From SQL to NoSQL: Structured Querying for JSON
6 likes4,461 views

The document discusses the transition from SQL to NoSQL databases, highlighting the advantages of NoSQL such as agility, scalability, performance, and availability. It outlines the historical development of SQL and its features, compares relational models to JSON document models, and introduces N1QL as a query language for JSON. Various use cases and the evolution of data modeling with JSON are also explored, emphasizing the flexibility and dynamic nature of NoSQL systems.































![33
JSON 101
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"address" :
{
"Street" : "10, Downing Street",
"City" : "San Francico",
"State" : "California",
"zip" :94401
}
}
• Used to represent object data in text
• Representation
• "Key":"Value"
• Data Types:
• Number, Strings, Boolean, objects,
Arrays, NULL
• Hierarchical](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-32-320.jpg)
![34
Flexibility from JSON
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"address" :
{
"Street" : "10, Downing Street",
"City" : "San Francico",
"State" : "California",
"zip" :94401
}
}
• Document is self describing
• Fields can be added or can go missing
• Data types can change
• Arrays give you flexibility in number of
items in an attribute](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-33-320.jpg)

![36
Using JSON to Store Data
CustomerID Name DOB
CBL2015 Jane Smith 1990-01-30
Table: Customer
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" :
"5827-2842-2847-3909",
"expiry" : "2019-03"
}
]
}
Customer DocumentKey: CBL2015
CustomerID Type Cardnum Expiry
CBL2015 visa 5827… 2019-03
Table: Billing
• Rich Structure & Relationships
– Billing information is stored as a sub-document
– There could be more than a single credit card. So, use an array.](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-35-320.jpg)
![37
Using JSON to Store Data
CustomerID Name DOB
CBL2015 Jane Smith 1990-01-30
Table: Customer
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" :
"5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" :
"6274-2542-5847-3949",
"expiry" : "2018-12"
}
]
}
Customer DocumentKey: CBL2015
CustomerID Type Cardnum Expiry
CBL2015 visa 5827… 2019-03
CBL2015 master 6274… 2018-12
Table: Billing
Value evolution
Simply add additional array element or
update a value.](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-36-320.jpg)
![38
Using JSON to Store Data
CustomerID ConnId Name
CBL2015 XYZ987 Joe Smith
CBL2015 SKR007 Sam Smith
Table: Connections {
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" :
"5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" :
"6274-2542-5847-3949",
"expiry" : "2018-12"
}
],
"Connections" : [
{
"ConnId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"ConnId" : ”SKR007",
"Name" : ”Sam Smith"
}
}
Customer DocumentKey: CBL2015
Structure evolution
Simply add new key-value pairs
No downtime to add new KV pairs
Applications can validate data
Structure evolution over time.
Relations via Reference](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-37-320.jpg)
![39
Using JSON to Store Data
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
DocumentKey: CBL2015
CustomerID Name DOB
CBL2015 Jane Smith 1990-01-30
CustomerID Type Cardnum Expiry
CBL2015 visa 5827… 2019-03
CBL2015 master 6274… 2018-12
CustomerID ConnId Name
CBL2015 XYZ987 Joe Smith
CBL2015 SKR007 Sam Smith
CustomerID item amt
CBL2015 mac 2823.52
CBL2015 ipad2 623.52
CustomerID ConnId Name
CBL2015 XYZ987 Joe Smith
CBL2015 SKR007 Sam Smith
Contacts
Customer
Billing
ConnectionsPurchases](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-38-320.jpg)





![45
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-
3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-
3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt":
2823.52 }
{ "id":19, item: "ipad2", "amt":
623.52 }
]
}
LoyaltyInfo Results
Orders
CUSTOMER
• NoSQL systems provide specialized APIs
• Key-Value get and set
• Each task requires custom built program
• Should test & maintain it](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-44-320.jpg)



![49
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo ResultDocuments
Orders
CUSTOMER](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-48-320.jpg)




![54
Considerations: SQL for NoSQL
• Flexible Schema
– Cannot rely on predefined schema
– columns, data types, data comparison
• Nested Objects
– support scalars, objects and array
– SQL operators on nested objects
• Work with distributed data store
• Query Performance
• Optimization
– Exploit data store performance
– Design right kinds of indices
– Optimizer
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"address" :
{
"Street" : "10, Downing Street",
"City" : "San Francico”,
“State” : “California”,
“zip” :94401
}
}](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-53-320.jpg)
![55
N1QL: Approach
• Flexible Schema
– Rely on JSON data interpretation
– Define 4-value predicate logic
– True, False, NULL, MISSING
• Nested Objects
– Key name becomes column reference
– Use dot-notation and array[] reference
• SQL operators on nested objects
– select, join, project operators
– nest and unnest for arrays & objects
• Query Performance Optimization
SELECT c.name,
c.address.zip,
c.phone[0]
FROM customer c
WHERE c.address.zip = 94587
AND ANY s IN c.status
SATISFIES
s = 'Premium'
END
AND purchases IS NOT MISSING;](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-54-320.jpg)










