Feature Selection with R / in JP
Download as PPTX, PDF33 likes102,023 views

7 R packages that might be helpful in selecting important features. Slides are in Japanese.
















![18
my.seed <- 12345
set.seed(my.seed) # seedを設定
n_var <- 20 # 特徴量の数
n_obs <- 6000 # 観測データの数
Sigma <- matrix(0, nrow = n_var, ncol = n_var) # 適当な分散共分散行列を作る
# 最初の5個の特徴量の間の相関を高めにし、他の特徴量の間で相関がないことにする
Sigma[1:5, 1:5] <- 0.9
diag(Sigma) <- 1
A <- mvrnorm(n = n_obs, rep(0, n_var), Sigma) # 多次元正規分布に従って適当な値を作る
eps <- rnorm(n_obs, mean = 0, sd = 0.5) # 正規分布に従って1次元の適当な値を作る
# 各説明変数と目的変数の関係の重みを決める
w <- rep(0, n_var); w[c(3, 5, 10, 15, 16, 20)] <- c(5, 5, 2, -5, -5, -4)
# 0/1の目的変数を作る
Y <- A %*% w + eps
Y <- ifelse(Y < 0, 0, 1)
my.data <- as.data.frame(cbind(A, Y))
names(my.data)[1:5] <- paste("CORR_VAR", 1:5, sep = "")
names(my.data)[n_var+1] <- "LABEL"
my.data$LABEL <- factor(my.data$LABEL)
# データに目的変数と関係のない説明変数を加える
my.data$MANY_CTG <- factor( rep(1:30, each = n_obs/30) )
my.data$FEWER_CTG <- factor( rep(1:10, each = n_obs/10) )
require(randomForest)
シミュレーション](https://image.slidesharecdn.com/taha20140329featureselection-140328213046-phpapp01/85/Feature-Selection-with-R-in-JP-18-320.jpg)
![19
# Random Forestを作る
set.seed(my.seed)
model <- randomForest(LABEL ~ ., data = my.data, ntree = 51, importance = T, scale = F)
# 特徴量の重要度を確認する
require(data.table)
# 1: 予測精度の平均低下による重要度
imp1 <- importance(model, type = 1)[, 1]
imp1 <- data.table(Feature = names(imp1), RealWeight = c(w, 0, 0), MeanDecreaseAccuracy = imp1)
imp1 <- imp1[order(-MeanDecreaseAccuracy)]
# 2: ジニ不純度の平均低下による重要度
imp2 <- importance(model, type = 2)[, 1]
imp2 <- data.table(Feature = names(imp2), RealWeight = c(w, 0, 0), MeanDecreaseGini = imp2)
imp2 <- imp2[order(-MeanDecreaseGini)]
require(randomForest)
シミュレーション](https://image.slidesharecdn.com/taha20140329featureselection-140328213046-phpapp01/85/Feature-Selection-with-R-in-JP-19-320.jpg)



![23
my.seed <- 12345
set.seed(my.seed) # seedを設定
n_var <- 20 # 特徴量の数
n_obs <- 480 # 観測データの数
Sigma <- matrix(0, nrow = n_var, ncol = n_var) # 適当な分散共分散行列を作る
# 最初の5個の特徴量の間の相関を高めにし、他の特徴量の間で相関がないことにする
Sigma[1:5, 1:5] <- 0.9
diag(Sigma) <- 1
A <- mvrnorm(n = n_obs, rep(0, n_var), Sigma) # 多次元正規分布に従って適当な値を作る
eps <- rnorm(n_obs, mean = 0, sd = 0.5) # 正規分布に従って1次元の適当な値を作る
