Free Code Friday: Drill 101 - Basics of Apache Drill
10 likes1,377 views

Apache Drill is an innovative schema-free SQL query engine designed for big data, enabling users to perform low latency analytic queries without the constraints of traditional schema management. It allows organizations to interact with structured, semi-structured, and unstructured data, thus enhancing data exploration and business analytics. The platform supports ANSI SQL and utilizes familiar SQL tools while simplifying dynamic schema handling and on-the-fly schema discovery.










![© 2014 MapR Technologies 11
Drill’s Data Model is Flexible
JSON
BSON
HBase
Parquet
Avro
CSV
TSV
Dynamic
schema
Fixed schema
Complex
Flat
Flexibility
Name Gender Age
Michael M 6
Jennifer F 3
{
name: {
first: Michael,
last: Smith
},
hobbies: [ski, soccer],
district: Los Altos
}
{
name: {
first: Jennifer,
last: Gates
},
hobbies: [sing],
preschool: CCLC
}
RDBMS/SQL-on-Hadoop table
Apache Drill table
Flexibility](https://image.slidesharecdn.com/freecodefriday-basicsofdrill-151207181917-lva1-app6892/85/Free-Code-Friday-Drill-101-Basics-of-Apache-Drill-11-320.jpg)





![© 2014 MapR Technologies 17
Business dataset
{
"business_id": "4bEjOyTaDG24SY5TxsaUNQ",
"full_address": "3655 Las Vegas Blvd SnThe StripnLas Vegas, NV 89109",
"hours": {
"Monday": {"close": "23:00", "open": "07:00"},
"Tuesday": {"close": "23:00", "open": "07:00"},
"Friday": {"close": "00:00", "open": "07:00"},
"Wednesday": {"close": "23:00", "open": "07:00"},
"Thursday": {"close": "23:00", "open": "07:00"},
"Sunday": {"close": "23:00", "open": "07:00"},
"Saturday": {"close": "00:00", "open": "07:00"}
},
"open": true,
"categories": ["Breakfast & Brunch", "Steakhouses", "French", "Restaurants"],
"city": "Las Vegas",
"review_count": 4084,
"name": "Mon Ami Gabi",
"neighborhoods": ["The Strip"],
"longitude": -115.172588519464,
"state": "NV",
"stars": 4.0,
"attributes": {
"Alcohol": "full_bar”,
"Noise Level": "average",
"Has TV": false,
"Attire": "casual",
"Ambience": {
"romantic": true,
"intimate": false,
"touristy": false,
"hipster": false,
"classy": true,
"trendy": false,
"casual": false
},
"Good For": {"dessert": false, "latenight": false, "lunch": false,
"dinner": true, "breakfast": false, "brunch": false},
}
}](https://image.slidesharecdn.com/freecodefriday-basicsofdrill-151207181917-lva1-app6892/85/Free-Code-Friday-Drill-101-Basics-of-Apache-Drill-17-320.jpg)


![© 2014 MapR Technologies 20
Intuitive SQL access to complex data
// It’s Friday 10pm in Vegas and looking for Hummus
> SELECT name, stars, b.hours.Friday friday, categories
FROM dfs.yelp.`business.json` b
WHERE b.hours.Friday.`open` < '22:00' AND
b.hours.Friday.`close` > '22:00' AND
REPEATED_CONTAINS(categories, 'Mediterranean') AND
city = 'Las Vegas'
ORDER BY stars DESC
LIMIT 2;
+------------+------------+------------+------------+
| name | stars | friday | categories |
+------------+------------+------------+------------+
| Olives | 4.0 | {"close":"22:30","open":"11:00"} | ["Mediterranean","Restaurants"] |
| Marrakech Moroccan Restaurant | 4.0 | {"close":"23:00","open":"17:30"} |
["Mediterranean","Middle Eastern","Moroccan","Restaurants"] |
+------------+------------+------------+------------+
Query data
with any
levels of
nesting](https://image.slidesharecdn.com/freecodefriday-basicsofdrill-151207181917-lva1-app6892/85/Free-Code-Friday-Drill-101-Basics-of-Apache-Drill-20-320.jpg)




![© 2014 MapR Technologies 25
Extensions to ANSI SQL to work with repeated values
// Flatten repeated categories
> SELECT name, categories
FROM dfs.yelp.`business.json` LIMIT 3;
+------------+------------+
| name | categories |