![66
N1QL: SELECT Statement Highlights
• Querying across relationships
– JOINs
– Subqueries
• Aggregation
– MIN, MAX
– SUM, COUNT, AVG, ARRAY_AGG [ DISTINCT ]
• Combining result sets using set operators
– UNION, UNION ALL, INTERSECT, EXCEPT](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-65-320.jpg)
![67
N1QL : Query Operators [ 1 of 2 ]
• USE KEYS …
– Direct primary key lookup bypassing index scans
– Ideal for hash-distributed datastore
– Available in SELECT, UPDATE, DELETE
• JOIN … ON KEYS …
– Nested loop JOIN using key relationships
– Ideal for hash-distributed datastore
– Current implementation supports INNER and LEFT OUTER joins
– ANSI JOINs in the roadmap](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-66-320.jpg)
![68
N1QL : Query Operators [ 2 of 2 ]
• NEST
– Special JOIN that embeds external child documents under their
parent
– Ideal for JSON encapsulation
• UNNEST
– Flattening JOIN that surfaces nested objects as top-level documents
– Ideal for decomposing JSON hierarchies
JOIN, NEST, and UNNEST can be chained in any combination](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-67-320.jpg)
![69
N1QL : Expressions for JSON
Ranging over collections
• WHERE ANY c IN children SATISFIES c.age > 10 END
• WHERE EVERY r IN ratings SATISFIES r > 3 END
Mapping with filtering • ARRAY c.name FOR c IN children WHEN c.age > 10 END
Deep traversal, SET,
and UNSET
• WHERE ANY node WITHIN request SATISFIES node.type = “xyz” END
• UPDATE doc UNSET c.field1 FOR c WITHIN doc END
Dynamic Construction
• SELECT { “a”: expr1, “b”: expr2 } AS obj1, name FROM … // Dynamic
object
• SELECT [ a, b ] FROM … // Dynamic array
Nested traversal • SELECT x.y.z, a[0] FROM a.b.c …
IS [ NOT ] MISSING • WHERE name IS MISSING](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-68-320.jpg)
![70
N1QL : Data Types from JSON
N1QL supports all JSON data types
• Numbers { "id": 5, "balance":2942.59 }
• Strings { "name": "Joe", "city": "Morrisville" }
• Booleans { "premium": true, "balance":2942.59 }
• Null { "last_address": null }
• Arrays { "hobbies": ["tennis", "skiing", "lego"]}
• Objects { address: {"street": "1, Main street", "city": Morrisville,
"state":"CA", "zip":"94824"}}](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-69-320.jpg)

![72
N1QL: Data Modification Statements
• UPDATE … SET … WHERE …
• DELETE FROM … WHERE …
• INSERT INTO … ( KEY, VALUE ) VALUES …
• INSERT INTO … ( KEY …, VALUE … ) SELECT …
• MERGE INTO … USING … ON …
WHEN [ NOT ] MATCHED THEN …
Note: Couchbase provides per-document atomicity.](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-71-320.jpg)