# 各説明変数と目的変数の関係の重みを決める
w <- rep(0, n_var); w[c(3, 5, 10, 15, 16, 20)] <- c(5, 5, 2, -5, -5, -4)
# 0か1の目的変数を作る
Y <- A %*% w + eps
Y <- ifelse(Y < 0, 0, 1)
my.data <- as.data.frame(cbind(A, Y))
names(my.data)[1:5] <- paste("CORR_VAR", 1:5, sep = "")
names(my.data)[n_var+1] <- "LABEL"
my.data$LABEL <- factor(my.data$LABEL)
# データに目的変数と関係のない説明変数を加える
my.data$MANY_CTG <- factor( rep(1:30, each = n_obs/30) )
my.data$FEWER_CTG <- factor( rep(1:10, each = n_obs/10) )
require(party)
シミュレーション → この部分を飛ばす](https://image.slidesharecdn.com/taha20140329featureselection-140328213046-phpapp01/85/Feature-Selection-with-R-in-JP-23-320.jpg)
![24
# Random Forestを作る
set.seed(my.seed)
model <- cforest(LABEL ~ ., data = my.data, control = cforest_unbiased(mtry = 5, ntree = 51))
# [1] 条件付き重要度
imp <- varimp(model, conditional = T)
fweights.party <- data.table(Feature = names(imp),
RealWeight = c(w, 0, 0),
ConditionalImp = imp)
fweights.party <- fweights.party[order(-ConditionalImp)]
fweights.party$ConditionalImp <- as.integer(fweights.party$ConditionalImp*100000)
fweights.party
# [2] 予測精度の平均低下による重要度
imp.rf <- varimp(model, conditional = F)
fweights.rf <- data.table(Feature = names(imp.rf),
RealWeight = c(w, 0, 0),
MeanDecreaseAccuracy = imp.rf)
fweights.rf <- fweights.rf[order(-MeanDecreaseAccuracy)]
fweights.rf$MeanDecreaseAccuracy <- as.integer(fweights.rf$MeanDecreaseAccuracy*100000)
fweights.rf
require(party)
シミュレーション → この部分を飛ばす](https://image.slidesharecdn.com/taha20140329featureselection-140328213046-phpapp01/85/Feature-Selection-with-R-in-JP-24-320.jpg)












































Ad
More Related Content
What's hot (20)
Viewers also liked (7)





Ad
Similar to Feature Selection with R / in JP (20)










![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=560&fit=bounds)









Ad
Feature Selection with R / in JP
- 1. 第37回R勉強会@東京(#TokyoR) @srctaha Sercan Taha Ahi 2014-03-29 16:00:00 JST (Sat) Rによる特徴選択
- 2. 2 http://theecheloneffect.bandcamp.com/album/random-forest 先ずはLeo Breimanと環境音楽ファンの為のご紹介 Random Forest by Random Forest
- 3. 3 この発表の目標 1. 特徴選択に役に立つ様々なRパッケージの紹介 2. いくつかの簡単なアルゴリズムの紹介 3. Random Forestの「特徴重要度」機能を使う時に気を付けないといけない点の 紹介 4. 発表者が「特徴」と「特徴量」の差が分からないこと、又Leo Breimanのファ ンであることの紹介 Let’s go!