+------------+------------+
| Eric Goldberg, MD | ["Doctors","Health & Medical"] |
| Pine Cone Restaurant | ["Restaurants"] |
| Deforest Family Restaurant | ["American (Traditional)","Restaurants"] |
+------------+------------+
> SELECT name, FLATTEN(categories) AS categories
FROM dfs.yelp.`business.json` LIMIT 5;
+------------+------------+
| name | categories |
+------------+------------+
| Eric Goldberg, MD | Doctors |
| Eric Goldberg, MD | Health & Medical |
| Pine Cone Restaurant | Restaurants |
| Deforest Family Restaurant | American (Traditional) |
| Deforest Family Restaurant | Restaurants |
+------------+------------+
Dynamically
flatten repeated
and nested data
elements as part
of SQL queries.
No ETL necessary](https://image.slidesharecdn.com/freecodefriday-basicsofdrill-151207181917-lva1-app6892/85/Free-Code-Friday-Drill-101-Basics-of-Apache-Drill-25-320.jpg)



![© 2014 MapR Technologies 29
Makes it easy to work with dynamic/unknown columns
> jdbc:drill:zk=local> SELECT KVGEN(checkin_info) checkins
FROM dfs.yelp.`checkin.json` LIMIT 1;
+------------+
| checkins |
+------------+
| [{"key":"3-4","value":1},{"key":"13-5","value":1},{"key":"6-6","value":1},{"key":"14-5","value":1},{"key":"14-
6","value":1},{"key":"14-2","value":1},{"key":"14-3","value":1},{"key":"19-0","value":1},{"key":"11-
5","value":1},{"key":"13-2","value":1},{"key":"11-6","value":2},{"key":"11-3","value":1},{"key":"12-
6","value":1},{"key":"6-5","value":1},{"key":"5-5","value":1},{"key":"9-2","value":1},{"key":"9-5","value":1},{"key":"9-
6","value":1},{"key":"5-2","value":1},{"key":"7-6","value":1},{"key":"7-5","value":1},{"key":"7-4","value":1},{"key":"17-
5","value":1},{"key":"8-5","value":1},{"key":"10-2","value":1},{"key":"10-5","value":1},{"key":"10-6","value":1}] |
+------------+
> jdbc:drill:zk=local> SELECT FLATTEN(KVGEN(checkin_info)) checkins FROM
dfs.yelp.`checkin.json` limit 6;
+------------+
| checkins |
+------------+
| {"key":"3-4","value":1} |
| {"key":"13-5","value":1} |
| {"key":"6-6","value":1} |
| {"key":"14-5","value":1} |
| {"key":"14-6","value":1} |
| {"key":"14-2","value":1} |
+------------+
Convert Map with
a wide set of
dynamic columns
into an array of
key-value pairs](https://image.slidesharecdn.com/freecodefriday-basicsofdrill-151207181917-lva1-app6892/85/Free-Code-Friday-Drill-101-Basics-of-Apache-Drill-29-320.jpg)








Free Code Friday: Drill 101 - Basics of Apache Drill
- 1. © 2014 MapR Technologies 1© 2014 MapR Technologies Apache Drill Overview
- 2. © 2014 MapR Technologies 2 Topics • Motivation & Vision • Product walk through • Security overview
- 3. © 2014 MapR Technologies 3 SEMI-STRUCTURED DATA STRUCTURED DATA 1980 2000 20101990 2020 Data Is Doubling Every Two Years! Unstructured data will account for more than 80% of the data collected by organizations Source: Human-Computer Interaction & Knowledge Discovery in Complex Unstructured, Big Data TotalDataStored
- 4. © 2014 MapR Technologies 4 1980 2000 20101990 2020 Fixed schema DBA controls structure Dynamic / Flexible schema Application controls structure NON-RELATIONAL DATASTORESRELATIONAL DATABASES GBs-TBs TBs-PBsVolume Database Data Increasingly Stored in Non-Relational Datastores Structure Development Structured Structured, semi-structured and unstructured Planned (release cycle = months-years) Iterative (release cycle = days-weeks)
- 5. © 2014 MapR Technologies 5 How To Bring SQL Into An Unstructured Future? • SQL • BI (Tableau, MicroStrategy, etc.) • Low latency • Scalability • No schema management – HDFS (Parquet, JSON, etc.) – HBase – … • No transform or silos of data 2 Flexibility of noSQLFamiliarity of SQL ?