![87
Travel-sample: Hotel Document
"docid": "hotel_25390"
{
"address": "321 Castro St",
…
"city": "San Francisco",
"country": "United States",
"description": "An upscale bed and breakfast in a restored
house.",
"directions": "at 16th",
"geo": {
"accuracy": "ROOFTOP",
"lat": 37.7634,
"lon": -122.435
},
"id": 25390,
"name": "Inn on Castro",
"phone": "+1 415 861-0321",
"price": "$95–$190",
"public_likes": ["John Smith", "Joe Carl", "Jane Smith", "Kate
Smith"],
"reviews": [
{
"author": "Mason Koepp",
"content": ”blah-blah",
"date": "2012-08-23 16:57:56 +0300",
"ratings": {
"Check in / front desk": 3,
"Cleanliness": 3,
Document Key
city: Attributes (key-value pairs)
geo: Object. 1:1 relationship
public_likes: Array of strings:
Embedded 1:many relationship
reviews: Array of objects:
Embedded 1:N relationship
ratings: object within an array](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-86-320.jpg)
![88
Querying Objects
> select h.geo from `travel-sample` h
where type = 'hotel' and city = 'San
Francisco' and meta().id =
"hotel_25390”;
[
{
"geo": {
"accuracy": "ROOFTOP",
"lat": 37.7634,
"lon": -122.435
}
}
]
> select h.geo.lat, h.geo.lon from
`travel-sample` h where type = 'hotel'
and city = 'San Francisco' and
meta().id = "hotel_25390"
[
{
"lat": 37.7634,
"lon": -122.435
}
]
> select reviews[*].ratings from
`travel-sample` h where type = 'hotel'
and city = 'San Francisco' and
meta().id = "hotel_25390" ;
[
{
"ratings": [
{
"Business service": -1,
"Check in / front desk": 3,
"Cleanliness": 3,
"Location": 4,
"Overall": 2,
"Rooms": 2,
"Service": -1,
"Value": 2
}
]
}
]](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-87-320.jpg)
![89
Querying Objects: Accessing data within Objects
>select name, city from `travel-sample` h
where geo = {
"accuracy": "ROOFTOP",
"lat": 37.7634,
"lon": -122.435
};
[
{
"city": "San Francisco",
"name": "Inn on Castro"
}
]
> select h.geo.lat, h.geo.lon from
`travel-sample` h where type = 'hotel' and
city = 'San Francisco' and meta().id =
"hotel_25390" [
{
"lat": 37.7634,
"lon": -122.435
}
]
select name, city from `travel-sample` h
where geo.accuracy = "ROOFTOP" and geo.lat
between 37.7 and 37.8
and geo.lon between -122.4 and -122.3;
[
{
"city": "San Francisco",
"name": "Courtyard San Francisco Downtown"
},
{
"city": "San Francisco",
"name": "Hotel Vitale"
},
{
"city": "San Francisco",
"name": "South Park"
},
{
"city": "San Francisco",
"name": "City Kayak"
},](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-88-320.jpg)
![90
Querying Objects: Indexing objects
CREATE INDEX idxgeo1
ON `travel-sample`
(geo.accuracy,
geo.lat,
geo.lon)
WHERE type = 'hotel';
EXPLAIN select name, city from `travel-
sample` h
WHERE type = 'hotel'
and geo.accuracy = 'ROOFTOP'
and geo.lat between 37.7 and 37.8
and geo.lon between -122.4
and -122.3;
"#operator": "IndexScan",
"index": "idxgeo1",
"index_id": "b2cbf035d2a300e1",
"keyspace": "travel-sample",
"namespace": "default",
"spans": [
{
"Range": {
"High": [
""ROOFTOP"",
"37.8",
"-122.3"
],
"Inclusion": 3,
"Low": [
""ROOFTOP"",
"37.7",
"-122.4"
]
}
}
]](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-89-320.jpg)
![91
Querying Objects: Search WITHIN
select COUNT(1)
FROM system:dual
WHERE ANY v WITHIN {"a":1, "b": "Hello"}
SATISFIES v = "Hello"
END;
[ {
"$1": 1
}
]
select COUNT(1)
FROM system:dual
WHERE ANY v WITHIN {"a":1, "b": "World"}
SATISFIES v = "Hello"
END;
[ {
"$1": 0
}
]
SELECT COUNT(1)
FROM system:dual
WHERE ANY v WITHIN
{ "a":1,
"b": {
"x": "Mercury",
"y": "Venus",
"z": "Earth”
}
}
SATISFIES v = "Earth" END;
[ {
"$1": 1
}
]](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-90-320.jpg)


![94
JSON Arrays
94
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"hobbies" : ["lego", "piano", "badminton", "robotics"],
"scores" : [3.4, 2.9, 9.2, 4.1],
"legos" : [
true,
9292,
"fighter 2",
{
"name" : "Millenium Falcon",
"type" : "Starwars"
}
]
}
• Arrays in JSON
can contain
simply values,
or any
combination of
JSON types
within the
same array.
• No type or
structure
enforcement
within the
array.](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-93-320.jpg)
![95
JSON Arrays
95
{
"Name": "Jane Smith",
"DOB" : "1990-01-30",
"phones" : [
"+1 510-523-3529", "+1 650-392-4923"
],
"Billing": [
{
"type": "visa",
"cardnum": "5827-2842-2847-3909",
"expiry": "2019-03"
},
{
"type": "master",
"cardnum": "6274-2542-5847-3949",
"expiry": "2018-12"
}
]
}
Billing has two credit card
entries, stored as an
ARRAY
Two phone number entries](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-94-320.jpg)
![96
Array Access: Expressions, Functions and Aggregates.
• EXPRESSIONS
• ARRAY
• ANY
• EVERY
• IN
• WITHIN
• Construct [elem]
• Slice
array[start:end]
• Selection
array[#pos]
• FUNCTIONS
• ISARRAY
• TYPE
• ARRAY_APPEND
• ARRAY_CONCAT
• ARRAY_CONTAINS
• ARRAY_DISTINCT
• ARRAY_IFNULL
• ARRAY_FLATTEN
• ARRAY_INSERT
• ARRAY_INTERSECT
• ARRAY_LENGTH
• ARRAY_POSITION
• AGGREGATES
• ARRAY_AVG
• ARRAY_COUNT
• ARRAY_MIN
• ARRAY_MAX
• FUNCTIONS
• ARRAY_PREPEND
• ARRAY_PUT
• ARRAY_RANGE
• ARRAY_REMOVE
• ARRAY_REPEAT
• ARRAY_REPLACE
• ARRAY_REVERSE
• ARRAY_SORT
• ARRAY_STAR
• ARRAY_SUM](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-95-320.jpg)