- 4. 4 アジェンダ 1. 自己紹介 2. なぜ特徴選択? 3. 特徴選択法の種類(どうでもいい話ですが一応) 4. 関連Rパッケージの紹介(7つあります) 5. まとめ
- 5. 5 自己紹介 • トルコ、アンカラ出身(1981年) • B.Sc. & M.Sc.:Middle East Technical University(電子電気工学部) • Ph.D.:東京工業大学( 2011年) • 現在はソーシャルゲーム運営会社でデータアナリス • 2003年~2012年「MatlabとC++」 • 2012年以降「R」 • 現在の業務で「R」を日次的に使用しているが、データ取得と加工は主な目的 • Excelは知らないし、じゃっかん苦手でもある
- 6. 6 なぜ特徴選択? 1) 医療保険のみに入っている顧客と、複数の保険に入っている顧客との差はど のような特徴か調べるため(調査空間を縮小するため) 2) ある新規顧客が複数の保険に加入するかどうかを予測するモデルの精度向上 のため 3) 1と2に必要ではない情報を顧客から取らないで、顧客側と企業側の負担を 減らすため 4) 予測モデル作りに必要な計算を減らすため 例:ある保険会社の顧客10万人のデータを元に、医療保険のみに入っている顧 客を特定するというタスクがある。
- 7. 7 特徴選択の種類 (1/3): フィルター法 全ての特徴 フィルタ 特徴部分集合 分類器 • 早い • 過剰適合が起こりにくい
- 8. 8 (2)選択 された特徴 (<P) 遺伝的アルゴリズム 特徴選択の種類 (2/3): ラッパー法(一例) 学習データ (サンプル数:N、特徴数:P) ANN 特徴部分 集合 (<P) 評価 結果 ANN 学習された 分類器 (1) (3) ラッパー(包装)
- 9. 9 特徴選択の種類 (2/3): ラッパー法 • 複数の特徴部分集合で分類器を学習及びテストし、最適な部分集合を探す • テストの際に交差検定を使用する場合が多い • 特徴選択する際に使用される分類器と、選択後に使用される分類器が同じなので、 過剰適合が起こってもおかしくない
- 10. 10 特徴選択の種類 (3/3): 組み込み法 特徴部分集合 組み込み法全ての特徴 分類器 • 分類器を学習する際に特徴選択を行う。例:決定木、Random Forest、L1-SVM 等 • ラッパー法に近いが、更に早く、比較的に過剰適合が起こりにくい
- 11. 11 関連Rパッケージ 1) randomForest( 予測精度と、 ジニ不純度の平均低下による特徴重要度) 2) party(↑の予測精度の平均低下の計り方を変えたアルゴリズム) 3) Boruta(Random Forestを使用したラッパー法) 4) penalizedSVM(SVMのペナルティ関数を変えることが可能に) 5) FSelector(Wekaを元にし、複数の特徴選択法を提供) 6) CORElearn(複数の特徴選択法、10個以上のRelief系アルゴリズム) 7) ClustOfVar(特徴をグループ化し、グループ代表のみを選ぶことを可能に)
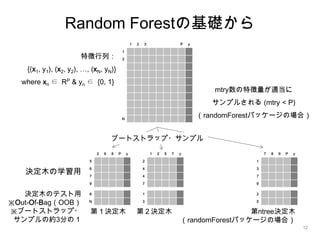
- 12. 12 1 2 3 P y 1 2 N 2 6 8 P y 5 6 7 9 8 N 決定木の学習用 決定木のテスト用 ※Out-Of-Bag(OOB) ※ブートストラップ・ サンプルの約3分の1 1 3 2 5 第1決定木 第2決定木 第ntree決定木 (randomForestパッケージの場合) ブートストラップ・サンプル mtry数の特徴量が適当に サンプルされる (mtry < P) (randomForestパッケージの場合) 特徴行列: {(x1, y1), (x2, y2), …, (xN, yN)} where xn ∈ RP & yn ∈ {0, 1} 1 2 5 7 y 2 4 4 7 7 8 9 P y 1 3 7 9 Random Forestの基礎から
- 13. 13 ★http://tjo.hatenablog.com/entry/2013/12/24/190000★ 説明が分かりづらいと思う方の為に↓
- 14. 14 require(randomForest) (1/2) 予測精度の平均低下による重要度 結論から言うと、 そもそも重要ではない特徴の値を適当に変えても分類精度が変わらないが、 重要な特徴の値を変えると精度が下がる。 ・・・という前提 Breiman and Cutler’s random forests for classification and regression Road to the freedom
- 15. 15 require(randomForest) (1/2) 予測精度の平均低下による重要度 結論から言うと、 そもそも重要ではない特徴の値を適当に変えても分類精度が変わらないが、 重要な特徴の値を変えると精度が下がる。 ・・・という前提 Breiman and Cutler’s random forests for classification and regression