- 6. © 2014 MapR Technologies 6 •Industry’s first Schema-free SQL query engine for Big Data •Point-and-query vs. schema-first •Low latency Analytic SQL queries at Scale •Extreme Ease of Use •Industry-standard APIs: ANSI SQL, ODBC/JDBC, RESTful APIs APACHE DRILL
- 7. © 2014 MapR Technologies 7 Extending Self Service to Schema-free data Agility&BusinessValue Use cases for BI IT-Driven BI Self-Service BI Schema-Free Data Exploration IT-Driven BI IT-Driven BI Self-Service BI Analyst-driven with no IT dependency Analyst-driven with IT support for ETL IT-created reports, spreadsheets 1980s -1990s 2000s Now
- 8. © 2014 MapR Technologies 8 Enabling “As-It-Happens” business with instant analytics Hadoop data Data modeling Transformation Data movement Users Hadoop data Users Governed approach Exploratory approach New Business questions Source data evolution Total Time to insight : Weeks to months Total Time to insight: Minutes
- 9. © 2014 MapR Technologies 9© 2014 MapR Technologies Core Technology
- 10. © 2014 MapR Technologies 10 A storage plugin instance - DFS (Text, Parquet, JSON) - HBase/MapRDB - Hive Metastore/Hcatalog - Easy API to go beyond Hadoop A workspace - Sub-directory - HBase namespace - Hive database A table - pathnames - Hive table - HBase table Drill enables ‘SQL on Everything’ SELECT * FROM dfs.yelp.`business.json`
- 11. © 2014 MapR Technologies 11 Drill’s Data Model is Flexible JSON BSON HBase Parquet Avro CSV TSV Dynamic schema Fixed schema Complex Flat Flexibility Name Gender Age Michael M 6 Jennifer F 3 { name: { first: Michael, last: Smith }, hobbies: [ski, soccer], district: Los Altos } { name: { first: Jennifer, last: Gates }, hobbies: [sing], preschool: CCLC } RDBMS/SQL-on-Hadoop table Apache Drill table Flexibility
- 12. © 2014 MapR Technologies 12 Drill Supports Schema Discovery On-The-Fly • Fixed schema • Leverage schema in centralized repository (Hive Metastore) • Fixed schema, evolving schema or schema-less • Leverage schema in centralized repository or self-describing data 2Schema Discovered On-The-FlySchema Declared In Advance SCHEMA ON WRITE SCHEMA BEFORE READ SCHEMA ON THE FLY
- 13. © 2014 MapR Technologies 13 Drill is a Distributed SQL query engine Zookeeper DFS/HBase/H ive DFS/HBase/H ive DFS/HBase/H ive Drillbit Drillbit Drillbit Query 1. Query comes to any Drillbit (JDBC, ODBC, CLI, REST) 2. Drillbit generates execution plan based on query optimization & locality 3. Fragments are farmed to individual nodes 4. Result is returned to driving node
- 14. © 2014 MapR Technologies 14 Core Modules within drillbit SQL Parser Hive HBase StoragePlugins Others DFS PhysicalPlan ExecutionLogicalPlan Optimizer RPC Endpoint
- 15. © 2014 MapR Technologies 15 Drill allows reuse of existing SQL Tools and Skills Leverage SQL-compatible tools (BI, query builders, etc.) via Drill’s standard ODBC, JDBC and ANSI SQL support Enable business analysts, technical analysts and data scientists to explore and analyze large volumes of real-time data
- 16. © 2014 MapR Technologies 16© 2014 MapR Technologies Product Walkthrough
