Faceting optimizations for Solr
Download as PPT, PDF•0 likes•1,023 views

The document discusses faceting optimizations for Solr, particularly in the context of the State and University Library of Denmark, which handles a massive index of web documents. Key topics include the architecture for indexing, performance improvements through techniques like counter reuse and tracking, and distributed faceting methods. The author details setup configurations, benchmarks, and provides insights into handling large datasets efficiently.







![8/55
String faceting 101 (single shard)
counter = new int[ordinals]
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
for entry: priorityQueue
result.add(resolveTerm(ordinal), count)
ord term counter
0 A 0
1 B 3
2 C 0
3 D 1006
4 E 1
5 F 1
6 G 0
7 H 0
8 I 3](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-8-320.jpg)



![12/55
Reuse the counter
counter = new int[ordinals]
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
<counter no more referenced and will be garbage collected at some point>](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-12-320.jpg)
![13/55
Reuse the counter
counter = pool.getCounter()
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
pool.release(counter)
Note: The JSON Facet API in Solr 5 already supports reuse of counters](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-13-320.jpg)



![18/55
Iteration is not free
counter = pool.getCounter()
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
counter[ordinal]++
for ordinal = 0 ; ordinal < counters.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
pool.release(counter)
200M unique terms = 800MB](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-18-320.jpg)

![20/55
ord counter
0 0
1 0
2 0
3 1
4 0
5 0
6 0
7 0
8 0
tracker
3
N/A
N/A
N/A
N/A
N/A
N/A
N/A
N/A
counter[3]++
Tracking updated counters](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-20-320.jpg)
![21/55
ord counter
0 0
1 1
2 0
3 1
4 0
5 0
6 0
7 0
8 0
tracker
3
1
N/A
N/A
N/A
N/A
N/A
N/A
N/A
counter[3]++
counter[1]++
Tracking updated counters](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-21-320.jpg)
![22/55
ord counter
0 0
1 3
2 0
3 1
4 0
5 0
6 0
7 0
8 0
tracker
3
1
N/A
N/A
N/A
N/A
N/A
N/A
N/A
counter[3]++
counter[1]++
counter[1]++
counter[1]++
Tracking updated counters](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-22-320.jpg)
![23/55
ord counter
0 0
1 3
2 0
3 1006
4 1
5 1
6 0
7 0
8 3
tracker
3
1
8
4
5
N/A
N/A
N/A
N/A
counter[3]++
counter[1]++
counter[1]++
counter[1]++
counter[8]++
counter[8]++
counter[4]++
counter[8]++
counter[5]++
counter[1]++
counter[1]++
…
counter[1]++
Tracking updated counters](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-23-320.jpg)
![24/55
Tracking updated counters
counter = pool.getCounter()
for docID: result.getDocIDs()
for ordinal: getOrdinals(docID)
if counter[ordinal]++ == 0 && tracked < maxTracked
tracker[tracked++] = ordinal
if tracked < maxTracked
for i = 0 ; i < tracked ; i++
priorityQueue.add(tracker[i], counter[tracker[i]])
else
for ordinal = 0 ; ordinal < counter.length ; ordinal++
priorityQueue.add(ordinal, counter[ordinal])
ord counter
0 0
1 3
2 0
3 1006
4 1
5 1
6 0
7 0
8 3
tracker
3
1
8
4
5
N/A
N/A
N/A
N/A](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-24-320.jpg)















![40/55
int vs. PackedInts
domain: 4 MB
url: 780 MB
links: 2350 MB
int[ordinals] PackedInts(ordinals, maxBPV)