- 17. 17 14個のデータ集合の中、9個が○、5個が△ 1 2 3 4 5 6 7 8 9 1 2 3 4 5 ジニ不純度 = 1 – (割合○)2 – (割合△)2 = 1- (9/14)2 - (5/14)2 = 0.459 require(randomForest) • ジニ不純度が小さければ小さい程データ集合がきれいに別れている • 全ての木で枝を作る前と作った後のジニ不純度の差をとり、その差を枝を作ると きに使用した特徴に与える • 特徴毎に与えられたジニ不純度の差の平均値を算出し、それを「重要度」と呼ぶ (2/2) ジニ不純度の平均低下による重要度
- 18. 18 my.seed <- 12345 set.seed(my.seed) # seedを設定 n_var <- 20 # 特徴量の数 n_obs <- 6000 # 観測データの数 Sigma <- matrix(0, nrow = n_var, ncol = n_var) # 適当な分散共分散行列を作る # 最初の5個の特徴量の間の相関を高めにし、他の特徴量の間で相関がないことにする Sigma[1:5, 1:5] <- 0.9 diag(Sigma) <- 1 A <- mvrnorm(n = n_obs, rep(0, n_var), Sigma) # 多次元正規分布に従って適当な値を作る eps <- rnorm(n_obs, mean = 0, sd = 0.5) # 正規分布に従って1次元の適当な値を作る # 各説明変数と目的変数の関係の重みを決める w <- rep(0, n_var); w[c(3, 5, 10, 15, 16, 20)] <- c(5, 5, 2, -5, -5, -4) # 0/1の目的変数を作る Y <- A %*% w + eps Y <- ifelse(Y < 0, 0, 1) my.data <- as.data.frame(cbind(A, Y)) names(my.data)[1:5] <- paste("CORR_VAR", 1:5, sep = "") names(my.data)[n_var+1] <- "LABEL" my.data$LABEL <- factor(my.data$LABEL) # データに目的変数と関係のない説明変数を加える my.data$MANY_CTG <- factor( rep(1:30, each = n_obs/30) ) my.data$FEWER_CTG <- factor( rep(1:10, each = n_obs/10) ) require(randomForest) シミュレーション
- 19. 19 # Random Forestを作る set.seed(my.seed) model <- randomForest(LABEL ~ ., data = my.data, ntree = 51, importance = T, scale = F) # 特徴量の重要度を確認する require(data.table) # 1: 予測精度の平均低下による重要度 imp1 <- importance(model, type = 1)[, 1] imp1 <- data.table(Feature = names(imp1), RealWeight = c(w, 0, 0), MeanDecreaseAccuracy = imp1) imp1 <- imp1[order(-MeanDecreaseAccuracy)] # 2: ジニ不純度の平均低下による重要度 imp2 <- importance(model, type = 2)[, 1] imp2 <- data.table(Feature = names(imp2), RealWeight = c(w, 0, 0), MeanDecreaseGini = imp2) imp2 <- imp2[order(-MeanDecreaseGini)] require(randomForest) シミュレーション
- 20. 20 予測精度の平均低下による重要度: 相関の高い説明変数が目的変数と 関係がなくても重要に見えてしまう require(randomForest) importance(model, type = 1) Feature RealWeight MeanDecreaseAccuracy 1: V15 -5 30.9710765 2: V16 -5 25.1993199 3: V20 -4 20.5737122 4: CORR_VAR5 5 17.9920379 5: CORR_VAR3 5 16.6779248 6: CORR_VAR4 0 12.0445416 7: CORR_VAR1 0 9.6217582 8: CORR_VAR2 0 8.9002274 9: V10 2 6.8783696 10: V18 0 2.6212311 11: V8 0 2.3560231 12: V19 0 1.9204587 13: V6 0 1.2884192 14: V17 0 0.7733706 15: V12 0 0.7540735 16: FEWER_CTG 0 0.4667292 17: V7 0 0.3346755 18: V13 0 -0.1365008 19: V14 0 -0.1676043 20: MANY_CTG 0 -0.2604303 21: V9 0 -0.8486139 22: V11 0 -0.9929386
