Flink Forward Berlin 2017: Robert Metzger - Keep it going - How to reliably and efficiently operate Apache Flink
7 likes•2,344 views

This document outlines best practices for operating Apache Flink, covering key topics such as capacity planning, deployment strategies, tuning configurations, and checkpointing. It emphasizes the importance of understanding resource requirements, network traffic, and state management to optimize performance. Furthermore, it provides practical examples and recommendations for ensuring production readiness and high availability in deployments.
































































Flink Forward Berlin 2017: Robert Metzger - Keep it going - How to reliably and efficiently operate Apache Flink
- 1. 1 Keep it going – How to reliably and efficiently operate Apache Flink Robert Metzger @rmetzger
- 2. About this talk § Part of the Apache Flink training offered by data Artisans § Subjective collection of most frequent ops questions on the user mailing list. Topics § Capacity planning § Deployment best practices § Tuning • Work distribution • Memory configuration • Checkpointing • Serialization § Lessons learned 2
- 4. First step: do the math! § Think through the resource requirements of your problem • Number of keys, state per key • Number of records, record size • Number of state updates • What are your SLAs? (downtime, latency, max throughput) § What resources do you have? • Network capacity (including Kafka, HDFS, etc.) • Disk bandwidth (RocksDB relies on the local disk) • Memory • CPUs 4
- 5. Establish a baseline § Normal operation should be able to avoid back pressure § Add a margin for recovery – these resources will be used to “catch up” § Establish your baseline with checkpointing enabled 5
- 6. Consider spiky loads § For example, operators downstream from a Window won’t be continuously busy § How much downstream parallelism is required depends on how quickly you expect to process these spikes 6
- 7. Example: The Setup § Data: • Message size: 2 KB • Throughput: 1,000,000 msg/sec • Distinct keys: 500,000,000 (aggregation in window: 4 longs per key) • Checkpoint every minute 7 Kafka Source keyBy userId Sliding Window 5m size 1m slide Kafka Sink RocksDB
- 8. Example: The setup § Hardware: • 5 machines • 10 gigabit Ethernet • Each machine running a Flink TaskManager • Disks are attached via the network § Kafka is separate 8 TM 1 TM 2 TM 3 TM 4 TM 5 NAS Kafka
- 9. Example: A machine’s perspective 9 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 MB/s 10 Gigabit Ethernet (Full Duplex) In: 1250 MB/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 MB/s 2 KB * 1,000,000 = 2GB/s 2GB/s / 5 machines = 400 MB/s Shuffle: 320 MB/s 80 MB/s Shuffle: 320 MB/s 400MB/s / 5 receivers = 80MB/s 1 receiver is local, 4 remote: 4 * 80 = 320 MB/s out Kafka: 67 MB/s
- 10. Excursion 1: Window emit 10 How much data is the window emitting? Recap: 500,000,000 unique users (4 longs per key) Sliding window of 5 minutes, 1 minute slide Assumption: For each user, we emit 2 ints (user_id, window_ts) and 4 longs from the aggregation = 2 * 4 bytes + 4 * 8 bytes = 40 bytes per key 100,000,000 (users) * 40 bytes = 4 GB every minute from each machine
- 11. Example: A machine’s perspective 11 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 MB/s 10 Gigabit Ethernet (Full Duplex) In: 1250 MB/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 MB/s 2 KB * 1,000,000 = 2GB/s 2GB/s / 5 machines = 400 MB/s Shuffle: 320 MB/s 80 MB/s Shuffle: 320 MB/s 400MB/s / 5 receivers = 80MB/s 1 receiver is local, 4 remote: 4 * 80 = 320 MB/s out Kafka: 67 MB/s 4 GB / minute => 67 MB/ second (on average)
- 12. Example: Result 12 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 MB/s 10 Gigabit Ethernet (Full Duplex) In: 1250 MB/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 MB/s Shuffle: 320 MB/s 80 MB/s Shuffle: 320 MB/s Kafka: 67 MB/s Total In: 720 MB/s Total Out: 387 MB/s
- 13. Example: Result 13 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 mb/s 10 Gigabit Ethernet (Full Duplex) In: 1250 mb/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 mb/s Shuffle: 320 mb/s 80 mb/s Shuffle: 320 mb/s Kafka: 67 mb/s Total In: 720 mb/s Total Out: 387 mb/s WRONG. We forgot: • Disk Access to RocksDB • Checkpointing
- 14. Example: Intermediate Result 14 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 MB/s 10 Gigabit Ethernet (Full Duplex) In: 1250 MB/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 MB/s Shuffle: 320 MB/s Shuffle: 320 MB/s Kafka: 67 MB/s Disk read: ? Disk write: ?