domain: 3 MB (72%)
url: 420 MB (53%)
links: 1760 MB (75%)](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-40-320.jpg)






![47/55
Comparison of counter structures
domain: 4 MB
url: 780 MB
links: 2350 MB
domain: 3 MB (72%)
url: 420 MB (53%)
links: 1760 MB (75%)
domain: 1 MB (30%)
url: 66 MB ( 8%)
links: 311 MB (13%)
int[ordinals] PackedInts(ordinals, maxBPV) n-plane-z](https://image.slidesharecdn.com/rev2015facetingperformancetokeeskildsen20151013withextras-151019074321-lva1-app6891/85/Faceting-optimizations-for-Solr-47-320.jpg)











Faceting optimizations for Solr
- 1. OCTOBER 13-16, 2015 • AUSTIN, TX
- 2. Faceting optimizations for Solr Toke Eskildsen Search Engineer / Solr Hacker State and University Library, Denmark @TokeEskildsen / [email protected]
- 3. 3 3/55 Overview Web scale at the State and University Library, Denmark Field faceting 101 Optimizations − Reuse − Tracking − Caching − Alternative counters
- 4. 4/55 Web scale for a small web Denmark − Consolidation circa 10th century − 5.6 million people Danish Net Archive (http://netarkivet.dk) − Constitution 2005 − 20 billion items / 590TB+ raw data
- 5. 5/55 Indexing 20 billion web items / 590TB into Solr Solr index size is 1/9th of real data = 70TB Each shard holds 200M documents / 900GB − Shards build chronologically by dedicated machine − Projected 80 shards − Current build time per shard: 4 days − Total build time is 20 CPU-core years − So far only 7.4 billion documents / 27TB in index
- 6. 6/55 Searching a 7.4 billion documents / 27TB Solr index SolrCloud with 2 machines, each having − 16 HT-cores, 256GB RAM, 25 * 930GB SSD − 25 shards @ 900GB − 1 Solr/shard/SSD, Xmx=8g, Solr 4.10 − Disk cache 100GB or < 1% of index size
- 7. 7/55
- 8. 8/55 String faceting 101 (single shard) counter = new int[ordinals] for docID: result.getDocIDs() for ordinal: getOrdinals(docID) counter[ordinal]++ for ordinal = 0 ; ordinal < counters.length ; ordinal++ priorityQueue.add(ordinal, counter[ordinal]) for entry: priorityQueue result.add(resolveTerm(ordinal), count) ord term counter 0 A 0 1 B 3 2 C 0 3 D 1006 4 E 1 5 F 1 6 G 0 7 H 0 8 I 3
- 9. 9/55 Test setup 1 (easy start) Solr setup − 16 HT-cores, 256GB RAM, SSD − Single shard 250M documents / 900GB URL field − Single String value − 200M unique terms 3 concurrent “users” Random search terms
- 10. 10/55 Vanilla Solr, single shard, 250M documents, 200M values, 3 users
- 11. 11/55 Allocating and dereferencing 800MB arrays
- 12. 12/55 Reuse the counter counter = new int[ordinals] for docID: result.getDocIDs() for ordinal: getOrdinals(docID) counter[ordinal]++ for ordinal = 0 ; ordinal < counters.length ; ordinal++ priorityQueue.add(ordinal, counter[ordinal]) <counter no more referenced and will be garbage collected at some point>
- 13. 13/55 Reuse the counter counter = pool.getCounter() for docID: result.getDocIDs() for ordinal: getOrdinals(docID) counter[ordinal]++ for ordinal = 0 ; ordinal < counters.length ; ordinal++ priorityQueue.add(ordinal, counter[ordinal]) pool.release(counter) Note: The JSON Facet API in Solr 5 already supports reuse of counters
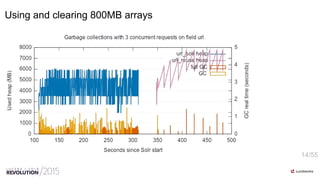
- 14. 14/55 Using and clearing 800MB arrays
- 15. 15/55 Reusing counters vs. not doing so
- 16. 16/55 Reusing counters, now with readable visualization
- 17. 17/55 Reusing counters, now with readable visualization Why does it always take more than 500ms?