- 21. 21 ジニ不純度の平均低下による重要度: 相関の高い説明変数が目的変数と 関係がなくても重要に見えてしまう + カテゴリ数の高い説明変数が 重要に見えてしまう require(randomForest) importance(model, type = 2) Feature RealWeight MeanDecreaseGini 1: CORR_VAR5 5 425.74755 2: CORR_VAR3 5 336.02387 3: V15 -5 312.48866 4: V16 -5 312.25576 5: CORR_VAR4 0 293.87764 6: CORR_VAR1 0 249.50984 7: V20 -4 206.65883 8: MANY_CTG 0 193.26805 9: CORR_VAR2 0 131.95562 10: V10 2 80.22974 11: FEWER_CTG 0 44.43511 12: V8 0 40.49425 13: V13 0 38.81977 14: V11 0 38.67661 15: V12 0 38.32140 16: V19 0 37.76159 17: V18 0 37.46238 18: V14 0 37.10523 19: V6 0 36.56945 20: V17 0 36.49042 21: V9 0 36.32315 22: V7 0 35.08350
- 22. 22 require(party) アイディア→ ※“We want to measure the association between xp (説明変数) and y (目的変数)given the correlation structure between xp and the other predictor variables inherent in the data set. To meet this aim, Strobl et al. (2008) suggest a conditional permutation scheme, where xp is permuted only within groups of observations (他の説明変数)with Z = z in order to preserve the correlation structure between xp and the other predictor variables” A toolbox for recursive partitioning ※Strobl et al., 2009, “Party on! A New, Conditional Variable Importance Measure for Random Forests Available in the party Package” model <- cforest(formula, data = list(), control = cforest_unbiased()) varimp(model, conditional = TRUE) # 予測精度の平均低下 使い方→
- 23. 23 my.seed <- 12345 set.seed(my.seed) # seedを設定 n_var <- 20 # 特徴量の数 n_obs <- 480 # 観測データの数 Sigma <- matrix(0, nrow = n_var, ncol = n_var) # 適当な分散共分散行列を作る # 最初の5個の特徴量の間の相関を高めにし、他の特徴量の間で相関がないことにする Sigma[1:5, 1:5] <- 0.9 diag(Sigma) <- 1 A <- mvrnorm(n = n_obs, rep(0, n_var), Sigma) # 多次元正規分布に従って適当な値を作る eps <- rnorm(n_obs, mean = 0, sd = 0.5) # 正規分布に従って1次元の適当な値を作る # 各説明変数と目的変数の関係の重みを決める w <- rep(0, n_var); w[c(3, 5, 10, 15, 16, 20)] <- c(5, 5, 2, -5, -5, -4) # 0か1の目的変数を作る Y <- A %*% w + eps Y <- ifelse(Y < 0, 0, 1) my.data <- as.data.frame(cbind(A, Y)) names(my.data)[1:5] <- paste("CORR_VAR", 1:5, sep = "") names(my.data)[n_var+1] <- "LABEL" my.data$LABEL <- factor(my.data$LABEL) # データに目的変数と関係のない説明変数を加える my.data$MANY_CTG <- factor( rep(1:30, each = n_obs/30) ) my.data$FEWER_CTG <- factor( rep(1:10, each = n_obs/10) ) require(party) シミュレーション → この部分を飛ばす