- 17. © 2014 MapR Technologies 17 Business dataset { "business_id": "4bEjOyTaDG24SY5TxsaUNQ", "full_address": "3655 Las Vegas Blvd SnThe StripnLas Vegas, NV 89109", "hours": { "Monday": {"close": "23:00", "open": "07:00"}, "Tuesday": {"close": "23:00", "open": "07:00"}, "Friday": {"close": "00:00", "open": "07:00"}, "Wednesday": {"close": "23:00", "open": "07:00"}, "Thursday": {"close": "23:00", "open": "07:00"}, "Sunday": {"close": "23:00", "open": "07:00"}, "Saturday": {"close": "00:00", "open": "07:00"} }, "open": true, "categories": ["Breakfast & Brunch", "Steakhouses", "French", "Restaurants"], "city": "Las Vegas", "review_count": 4084, "name": "Mon Ami Gabi", "neighborhoods": ["The Strip"], "longitude": -115.172588519464, "state": "NV", "stars": 4.0, "attributes": { "Alcohol": "full_bar”, "Noise Level": "average", "Has TV": false, "Attire": "casual", "Ambience": { "romantic": true, "intimate": false, "touristy": false, "hipster": false, "classy": true, "trendy": false, "casual": false }, "Good For": {"dessert": false, "latenight": false, "lunch": false, "dinner": true, "breakfast": false, "brunch": false}, } }
- 18. © 2014 MapR Technologies 18 Reviews dataset { "votes": {"funny": 0, "useful": 2, "cool": 1}, "user_id": "Xqd0DzHaiyRqVH3WRG7hzg", "review_id": "15SdjuK7DmYqUAj6rjGowg", "stars": 5, "date": "2007-05-17", "text": "dr. goldberg offers everything ...", "type": "review", "business_id": "vcNAWiLM4dR7D2nwwJ7nCA" }
- 19. © 2014 MapR Technologies 19 Zero to Results in 2 minutes $ tar -xvzf apache-drill-1.3.0.tar.gz $ bin/sqlline -u jdbc:drill:zk=local > SELECT state, city, count(*) AS businesses FROM dfs.yelp.`business.json` GROUP BY state, city ORDER BY businesses DESC LIMIT 10; +------------+------------+-------------+ | state | city | businesses | +------------+------------+-------------+ | NV | Las Vegas | 12021 | | AZ | Phoenix | 7499 | | AZ | Scottsdale | 3605 | | EDH | Edinburgh | 2804 | | AZ | Mesa | 2041 | | AZ | Tempe | 2025 | | NV | Henderson | 1914 | | AZ | Chandler | 1637 | | WI | Madison | 1630 | | AZ | Glendale | 1196 | +------------+------------+-------------+ Install Launch shell (embedded mode) Query files and directories Results
- 20. © 2014 MapR Technologies 20 Intuitive SQL access to complex data // It’s Friday 10pm in Vegas and looking for Hummus > SELECT name, stars, b.hours.Friday friday, categories FROM dfs.yelp.`business.json` b WHERE b.hours.Friday.`open` < '22:00' AND b.hours.Friday.`close` > '22:00' AND REPEATED_CONTAINS(categories, 'Mediterranean') AND city = 'Las Vegas' ORDER BY stars DESC LIMIT 2; +------------+------------+------------+------------+ | name | stars | friday | categories | +------------+------------+------------+------------+ | Olives | 4.0 | {"close":"22:30","open":"11:00"} | ["Mediterranean","Restaurants"] | | Marrakech Moroccan Restaurant | 4.0 | {"close":"23:00","open":"17:30"} | ["Mediterranean","Middle Eastern","Moroccan","Restaurants"] | +------------+------------+------------+------------+ Query data with any levels of nesting