- 15. Excursion 2: Window state access 15 How is the Window operator accessing state? Recap: 1,000,000 msg/sec. Sliding window of 5 minutes, 1 minute slide Assumption: For each user, we store 2 ints (user_id, window_ts) and 4 longs from the aggregation = 2 * 4 bytes + 4 * 8 bytes = 40 bytes per key 5 minute window (window_ts) key (user_id) value (long, long, long, long) Incoming data For each incoming record, update aggregations in 5 windows
- 16. Excursion 2: Window state access 16 How is the Window operator accessing state? For each key-value access, we need to retrieve 40 bytes from disk, update the aggregates and put 40 bytes back per machine: 40 bytes * 5 windows * 200,000 msg/sec = 40 MB/s
- 17. Example: Intermediate Result 17 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 MB/s 10 Gigabit Ethernet (Full Duplex) In: 1250 MB/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 MB/s Shuffle: 320 MB/s Shuffle: 320 MB/s Kafka: 67 MB/s Total In: 760 MB/s Total Out: 427 MB/s Disk read: 40 MB/s Disk write: 40 MB/s
- 18. Excursion 3: Checkpointing 18 How much state are we checkpointing? per machine: 40 bytes * 5 windows * 100,000,000 keys = 20 GB We checkpoint every minute, so 20 GB / 60 seconds = 333 MB/s
- 19. Example: Final Result 19 TaskManager n Kafka Source keyBy window Kafka Sink Kafka: 400 MB/s 10 Gigabit Ethernet (Full Duplex) In: 1250 MB/s 10 Gigabit Ethernet (Full Duplex) Out: 1250 MB/s Shuffle: 320 MB/s Shuffle: 320 MB/s Kafka: 67 MB/s Total In: 760 MB/s Total Out: 760 MB/s Disk read: 40 MB/s Disk write: 40 MB/s Checkpoints: 333 MB/s
- 20. Example: Network requirements 20 TM 2 TM 3 TM 4 TM 5 TM 1 NAS In: 760 MB/s Out: 760 MB/s 5x 80 MB/s = 400 MB/s Kafka 400 MB/s * 5 + 67 MB/s * 5 = 2335 MB/s Overall network traffic: 2 * 760 * 5 + 400 + 2335 = 10335 MB/s = 82,68 Gigabit/s
- 21. Deployment Best Practices Things you should consider before putting a job in production 21
- 22. Deployment Options § Hadoop YARN integration • Cloudera, Hortonworks, MapR, … • Amazon Elastic MapReduce (EMR), Google Cloud dataproc § Mesos & DC/OS integration § Standalone Cluster (“native”) • provided bash scripts • provided Docker images 22 Flink in containerland DAY 3 / 3:20 PM - 4:00 PM MASCHINENHAUS
- 23. Choose your state backend Name Working state State backup Snapshotting RocksDBStateBackend Local disk (tmp directory) Distributed file system Asynchronously • Good for state larger than available memory • Supports incremental checkpoints • Rule of thumb: 10x slower than memory-based backends FsStateBackend JVM Heap Distributed file system Synchronous / Async • Fast, requires large heap MemoryStateBackend JVM Heap JobManager JVM Heap Synchronous / Async • Good for testing and experimentation with small state (locally) 23
- 25. Check the production readiness list § Explicitly set the max parallelism for rescaling • 0 < parallelism <= max parallelism <= 32768 • Max parallelism > 128 has some impact on performance and state size § Set UUIDs for all operators to allow changing the application between restores • By default Flink generates UUIDs § Use the new ListCheckpointed and CheckpointedFunction interfaces 25 Production Readiness Checklist: https://ci.apache.org/projects/flink/flink-docs-release- 1.3/ops/production_ready.html
- 26. Tuning: CPU usage / work distribution 26
- 27. Configure parallelism / slots § These settings influence how the work is spread across the available CPUs § 1 CPU per slot is common § multiple CPUs per slot makes sense if one slot (i.e. one parallel instance of the job) performs many CPU intensive operations 27