- 18. 18/55 Iteration is not free counter = pool.getCounter() for docID: result.getDocIDs() for ordinal: getOrdinals(docID) counter[ordinal]++ for ordinal = 0 ; ordinal < counters.length ; ordinal++ priorityQueue.add(ordinal, counter[ordinal]) pool.release(counter) 200M unique terms = 800MB
- 19. 19/55 ord counter 0 0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 tracker N/A N/A N/A N/A N/A N/A N/A N/A N/A Tracking updated counters
- 20. 20/55 ord counter 0 0 1 0 2 0 3 1 4 0 5 0 6 0 7 0 8 0 tracker 3 N/A N/A N/A N/A N/A N/A N/A N/A counter[3]++ Tracking updated counters
- 21. 21/55 ord counter 0 0 1 1 2 0 3 1 4 0 5 0 6 0 7 0 8 0 tracker 3 1 N/A N/A N/A N/A N/A N/A N/A counter[3]++ counter[1]++ Tracking updated counters
- 22. 22/55 ord counter 0 0 1 3 2 0 3 1 4 0 5 0 6 0 7 0 8 0 tracker 3 1 N/A N/A N/A N/A N/A N/A N/A counter[3]++ counter[1]++ counter[1]++ counter[1]++ Tracking updated counters
- 23. 23/55 ord counter 0 0 1 3 2 0 3 1006 4 1 5 1 6 0 7 0 8 3 tracker 3 1 8 4 5 N/A N/A N/A N/A counter[3]++ counter[1]++ counter[1]++ counter[1]++ counter[8]++ counter[8]++ counter[4]++ counter[8]++ counter[5]++ counter[1]++ counter[1]++ … counter[1]++ Tracking updated counters
- 24. 24/55 Tracking updated counters counter = pool.getCounter() for docID: result.getDocIDs() for ordinal: getOrdinals(docID) if counter[ordinal]++ == 0 && tracked < maxTracked tracker[tracked++] = ordinal if tracked < maxTracked for i = 0 ; i < tracked ; i++ priorityQueue.add(tracker[i], counter[tracker[i]]) else for ordinal = 0 ; ordinal < counter.length ; ordinal++ priorityQueue.add(ordinal, counter[ordinal]) ord counter 0 0 1 3 2 0 3 1006 4 1 5 1 6 0 7 0 8 3 tracker 3 1 8 4 5 N/A N/A N/A N/A
- 26. 26/55 Distributed faceting Phase 1) All shards performs faceting. The Merger calculates the top-X terms. Phase 2) The term counts are requested from the shards that did not return them in phase 1. The Merger calculates the final counts for the top-X terms. for term: fineCountRequest.getTerms() result.add(term, searcher.numDocs(query(field:term), base.getDocIDs()))
- 27. 27/55 Test setup 2 (more shards, smaller field) Solr setup − 16 HT-cores, 256GB RAM, SSD − 9 shards @ 250M documents / 900GB domain field − Single String value − 1.1M unique terms per shard 1 concurrent “user” Random search terms
- 28. 28/55 Pit of Pain™ (or maybe “Horrible Hill”?)