- 21. © 2014 MapR Technologies 21 ANSI SQL compatibility //Get top cool rated businesses SELECT b.name from dfs.yelp.`business.json` b WHERE b.business_id IN (SELECT r.business_id FROM dfs.yelp.`review.json` r GROUP BY r.business_id HAVING SUM(r.votes.cool) > 2000 ORDER BY SUM(r.votes.cool) DESC); +------------+ | name | +------------+ | Earl of Sandwich | | XS Nightclub | | The Cosmopolitan of Las Vegas | | Wicked Spoon | +------------+ Use familiar SQL functionality (Joins, Aggregations, Sorting, Sub- queries, SQL data types)
- 22. © 2014 MapR Technologies 22 Logical views //Create a view combining business and reviews datasets > CREATE OR REPLACE VIEW dfs.tmp.BusinessReviews AS SELECT b.name, b.stars, r.votes.funny, r.votes.useful, r.votes.cool, r.`date` FROM dfs.yelp.`business.json` b, dfs.yelp.`review.json` r WHERE r.business_id = b.business_id; +------------+------------+ | ok | summary | +------------+------------+ | true | View 'BusinessReviews' created successfully in 'dfs.tmp' schema | +------------+------------+ > SELECT COUNT(*) AS Total FROM dfs.tmp.BusinessReviews; +------------+ | Total | +------------+ | 1125458 | +------------+ Lightweight file system based views for granular and de- centralized data management
- 23. © 2014 MapR Technologies 23 Materialized Views AKA Tables > ALTER SESSION SET `store.format` = 'parquet'; > CREATE TABLE dfs.yelp.BusinessReviewsTbl AS SELECT b.name, b.stars, r.votes.funny funny, r.votes.useful useful, r.votes.cool cool, r.`date` FROM dfs.yelp.`business.json` b, dfs.yelp.`review.json` r WHERE r.business_id = b.business_id; +------------+---------------------------+ | Fragment | Number of records written | +------------+---------------------------+ | 1_0 | 176448 | | 1_1 | 192439 | | 1_2 | 198625 | | 1_3 | 200863 | | 1_4 | 181420 | | 1_5 | 175663 | +------------+---------------------------+ Save analysis results as tables using familiar CTAS syntax
- 24. © 2014 MapR Technologies 24© 2014 MapR Technologies Working with repeated values
- 25. © 2014 MapR Technologies 25 Extensions to ANSI SQL to work with repeated values // Flatten repeated categories > SELECT name, categories FROM dfs.yelp.`business.json` LIMIT 3; +------------+------------+ | name | categories | +------------+------------+ | Eric Goldberg, MD | ["Doctors","Health & Medical"] | | Pine Cone Restaurant | ["Restaurants"] | | Deforest Family Restaurant | ["American (Traditional)","Restaurants"] | +------------+------------+ > SELECT name, FLATTEN(categories) AS categories FROM dfs.yelp.`business.json` LIMIT 5; +------------+------------+ | name | categories | +------------+------------+ | Eric Goldberg, MD | Doctors | | Eric Goldberg, MD | Health & Medical | | Pine Cone Restaurant | Restaurants | | Deforest Family Restaurant | American (Traditional) | | Deforest Family Restaurant | Restaurants | +------------+------------+ Dynamically flatten repeated and nested data elements as part of SQL queries. No ETL necessary
- 26. © 2014 MapR Technologies 26 Extensions to ANSI SQL to work with repeated values // Get most common business categories >SELECT category, count(*) AS categorycount FROM (SELECT name, FLATTEN(categories) AS category FROM dfs.yelp.`business.json`) c GROUP BY category ORDER BY categorycount DESC; +------------+------------+ | category | categorycount| +------------+------------+ | Restaurants | 14303 | … | Australian | 1 | | Boat Dealers | 1 | | Firewood | 1 | +------------+------------+