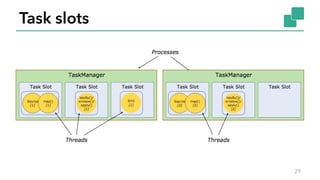
- 29. Task slots 29
- 30. Slot sharing (parallelism now 6) 30
- 31. Benefits of slot sharing § A Flink cluster needs exactly as many task slots as the highest parallelism used in the job § Better resource utilization § Reduced network traffic 31
- 32. What can you do? § Number of TaskManagers vs number of slots per TM § Set slots per TaskManager § Set parallelism per operator § Control operator chaining behavior § Set slot sharing groups to break operators into different slots 32
- 34. Memory in Flink (on YARN) 34 YARN Container Limit JVM Heap (limited by Xmx parameter) Other JVM allocations: Classes, metadata, DirectByteBuffers JVM process size Netty RocksDB? Network buffersInternal Flink services User code (window contents, …) Memory Manager
- 35. Example: Memory in Flink 35 YARN Container Limit: 2000 MB JVM Heap: Xmx: 1500MB = 2000 * 0.75 (default cutoff is 25%) Other JVM allocations: Classes, metadata, stacks, … JVM process size: < 2000 MB Netty ~64MB RocksDB? MemoryManager? up to 70% of the available heap § TaskManager: 2000 MB on YARN “containerized.heap-cutoff-ratio” Container request size “taskmanager.memory.fraction“ RocksDB Config Network Buffers „taskmanager.network. memory.min“ (64MB) and „.max“ (1GB)
- 37. Checkpointing § Measure, analyze and try out! § Configure a checkpointing interval • How much can you afford to reprocess on restore? • How many resources are consumed by the checkpointing? (cost in throughput and latency) § Fine-tuning • “min pause between checkpoints” • “checkpoint timeout” • “concurrent checkpoints” § Configure exactly once / at least once • exactly once does buffer alignment spilling (can affect latency) 37
- 38. 38
- 39. Conclusion 39
- 40. Tuning Approaches § 1. Develop / optimize job locally • Use data generator / small sample dataset • Check the logs for warnings • Check the UI for backpressure, throughput, metrics • Debug / profile locally § 2. Optimize on cluster • Checkpointing, parallelism, slots, RocksDB, network config, … 40
- 41. The usual suspects § Inefficient serialization § Inefficient dataflow graph • Too many repartitionings; blocking I/O § Slow external systems § Slow network, slow disks § Checkpointing configuration 41
- 42. Q & A Let’s discuss … 4 2
- 43. 4 Thank you! @rmetzger | @theplucas @dataArtisans
- 45. Set UUIDs for all (stateful) operators § Operator UUIDs are needed to restore state from a savepoint § Flink will auto—generate UUIDs, but this results in fragile snapshots. § Setting UUIDs in the API: DataStream<String> stream = env .addSource(new StatefulSource()) .uid("source-id") // ID for the source operator .map(new StatefulMapper()) .uid("mapper-id") // ID for the mapper .print(); 45
- 46. Use the savepoint tool for deletions § Savepoint files contain only metadata and depend on the checkpoint files • bin/flink savepoint -d :savepointPath § There is work in progress to make savepoints self-contained à deletion / relocation will be much easier 46
- 47. Avoid the deprecated state APIs § Using the Checkpointed interface will prevent you from rescaling your job § Use ListCheckpointed (like Checkpointed, but redistributeble) or CheckpointedFunction (full flexibility) instead. Production Readiness Checklist: https://ci.apache.org/projects/flink/flink-docs-release- 1.3/ops/production_ready.html 47
- 48. Explicitly set max parallelism § Changing this parameter is painful • requires a complete restart and loss of all checkpointed/savepointed state § 0 < parallelism <= max parallelism <= 32768 § Max parallelism > 128 has some impact on performance and state size 48