- 24. 24 # Random Forestを作る set.seed(my.seed) model <- cforest(LABEL ~ ., data = my.data, control = cforest_unbiased(mtry = 5, ntree = 51)) # [1] 条件付き重要度 imp <- varimp(model, conditional = T) fweights.party <- data.table(Feature = names(imp), RealWeight = c(w, 0, 0), ConditionalImp = imp) fweights.party <- fweights.party[order(-ConditionalImp)] fweights.party$ConditionalImp <- as.integer(fweights.party$ConditionalImp*100000) fweights.party # [2] 予測精度の平均低下による重要度 imp.rf <- varimp(model, conditional = F) fweights.rf <- data.table(Feature = names(imp.rf), RealWeight = c(w, 0, 0), MeanDecreaseAccuracy = imp.rf) fweights.rf <- fweights.rf[order(-MeanDecreaseAccuracy)] fweights.rf$MeanDecreaseAccuracy <- as.integer(fweights.rf$MeanDecreaseAccuracy*100000) fweights.rf require(party) シミュレーション → この部分を飛ばす
- 25. 25 require(party) Feature RealWeight ConditionalImp 1: V15 -5 1359 2: V16 -5 1314 3: CORR_VAR3 5 701 4: V20 -4 311 5: V10 2 245 6: CORR_VAR5 5 245 7: CORR_VAR2 0 144 8: V6 0 44 9: V7 0 11 10: V9 0 11 11: CORR_VAR4 0 11 12: MANY_CTG 0 0 13: V8 0 0 14: V14 0 0 15: CORR_VAR1 0 -11 16: V18 0 -11 17: V19 0 -22 18: FEWER_CTG 0 -22 19: V12 0 -22 20: V13 0 -33 21: V17 0 -33 22: V11 0 -55 観測データの数は480、 ConditionalImpとMeanDecreaseAccuracyは 実際の値の10^6倍(結果を読みやすくするため) Feature RealWeight MeanDecreaseAccuracy 1: CORR_VAR5 5 5436 2: V15 -5 3821 3: CORR_VAR3 5 3765 4: CORR_VAR4 0 3241 5: V16 -5 2662 6: CORR_VAR1 0 2495 7: V20 -4 1470 8: CORR_VAR2 0 779 9: V10 2 289 10: V17 0 245 11: V8 0 111 12: V7 0 100 13: MANY_CTG 0 89 14: V14 0 89 15: V18 0 55 16: V11 0 11 17: FEWER_CTG 0 -22 18: V9 0 -33 19: V12 0 -100 20: V6 0 -111 21: V13 0 -167 22: V19 0 -167 partyの重要度計算が時間かかるが、結果の改善が期待できる!
- 26. 26 require(Boruta) A wrapper algorithm around Random Forests 森の神様
- 27. 27 require(Boruta) A wrapper algorithm around Random Forests 1) 全ての特徴量のコピーをダミー特徴量として元データに加える(cbind) 2) ダミー特徴量だけをシャッフル 3) 拡張されたデータでRandom Forestを実行し、特徴毎に「予測精度の低下 」のZスコアを 算出 4) 重要度を決定前の特徴量とMZSAの「両側検定」を行う 5) MZSAより低く、その差の有意差がある特徴量を「重要ではない」と決め、データからは ずす 6) MZSAより高くて、その差の有意差がある特徴を「重要ではある」と決める 7) ダミー特徴量をはずす 8) ステップ1に戻り、全ての特徴量を「重要ではない・ある」と決めるまでこのプロセスを 繰り返す