- 27. © 2014 MapR Technologies 27© 2014 MapR Technologies Working with Dynamic Columns
- 28. © 2014 MapR Technologies 28 Check ins dataset { "checkin_info":{ "3-4":1, "13-5":1, "6-6":1, "14-5":1, "14-6":1, "14-2":1, "14-3":1, "19-0":1, "11-5":1, "13-2":1, "11-6":2, "11-3":1, "12-6":1, "6-5":1, "5-5":1, "9-2":1, "9-5":1, "9-6":1, "5-2":1, "7-6":1, "7-5":1, "7-4":1, "17-5":1, "8-5":1, "10-2":1, "10-5":1, "10-6":1 }, "type":"checkin", "business_id":"JwUE5GmEO-sH1FuwJgKBlQ" }
- 29. © 2014 MapR Technologies 29 Makes it easy to work with dynamic/unknown columns > jdbc:drill:zk=local> SELECT KVGEN(checkin_info) checkins FROM dfs.yelp.`checkin.json` LIMIT 1; +------------+ | checkins | +------------+ | [{"key":"3-4","value":1},{"key":"13-5","value":1},{"key":"6-6","value":1},{"key":"14-5","value":1},{"key":"14- 6","value":1},{"key":"14-2","value":1},{"key":"14-3","value":1},{"key":"19-0","value":1},{"key":"11- 5","value":1},{"key":"13-2","value":1},{"key":"11-6","value":2},{"key":"11-3","value":1},{"key":"12- 6","value":1},{"key":"6-5","value":1},{"key":"5-5","value":1},{"key":"9-2","value":1},{"key":"9-5","value":1},{"key":"9- 6","value":1},{"key":"5-2","value":1},{"key":"7-6","value":1},{"key":"7-5","value":1},{"key":"7-4","value":1},{"key":"17- 5","value":1},{"key":"8-5","value":1},{"key":"10-2","value":1},{"key":"10-5","value":1},{"key":"10-6","value":1}] | +------------+ > jdbc:drill:zk=local> SELECT FLATTEN(KVGEN(checkin_info)) checkins FROM dfs.yelp.`checkin.json` limit 6; +------------+ | checkins | +------------+ | {"key":"3-4","value":1} | | {"key":"13-5","value":1} | | {"key":"6-6","value":1} | | {"key":"14-5","value":1} | | {"key":"14-6","value":1} | | {"key":"14-2","value":1} | +------------+ Convert Map with a wide set of dynamic columns into an array of key-value pairs
- 30. © 2014 MapR Technologies 30 Makes it easy to work with dynamic/unknown columns // Count total number of checkins on Sunday midnight jdbc:drill:zk=local> SELECT SUM(checkintbl.checkins.`value`) as SundayMidnightCheckins FROM (SELECT FLATTEN(KVGEN(checkin_info)) checkins FROM dfs.yelp.checkin.json`) checkintbl WHERE checkintbl.checkins.key='23-0'; +------------------------+ | SundayMidnightCheckins | +------------------------+ | 8575 | +------------------------+
- 31. © 2014 MapR Technologies 31© 2014 MapR Technologies Security – Next generation access control
- 32. © 2014 MapR Technologies 32 Permissions in HDFS/MapR-FS and HBase/MapR-DB HBase HFile HFile File File DFS File Applications (MapReduce, Spark, Drill, etc.) P File-level Access Control P HBase Applications Field-level access control No “user access control” here (only Hbase can access HFiles)
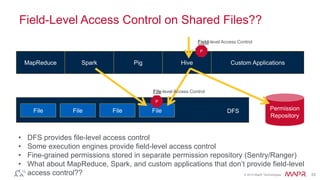
- 33. © 2014 MapR Technologies 33 Field-Level Access Control on Shared Files?? MapReduce Custom Applications File File File File DFS • DFS provides file-level access control • Some execution engines provide field-level access control • Fine-grained permissions stored in separate permission repository (Sentry/Ranger) • What about MapReduce, Spark, and custom applications that don’t provide field-level access control?? Permission Repository DFS Spark Pig Hive P P Field-level Access Control File-level Access Control