- 49. RocksDB § If you have plenty of memory, be generous with RocksDB (note: RocksDB does not allocate its memory from the JVM’s heap!). When allocating more memory for RocksDB on YARN, increase the memory cutoff (= smaller heap) § RocksDB has many tuning parameters. § Flink offers predefined collections of options: • SPINNING_DISK_OPTIMIZED_HIGH_MEM • FLASH_SSD_OPTIMIZED 49
- 51. (de)serialization is expensive § Getting this wrong can have a huge impact § But don’t overthink it 51
- 52. Serialization in Flink § Flink has its own serialization framework, which is used for • Basic types (Java primitives and their boxed form) • Primitive arrays and Object arrays • Tuples • Scala case classes • POJOs § Otherwise Flink falls back to Kryo 52
- 53. A note on custom serializers / parsers § Avoid obvious anti-patterns, e.g. creating a new JSON parser for every record 53 Source map() String keyBy()/ window()/ apply() Sink Source map() keyBy()/ window()/ apply() § Many sources (e.g. Kafka) can parse JSON directly § Avoid, if possible, to ship the schema with every record String
- 54. What else? § You should register types with Kryo, e.g., • env.registerTypeWithKryoSerializer(DateTime.class, JodaDateTimeSerializer.class) § You should register any subtypes; this can increase performance a lot § You can use serializers from other systems, like Protobuf or Thrift with Kyro by registering the types (and serializers) § Avoid expensive types, e.g. Collections, large records § Do not change serializers or type registrations if you are restoring from a savepoint 54
- 56. Deployment Options § Hadoop YARN integration • Cloudera, Hortonworks, MapR, … • Amazon Elastic MapReduce (EMR), Google Cloud dataproc § Mesos & DC/OS integration § Standalone Cluster (“native”) • provided bash scripts • provided Docker images 56 Flink in containerland DAY 3 / 3:20 PM - 4:00 PM MASCHINENHAUS
- 57. Deployment Options § Docs and best-practices coming soon for • Kubernetes • Docker Swarm à Check Flink Documentation details! 57 Flink in containerland DAY 3 / 3:20 PM - 4:00 PM MASCHINENHAUS
- 59. YARN / Mesos HA § Run only one JobManager § Restarts managed by the cluster framework § For HA on YARN, we recommend using at least Hadoop 2.5.0 (due to a critical bug in 2.4) § Zookeeper is always required 59
- 60. Standalone cluster HA § Run standby JobManagers § Zookeeper manages JobManager failover and restarts § TaskManager failures are resolved by the JobManager à Use custom tool to ensure a certain number of Job- and TaskManagers 60
- 62. Outline 1. Hadoop delegation tokens 2. Kerberos authentication 3. SSL 62
- 63. § Quite limited • YARN only • Hadoop services only • Tokens expire Hadoop delegation tokens 63 DATA Job Task Task HDFS Kafka ZK WebUI CLI HTTP Akka token
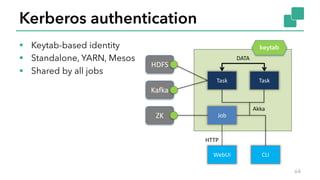
- 64. § Keytab-based identity § Standalone, YARN, Mesos § Shared by all jobs Kerberos authentication 64 DATA Job Task Task HDFS Kafka ZK WebUI CLI HTTP Akka keytab
- 65. SSL § taskmanager.data.ssl.enabled: communication between task managers § blob.service.ssl.enabled: client/server blob service § akka.ssl.enabled: akka-based control connection between the flink client, jobmanager and taskmanager § jobmanager.web.ssl.enabled: https for WebUI 65 DATA Job Task Task HDFS Kafka ZK WebUI CLI HTTPS Akka keytab certs
- 66. Limitations § The clients are not authenticated to the cluster § All the secrets known to a Flink job are exposed to everyone who can connect to the cluster's endpoint § Exploring SSL mutual authentication 66