- 29. 29/55 Fine counting can be slow Phase 1: Standard faceting Phase 2: for term: fineCountRequest.getTerms() result.add(term, searcher.numDocs(query(field:term), base.getDocIDs()))
- 30. 30/55 Alternative fine counting counter = pool.getCounter() for docID: result.getDocIDs() for ordinal: getOrdinals(docID) counter.increment(ordinal) for term: fineCountRequest.getTerms() result.add(term, counter.get(getOrdinal(term))) }Same as phase 1, which yields ord counter 0 0 1 3 2 0 3 1006 4 1 5 1 6 0 7 0 8 3
- 31. 31/55 Using cached counters from phase 1 in phase 2 counter = pool.getCounter(key) for term: query.getTerms() result.add(term, counter.get(getOrdinal(term))) pool.release(counter)
- 32. 32/55 Pit of Pain™ practically eliminated
- 33. 33/55 Pit of Pain™ practically eliminated Stick figure CC BY-NC 2.5 Randall Munroe xkcd.com
- 34. 34/55 Test setup 3 (more shards, more fields) Solr setup − 16 HT-cores, 256GB RAM, SSD − 23 shards @ 250M documents / 900GB Faceting on 6 fields − url: ~200M unique terms / shard − domain & host: ~1M unique terms each / shard − type, suffix, year: < 1000 unique terms / shard
- 35. 35/55 1 machine, 7 billion documents / 23TB total index, 6 facet fields
- 36. 36/55 High-cardinality can mean different things Single shard / 250,000,000 docs / 900GB Field References Max docs/term Unique terms domain 250,000,000 3,000,000 1,100,000 url 250,000,000 56,000 200,000,000 links 5,800,000,000 5,000,000 610,000,000 2440 MB / counter
- 37. 37/55 Remember: 1 machine = 25 shards 25 shards / 7 billion / 23TB Field References Max docs/term Unique terms domain 7,000,000,000 3,000,000 ~25,000,000 url 7,000,000,000 56,000 ~5,000,000,000 links 125,000,000,000 5,000,000 ~15,000,000,000 60 GB / facet call
- 38. 38/55 Different distributions domain 1.1M url 200M links 600M High max Low max Very long tail Short tail
- 39. 39/55 Theoretical lower limit per counter: log2(max_count) max=1 max=7 max=2047 max=3 max=63
- 40. 40/55 int vs. PackedInts domain: 4 MB url: 780 MB links: 2350 MB int[ordinals] PackedInts(ordinals, maxBPV) domain: 3 MB (72%) url: 420 MB (53%) links: 1760 MB (75%)
- 41. 41/55 n-plane-z counters Platonic ideal Harsh reality Plane d Plane c Plane b Plane a
- 42. 42/55 Plane d Plane c Plane b Plane a L: 0 ≣ 000000
- 43. 43/55 Plane d Plane c Plane b Plane a L: 0 ≣ 000000 L: 1 ≣ 000001
- 44. 44/55 Plane d Plane c Plane b Plane a L: 0 ≣ 000000 L: 1 ≣ 000001 L: 2 ≣ 000011
- 45. 45/55 Plane d Plane c Plane b Plane a L: 0 ≣ 000000 L: 1 ≣ 000001 L: 2 ≣ 000011 L: 3 ≣ 000101
- 46. 46/55 Plane d Plane c Plane b Plane a L: 0 ≣ 000000 L: 1 ≣ 000001 L: 2 ≣ 000011 L: 3 ≣ 000101 L: 4 ≣ 000111 L: 5 ≣ 001001 L: 6 ≣ 001011 L: 7 ≣ 001101 ... L: 12 ≣ 010111
- 47. 47/55 Comparison of counter structures domain: 4 MB url: 780 MB links: 2350 MB domain: 3 MB (72%) url: 420 MB (53%) links: 1760 MB (75%) domain: 1 MB (30%) url: 66 MB ( 8%) links: 311 MB (13%) int[ordinals] PackedInts(ordinals, maxBPV) n-plane-z
- 49. 49/55 I could go on about Threaded counting Heuristic faceting Fine count skipping Counter capping Monotonically increasing tracker for n-plane-z Regexp filtering
- 50. 50/55 What about huge result sets? Rare for explorative term-based searches Common for batch extractions Threading works poorly as #shards > #CPUs But how bad is it really?