- 34. © 2014 MapR Technologies 34 Moving to Logical, Granular, De-centralized Access Control Drill File File File File View DFS PP P PP • Column level and row level access through Drill views • File system permissions/ACLs control who can access a file or view, so there’s no need for a separate permission repository • File/view owner controls access to his data through user impersonation View P
- 35. © 2014 MapR Technologies 35 Granular Access Control Example Name City State Credit Card # Dave San Jose CA 1374-7914-3865-4817 John Boulder CO 1374-9735-1794-9711 Name City State Credit Card # Dave San Jose CA 1374-1111-1111-1111 John Boulder CO 1374-1111-1111-1111 Raw File (/raw/cards.csv) Data Scientist View (/views/maskedcards.csv) Business Analyst View Name City State Dave San Jose CA John Boulder CO Owner Admin Permission Business analysts CREATE VIEW `/views/maskedcards` AS SELECT Name, City, State, MASK(Credit Card #) FROM `/raw/cards.csv`; CREATE VIEW `/views/members` AS SELECT Name, City, State FROM `/raw/cards.csv`; Owner Admin Permission Data scientists Owner Admins Permission Admins Not a physical data copy… Drill views are files in DFS, so these are standard file system permissions
- 36. © 2014 MapR Technologies 36 Summary: Access Control that Scales! • Granular – Different data can be shared with different users/groups (masking, etc.) – Row level and column level security controls • Logical – No physical data copies/silos • De-centralized – No separate permission repository – Utilize Hadoop File System permissions and LDAP – User impersonation respecting storage system permissions • Self-service w/ governance – If you have access to data, you control who and how widely can access it – Audits
- 37. © 2014 MapR Technologies 37 Resources • Learn – Free on demand Drill course • Try it hands on – Amazon Test Drive – MapR sandbox – http://drill.apache.org • Download for your MapR cluster: – https://www.mapr.com/products/apache-drill
- 38. © 2014 MapR Technologies 38© 2014 MapR Technologies Appendix
- 39. © 2014 MapR Technologies 39 SQL technologies available on MapR Drill Impala Hive SparkSQL* Key use cases Self service Data Exploration Interactive BI/Adhoc queries Interactive BI/Adhoc queries Batch/ETL /Long running jobs SQL as part of Spark pipelines/Advanced analytic workflows Data Sources Files support Optimized formats (Parquet, JSON, Text) Yes (all Hive formats) Yes (Parquet, Sequence,RC,Text, AVRO …) Yes (all Hive file formats) Yes (all Hive file formats) Optimized formats (Basic Parquet, JSON) HBase/M7 Yes Yes, performance issues Yes, Performance issues Same as Hive Beyond Hadoop Yes No No Yes Data types Relational Yes Yes Yes Yes Complex/Nested Yes No Limited Limited Metadata Schema- less/Dynamic schema Yes No No limited Hive Meta store Yes Yes Yes Yes SQL /BI tools SQL support ANSI SQL HiveQL HiveQL ANSI SQL (limited) & HiveQL Client support ODBC/JDBC ODBC/JDBC ODBC/JDBC ODBC/JDBC Beyond Memory Yes Yes Yes Yes Optimizer Limited Limited Limited Limited Platform Latency Low Low Medium Low (in-memory) Medium Concurrency High High Medium Medium