Frequent Itemset Mining(FIM) on BigData
Download as PPTX, PDF•4 likes•3,531 views

This document summarizes literature on frequent itemset mining on big data. It first defines key concepts like frequent itemsets, support, and confidence used in frequent itemset mining. It then discusses the Hadoop framework and MapReduce programming model for distributed processing of large datasets. Different algorithms for mining frequent itemsets on Hadoop like single-pass counting, fixed-pass combined counting, and dynamic-pass counting are described. Methods to distribute the search space like partitioning the prefix tree are also covered.















Frequent Itemset Mining(FIM) on BigData
- 1. A LITERATURE SURVEY ON :- “FREQUENT ITEMSET MINING ON BIGDATA” By :- RAJU GUPTA (9028218451) PURUSHOTAM SINGH
- 2. Big Data Big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture,curate, manage, and process the data within a tolerable elapsed time.
- 3. Introduction :- Frequent Itemset Mining (FIM) Support The support supp(X) of an itemset X is defined as the proportion of transactions in the data set which contain the itemset. supp(X)= no. of transactions which contain the itemset X / total no. of transactions. Confidence conf(X->Y)= supp(X U Y)/supp(X).
- 4. Fig:- Example for support and confidence
- 5. Hadoop Framework :- Apache Hadoop is an open-source software framework for storage and large-scale processing of data-sets on clusters of commodity hardware. Hadoop Distributed File System (HDFS). Hadoop MapReduce.
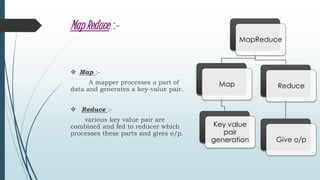
- 6. Map Reduce :- Map :- A mapper processes a part of data and generates a key-value pair. Reduce :- various key value pair are combined and fed to reducer which processes these parts and gives o/p. MapReduce Map Key value pair generation Reduce Give o/p
- 7. EXAMPLE1
- 8. EXAMPLE2
- 9. • It is a programming model and an associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.. • Single pass counting utilizes a map reduce phase for each candidate generation and frequency counting steps..
- 10. • Fixed pass combined counting starts to generate candidates with n different lengths after p phases and count their frequencies in one database scan. • Dynamic passes counting is similar to fixed passes combined counting however n and p is determined dynamically at each phase by the number of generated candidates.
- 11. • Fixed pass combined counting starts to generate candidates with n different lengths after p phases and count their frequencies in one database scan. • Dynamic passes counting is similar to fixed passes combined counting however n and p is determined dynamically at each phase by the number of generated candidates.
- 12. o Parallel FP Growth is a parallel version of well known FP Growth.. PFP groups the items and distributes their conditional databases to the mappers.. o The PARMA algorithm finds aproximate collections of frequent itemsets. o TWISTER improves the performance between map reduce cycles or NIMBLE provides better programming tools for data mining jobs.
- 13. Search space distribution :- The main challenge in adapting algorithms to the MapReduce Framework. Task defined at start up. Prefix tree: oTree Structure where each path represents an itemset. oDivided into independent groups. oEclat traverses the tree in the DFS manner to find FI’s Running Time in Eclat.
- 14. Search space distribution (cont..) :- To estimate the computation time of a subtree. o Total No. of items o Order of frequency of items. o Total Frequency of items. Balanced Partitioning of prefix tree.