- 28. 28 require(Boruta) A wrapper algorithm around Random Forests 1) 全ての特徴量のコピーをダミー特徴量として元データに加える(cbind) 2) ダミー特徴量だけをシャッフル 3) 拡張されたデータでRandom Forestを実行し、特徴毎に「予測精度の低下 」のZスコアを 算出 4) 重要度を決定前の特徴量とMZSAの「両側検定」を行う 5) MZSAより低く、その差の有意差がある特徴量を「重要ではない」と決め、データからは ずす 6) MZSAより高くて、その差の有意差がある特徴を「重要ではある」と決める 7) ダミー特徴量をはずす 8) ステップ1に戻り、全ての特徴量を「重要ではない・ある」と決めるまでこのプロセスを 繰り返す
- 29. 29 require(penalizedSVM) Feature selection by using various penalty functions with SVM SVMと言えば、L2-normですが、このパッケージで以下の4つのペナルテー関数の使用も可 能に 1) L1-norm 2) Smoothly Clipped Absolute Deviation (SCAD) 3) Elastic net (L1 & L2-norm) 4) ELastic SCAD (SCAD + L1 norm) 閉形式解がない! と言うのは、解決が時間が かかる。しかもかなりかかる svm.fs(学習データ, クラスラベル, fs.method = c("scad", "1norm", "scad+L2", "DrHSVM"), …) 主な関数
- 30. 30 require(FSelector) 関数 説明 数式 相関駆動 特徴選択 linear.correlation ピアソンの相関係数 rank.correlation スピアマンの順位相関係数 情報量駆動 特徴選択 information.gain 情報量の増分 gain.ratio 情報量の割合 symmetrical.uncertainty 対称な不確実性 Selecting attributes with various methods )特徴H()クラスH( )特徴、クラスH()特徴H()クラスH( 2 )特徴H( )特徴、クラスH()特徴H()クラスH( )特徴、クラスH()特徴H()クラスH( 22 サンプル数 1n )()( ))(( yyxx yyxx nn nn
- 31. 31 関数 説明 補足 chi.squared カイ二乗フィルター カテゴリデータ用ですが、 連続変数の離散化の上、使用可能。 教師あり離散化のため、discretizationパッケージ がおすすめ。 oneR 1つのルールアルゴリズム relief ReliefF、特徴の重要度を 推定するアルゴリズム Kira and Rendell 1992、元々二項分類のみ RELIEF、RELIEFF、RRELIEFF等の延長版が多い ・・・ require(FSelector) Selecting attributes with various methods
- 32. 32 require(CORElearn) Classification, regression, feature evaluation and ordinal evaluation このパッケージの強みでもあるReliefアルゴリズム F1 F2 F3 y 1 0.6 0.2 0.7 1 2 0.7 0.2 0.7 1 3 0.8 0.3 0.8 1 4 0.1 0.2 0.2 0 5 0.3 0.1 0.1 0 6 0.4 0.2 0.8 0 3 0.8 0.3 0.8 1 6 0.4 0.2 0.8 0 nearMiss 2 0.7 0.2 0.7 1 nearHit (1) 適当に1つの特徴 ベクトルを選択 (2) 選択された特徴 ベクトルに同じクラスと 反対クラスのメンバーの 中で一番近いベクトルを 2つを見つける 二項分類用の 学習データ (3)特徴重みを以下の通りに更新する Wn=W(n-1) – (xn - nearHit)2 + (xn - nearMiss)2 (4)ステップ1に戻り、このサイクルをN回繰り返す(n:サイクル数)
- 33. 33 F1 F2 F3 0.15 0.01 0.10 特徴重要度を表す Wベクトル Relief F1 F2 F3 y 1 0.6 0.2 0.7 1 2 0.7 0.2 0.7 1 3 0.8 0.3 0.8 1 4 0.1 0.2 0.2 0 5 0.3 0.1 0.1 0 6 0.4 0.2 0.8 0 二項分類用の 学習データ require(CORElearn) Classification, regression, feature evaluation and ordinal evaluation このパッケージの強みでもあるReliefアルゴリズム