- 51. 51/55 Really bad! 8 minutes
- 52. 52/55 Heuristic faceting Use sampling to guess top-X terms − Re-use the existing tracked counters − 1:1000 sampling seems usable for the field links, which has 5 billion references per shard Fine-count the guessed terms
- 53. 53/55 Over provisioning helps validity
- 54. 54/55 10 seconds < 8 minutes
- 55. 55/55 Never enough time, but talk to me about Threaded counting Monotonically increasing tracker for n-plane-z Regexp filtering Fine count skipping Counter capping
- 56. 56/55 Extra info The techniques presented can be tested with sparse faceting, available as a plug-in replacement WAR for Solr 4.10 at https://tokee.github.io/lucene-solr/. A version for Solr 5 will eventually be implemented, but the timeframe is unknown. No current plans for incorporating the full feature set in the official Solr distribution exists. Suggested approach for incorporation is to split it into multiple independent or semi- independent features, starting with those applicable to most people, such as the distributes faceting fine count optimization. In-depth descriptions and performance tests of the different features can be found at https://sbdevel.wordpress.com.
- 57. 57/55 18M documents / 50GB, facet on 5 fields (2*10M values, 3*smaller)
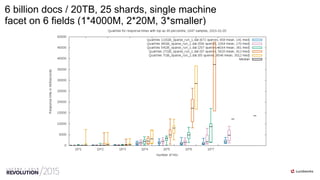
- 58. 58/55 6 billion docs / 20TB, 25 shards, single machine facet on 6 fields (1*4000M, 2*20M, 3*smaller)
- 59. 59/55 7 billion docs / 23TB, 25 shards, single machine facet on 5 fields (2*20M, 3*smaller)
Editor's Notes
- #6: “Solr at Scale for Time-Oriented data, Rocana” covers just about all, just nicer. Tika is the heavy part: 90% of indexing CPU power goes into Tika analysis .
- #7: Static & optimized shards No replicas (but we do have backup) Rarely more than 1 concurrent user
- #12: Standard JRE 1.7 garbage collector – no tuning. Full GC means delay for the client. Standard GC means higher CPU load.
- #14: Some info on JSON Faceting API and reusing at http://yonik.com/facet-performance/ The pool is responsible for cleaning the counter Counter cleaning is a background thread NOTE: Was I wrong about JSON faceting reuse?
- #17: Note: It always takes at least 500ms in this test
- #18: Note: It always takes at least 500ms in this test
- #36: This scenario represents the highest faceting feature set we are currently willing to run on our net search. Fortunately the standard scenario is that more than 1 concurrent search is rare. Our established upper acceptable response time is 2 seconds (median), with no defined worst-case limit.
- #38: Faceting on the links field requires 60GB of heap per concurrent call. While this might be technically feasible for our setup, it would leave very little memory available for disk cache.
- #40: Not the true minimum, as we round up to nearest power of 2 minus 1
- #42: Blue squares are overflow bits. Finding the index for the term in a higher plane is done by counting the number of overflow bits. Fortunately this can be done with a rank function (~3% memory overhead) in constant time. The standard tracker is not used, as it would require more heap than the counter structure itself. Instead a bitmap counter structure is used (1/64 overhead). Details about this counter structure is not part of this presentation.
- #48: n-plane-z uses a little less than 2x theoretical min Multiple n-plane-z shares overflow-bits, so extra concurrent counters takes up only slightly more than the theoretical minimum amount of heap.
- #53: Fine counting could be replaced with multiplication with 1/sampling_factor
- #54: We want top-25, but ask for top-100 to raise the chances of getting the right terms Counts are guaranteed to be correct
- #58: Bonus slide 1 Graphs from production core library search (books, articles etc) logs. Logs are taken from same week day, for 4 weeks. Blue, pink and green are response times with vanilla Solr. Orange is with sparse faceting.
- #59: Bonus slide: The effect of artificially reducing the amount of memory available for disk caching. Reducing this below 50GB has severe performance implications. Morale: SSD allows for very low relative disk cache, but do not count on the performance relative to disk cache to be linear.
- #60: Bonus slide. Performance of search with multiple concurrent users. Note that the large URL field is not part of faceting. This slide demonstrates performance for a more “normal” search situation on a machine with a relative small amount of disk cache.