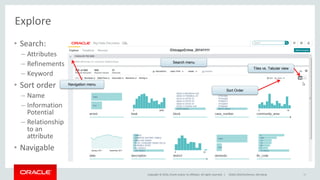
- 38. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Explore • Search: – Attributes – Refinements – Keyword • Sort order – Name – Information Potential – Relationship to an attribute • Navigable 38 Tiles vs. Tabular view Navigation menu Search menu Sort Order DOAG 2016 Konferenz, Nürnberg
- 39. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Explore – Sort Attributes • Sort order – Name (alpha) – Information Potential • Based on Entropy – Relationship to an attribute • Based on Information Gain 39 Sort by DOAG 2016 Konferenz, Nürnberg
- 40. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Core Capabilities: Explore – Quick Look –Geocode • Overview • Details • Summary stats – Refineable 40DOAG 2016 Konferenz, Nürnberg
- 41. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Explore – Scratchpad • Graphic type changes as additional attributes are added • Autoselects best visualization • Offers next best graphics option(s) 41DOAG 2016 Konferenz, Nürnberg
- 42. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Document all relevant information and insights about the original data sources Working with Metadata DOAG 2016 Konferenz, Nürnberg 42 Available Code Books, Data Set specifications Document all relevant information, insights directly in BDD Studio... ... and make immediately use of it, i.e. via text search in BDD
- 43. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | 43 • Intuitive, user driven data wrangling • Data Shaping • Extensive library of powerful data transformations and enrichments • Preview results, undo, commit and replay transforms • Test on sample data then apply to full data set in Hadoop Transform - Overview DOAG 2016 Konferenz, Nürnberg
- 44. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | 44 Transform – Function Families Available via a User Guided Interface DOAG 2016 Konferenz, Nürnberg
- 45. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Full Guided Navigation Attribute Transformation Smart Attribute Filtering Interactive Transform History Visual Data Quality Summaries 45 Data Shaping TAB Aggregation, Join, etc. Transform - Overview DOAG 2016 Konferenz, Nürnberg
- 46. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • Uses Groovy - an object-oriented programming language for the Java platform. – Code written in the Java language is valid in Groovy – It is flexible and easy to use. • Features of the Editor include: 46 – Syntax highlighting enables color-coding of different elements in your transformation to indicate their type. – Auto complete lets you view a list of autocomplete suggestions for the word you're typing, by pressing Ctrl+space. – Error checking includes a built-in static parser that performs error checking when you preview or save your transformation. Transform Editor Available via a User Guided Interface DOAG 2016 Konferenz, Nürnberg
- 47. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Enrichments • Infer language • Detect sentiment • Identify key phrases, entities, noun groups • Whitelist tagger • Address and IP geotagger Function Families • String • Mathematical • Conversion • Conditional • Datetime • Data cleansing • Geotagging User-driven data wrangling Commit, Create Data Set • Commit – Execute transformations on sample data available in the app – this updates the original collection in the Dgraph. • Create a Data Set – Executes transformation on the entire data set in HDFS, creating a new entry in the BDD Catalog & Hive. • Rollback – Attributes created by a transformation, then deleted, will be removed on Commit. 47 Data Shaping • Aggregate • Persistent Join • Row Filter Transform - Overview DOAG 2016 Konferenz, Nürnberg
- 48. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • Geo Tagging – Partial Address match – Address disambiguation (based on population) – IPv4 support • Numeric Transformation – Round, Ceiling, Floor, Absolute Value – Operators (+ - / *), sqrt, mod, log, ln, min/max, sin/asin/sinh, cos/acos/cosh, tan/atan/tanh • String – Split, Trim, Uppercase, Lowercase, Titlecase, Concatenate • Type Conversion – Boolean, Datetime, Double, Integer, String, Long, Time, Geocode • Datetime (accessed via Transformation Editor) – Date Diff, Date Add, getYear, Month, Day, Hour, Minute – Truncate Date • Data Cleansing – Binning numerics • Conditional – Accessed via Transformation Editor • If /else if statement – Optionally based on refinement state – Can be nested • Drag/drop or double-click functions and attributes onto editor 48 Transform – Function Families Transformation Functions DOAG 2016 Konferenz, Nürnberg