- 34. 34 attrEval(formula, data, estimator, costMatrix = NULL, ...) 1 Relief 2 ReliefFbestK 3 ReliefKukar 4 ReliefFexpC 5 ReliefFavgC 6 ReliefFpe 7 ReliefFpa 8 ReliefFsmp 9 ReliefFmerit 10 ReliefFdistance 11 ReliefFsqrDistance 12 MyopicReliefF 13 DKM 14 DKMcost 15 EqualDKM 16 UniformDKM 17 InfGain 18 GainRatioCost 19 GainRatio 20 MDL 21 Gini 22 EqualGini 23 ImpurityEuclid 24 ImpurityHellinger 25 UniformGini 26 Accuracy 27 MDLsmp 28 UniformInf 29 UniformAccuracy 30 EqualInf 31 EqualHellinger 32 DistHellinger 33 DistAUC 34 DistAngle 35 DistEuclid 36 EqualHellinger 37 DistHellinger 38 DistAUC 39 DistAngle 40 DistEuclid 分類だけで40個の 特徴重要度推定法 (estimator)がある。 その中、Relief系が10個以上! require(CORElearn)
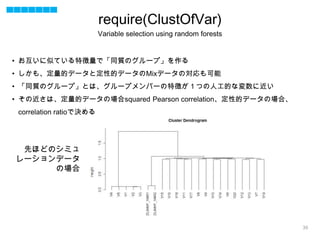
- 35. 35 • お互いに似ている特徴量で「同質のグループ」を作る • しかも、定量的データと定性的データのMixデータの対応も可能 • 「同質のグループ」とは、グループメンバーの特徴が1つの人工的な変数に近い • その近さは、定量的データの場合squared Pearson correlation、定性的データの場合、 correlation ratioで決める 先ほどのシミュ レーションデータ の場合 require(ClustOfVar) Variable selection using random forests
- 36. 36 まとめ • Random Forestの場合、ジニ不純度に基づく重要度は、沢山のカテゴリーのある 特徴量に高い値を与えてしまう。 • Random Forest万歳!と思う方には、partyパッケージのvarimp(model, conditional = TRUE)がお勧め。メモリ消費量も計算時間も多いが。 • penalizedSVMは遅く、 収束しないケースが多い。だけど、特徴量のインパクト の大きさと方向を出せるところが魅力的。 • Borutaはどのような時に役に立つか分からない。 • 世の中にRFラッパー法は沢山あるが、全てを試す価値があるか分からない。
- 37. 37 まとめ • この方法が最高!とは言えないので、複数のアルゴリズムを同時に使用した上で 判断することがお勧め(アンサンブル形式) • アンサンブル形式で特徴選択するには、FSelectorとCORElearnが便利 • Reliefはシンプルな方法で、皆様に是非検討して頂きたい • 特徴量でグループを作ることが格好いい!いつか使ってみよう(自己メモ) • 2変数間の相関を元に重要度を推定するのは、危ないかも(参考文献#4) • アルゴリズムによって(例えば、カイ二乗検定)連続変数の離散化が必要になる。 離散化をそのままパッケージの特徴重要度を測る関数に任せない方が安全だと思 う。
- 38. 38 参考文献 1) Random Forestで計算できる特徴量の重要度、URL(最終アクセス:2014/3/25): http://alfredplpl.hatenablog.com/entry/2013/12/24/225420 2) パッケージユーザーのための機械学習(5):ランダムフォレスト、URL(最終アクセス:2014/3/25): http://tjo.hatenablog.com/entry/2013/12/24/190000 3) Stop using bivariate correlations for variable selection、URL(最終アクセス:2014/3/25): http://jacobsimmering.com/2014/03/20/BivariateCorrelations.html 4) Strobl et al., 2009, “Party on! A New, Conditional Variable Importance Measure for Random Forests Available in the party Package” 5) Becker et al., 2009, “penalizedSVM: a R-package for feature selection SVM classification” 6) 「森の神様」写真 、URL(最終アクセス:2014/3/28): http://morisong04.exblog.jp/i22/ 7) Twitter icon by Nikola Lazarevic、URL(最終アクセス:2014/3/25): http://webexpedition18.com/work/extreme-grunge- social-media-garments-icons-pack/