- 49. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • In addition to transforming data, Big Data Discovery allows for users to enrich data sets in numerous ways: • Term Extraction – Extract relevant phrases and noun groups from unstructured text • Entity Recognition – Find people, places and organizations mentioned in unstructured text • Sentiment Analysis – Determine the document and sub-document level sentiment of unstructured text • Geo Tagging – Generate standardized geographic information based on an unstructured address or IP address • Language Detection • Applied via User Guided Interface 49 Transform – Function Families Enrichment Functions DOAG 2016 Konferenz, Nürnberg
- 50. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Windows Metro Driver Issues Usb Port Light Gaming Gaming Laptop Key Phrases Document Sentiment Detected Language • I was looking for a laptop mainly to browse and for mult imedia purpose and found this inexpensive built-like-a-t ank Dell XPS 14. I am very impressed with the build qua lity, stunning looks and there is absolutely a very nice fe el to it. I have many MBPs at home and this one is bette r in appearance and worked out of the box with minima l set up. I was up and running in 10 minutes or so. • I found the touch pad not up to par with Apple track pa d but with the latest driver update it came pretty close. I uninstalled the McAfee software and went with Norto n security as it comes free with Comcast. There is a new BIOS update from February 2014 and also audio driver update that you may want to apply immediately. Do the Wifi-BT update as well. en POSITIVE 50 Transform – Function Families Text Enrichments DOAG 2016 Konferenz, Nürnberg
- 51. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Extract Key Phrases from Freetext Text Enrichment DOAG 2016 Konferenz, Nürnberg 51
- 52. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Determine sentiment and extract related phrases Text Enrichment DOAG 2016 Konferenz, Nürnberg 52
- 53. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • Partial Address match • Address disambiguation (based on population) • IPv4 support 53 Input: west loop chicago Input: 148.87.19.206 city Chicago country US county Cook County geocode 41.85003 -87.65005 latitude 41.85003 longitude -87.65005 population 2695598 state Illinois city Redwood City country US geocode 37.4852 -122.2364 latitude 37.4852 longitude -122.2364 state California Transform – Function Families Geo-Tagging Enrichments DOAG 2016 Konferenz, Nürnberg
- 54. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | One goal of all the ETL work: Linking Data Sets via Joins Combining Data Sets DOAG 2016 Konferenz, Nürnberg 54
- 55. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | 55 • Join and blend data for deeper perspectives • Compose project pages via drag and drop • Use powerful search and guided navigation to ask questions • See new patterns in rich, interactive data visualizations Discover DOAG 2016 Konferenz, Nürnberg
- 56. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Discovery Dashboards • Control over layout, filtering, exposed dimensions/metrics • Formatting controls – Is Dimension, available aggregations, multi- OR/And, Include in Available Refinements – Component level: currency, # of decimals, date format, etc. • Data set linking: 2 or more data sets within a project, visual attribute linking • Automatic view creation and widening of data sets Discover Drag-and-drop dashboards for fast , easy analysis Navigation • Intelligent refine using any combination of data elements • Color highlighting • Alternate counts for metrics • Linked navigation across data sets Visualizations • New visualizations – D3 Chart library – More intuitive interface – Seamless integration of new visualization components (Custom Visualization Component extension) 56DOAG 2016 Konferenz, Nürnberg
- 57. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Rich and highly interactive Library of Visualization Portlets Oracle Big Data Discovery 57DOAG 2016 Konferenz, Nürnberg
- 58. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Lab Scenario Advanced Analytics BDD Shell Jupyter Notebook DOAG 2016 Konferenz, Nürnberg 58
- 59. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Scientist continues with Machine Learning tasks Oracle Big Data Discovery 59 DWH / OLTP Databases Database Administrator (Enterprise IT) Hadoop Data Integration Specialist (Enterprise IT) Data Engineer Data Science Discovery Output Business Analyst New KPI, Report Requirement Data Scientist New Data Set (cleaned / enriched) DOAG 2016 Konferenz, Nürnberg
- 60. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Handling of sparse Data / NULL values Shaping a Data Set for further processing DOAG 2016 Konferenz, Nürnberg 60
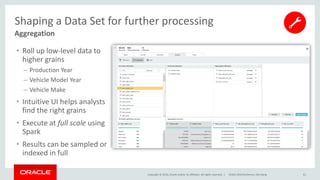
- 61. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Aggregation Shaping a Data Set for further processing DOAG 2016 Konferenz, Nürnberg 61 • Roll up low-level data to higher grains – Production Year – Vehicle Model Year – Vehicle Make • Intuitive UI helps analysts find the right grains • Execute at full scale using Spark • Results can be sampled or indexed in full
- 62. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Combining multiple Data Sets Shaping a Data Set for further processing DOAG 2016 Konferenz, Nürnberg 62 • Blend huge datasets in BDD – UI to support experimentation, preview – Execute at scale with Spark • Results can be sampled or indexed in full
- 63. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Export new Data Set Hive Table in Hadoop Shaping a Data Set for further processing DOAG 2016 Konferenz, Nürnberg 63
- 64. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Data Density, Validation of attribute correlations Analytic features in Oracle Big Data Discovery 64DOAG 2016 Konferenz, Nürnberg Scatter Plot Scatter Plot Matrix
- 65. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • Python-based shell • Exposes all BDD data objects • Easy-to-use Python Wrappers for BDD APIs and Python Utilities • Use of Third-party Libraries, e.g., Pandas and NumPy BDD-Shell interface Point of Contact with Data Scientists • BDD Shell is an interactive tool designed to work with BDD without using Studio's front-end • Provides a way to explore and manipulate the internals of BDD and interact with Hadoop 66DOAG 2016 Konferenz, Nürnberg
- 66. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | (Re-)use data from Oracle Big Data Discovery while working with the BDD Shell Data Analysis with Python DOAG 2016 Konferenz, Nürnberg 67 List of Oracle Big Data Discovery Data Sets Import Spark Machine Learning library MLlib Converting a Oracle Big Data Discovery Data Set into an Apache Spark Dataframe Import Package NumPy (Numerical Python)
- 67. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | • Easiest way to use the BDD-Shell – Visual appeal, ease of use, collaboration features of an integrated platform – Power and flexibility of custom code – Pick up BDD’s datasets and leverage Machine Learning algorithms to infer new insight 68 Leveraging Notebooks for a better user experience Point of Contact with Data Scientists
- 68. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | 69DOAG 2016 Konferenz, Nürnberg www.jupyter.org
- 69. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | (Re-)use data from Oracle Big Data Discovery while working with Jupyter Data Analysis with Python 70DOAG 2016 Konferenz, Nürnberg
- 70. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Explorative Datenanalyse im Data Lab... ...besser/nachhaltiger im interdisziplinären Team! DOAG 2016 Konferenz, Nürnberg 71
- 71. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | Supporting agile data experiments and data projects Oracle’s Unified Big Data Management & Analytics Strategy 72DOAG 2016 Konferenz, Nürnberg Experiment • Big Data Discovery • R on Hadoop • Spatial and Graph for Hadoop In der Cloud und On-premises Aggregate • Big Data Preparation • Data Integrator • GoldenGate • IoT connect people to the information they need Manage • Hadoop Platform • Big Data SQL • NoSQL Database • Oracle Database collect, secure and make data available innovation through experimentation with data Analyze & act • Data Visualization • Business Intelligence • Spatial and Graph • Advanced Analytics transform the workplace with actionable insights
- 72. Copyright © 2016, Oracle and/or its affiliates. All rights reserved. | 73DOAG 2016 Konferenz, Nürnberg