![98
ARRAYS: UNNEST
• UNNEST : If a document or
object contains an array,
UNNEST performs a join of
the nested array with its parent
document. Each resulting
joined object becomes an
input to the query. UNNEST,
JOINs can be chained.
98
SELECT r.author, COUNT(r.author) AS authcount
FROM `travel-sample` t UNNEST reviews r
WHERE t.type="hotel"
GROUP BY r.author
ORDER BY COUNT(r.author) DESC
LIMIT 5;
[
{
"authcount": 2,
"author": "Anita Baumbach"
},
{
"authcount": 2,
"author": "Uriah Gutmann"
},
{
"authcount": 2,
"author": "Ashlee Champlin"
},
{
"authcount": 2,
"author": "Cassie O'Hara"
},
{
"authcount": 1,
"author": "Zoe Kshlerin"
}
]](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-97-320.jpg)
![99
ARRAYS: NEST
• NEST is the inverse of
UNNEST.
• Nesting is conceptually the
inverse of unnesting. Nesting
performs a join across two
keyspaces. But instead of
producing a cross-product of
the left and right inputs, a
single result is produced for
each left input, while the
corresponding right inputs are
collected into an array and
nested as a single array- 99
SELECT *
FROM `travel-sample` route
NEST `travel-sample` airline
ON KEYS route.airlineid
WHERE route.type = ‘airline' LIMIT 1;
[
{
"airline": [
{
"callsign": "AIRFRANS",
"country": "France",
"iata": "AF",
"icao": "AFR",
"id": 137,
"name": "Air France",
"type": "airline"
}
],
"route": {
"airline": "AF",
"airlineid": "airline_137",
"destinationairport": "MRS",
"distance": 2881.617376098415,
"equipment": "320",
"id": 10000,
"schedule": [
{
"day": 0,
"flight": "AF198",
"utc": "10:13:00"
},
{
"day": 0,
"flight": "AF547",
"utc": "19:14:00"
},
{
"day": 0,
"flight": "AF943",](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-98-320.jpg)



![103
Field names in the dataset
SELECT meta.`view`.columns[*].fieldName
FROM datagov;
[
{
"fieldName": [
":sid",
":id",
":position",
":created_at",
":created_meta",
":updated_at",
":updated_meta",
":meta",
"brth_yr",
"gndr",
"ethcty",
"nm",
"cnt",
"rnk"
]
}
]](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-102-320.jpg)
![104
Transform ARRAYS into FLAT JSON documents
INSERT INTO nynames (KEY UUID(), VALUE kname)
SELECT {
":sid":d[0],
":id":d[1],
":position":d[2],
":created_at":d[3],
":created_meta":d[4],
":updated_at":d[5],
":updated_meta":d[6],
":meta":d[7],"brth_yr":d[8],
"brth_yr":d[9],
"ethcty":d[10],
"nm":d[11],
"cnt":d[12],
"rnk":d[13]} kname
FROM (SELECT d FROM datagov UNNEST data d) as u1;](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-103-320.jpg)
![105
Transform ARRAYS into FLAT JSON documents
INSERT INTO nynames ( KEY UUID(), value o )
SELECT o
FROM (
SELECT meta.`view`.columns[*].fieldName f, data
FROM datagov) d
UNNEST data d1
LET o = OBJECT p:d1[ARRAY_POSITION(d.f, p)]
FOR p IN d.f END ;](https://image.slidesharecdn.com/nysqlnosqlv0-170920010915/85/From-SQL-to-NoSQL-Structured-Querying-for-JSON-104-320.jpg)










From SQL to NoSQL: Structured Querying for JSON
- 1. FROM SQL TO NOSQL: STRUCTURED QUERYING FOR JSON Keshav Murthy Senior Director, Couchbase R&D
- 2. At Connect, we’ll show you how to use the most revolutionary technology in the world to create amazing customer experiences. Register at http://bit.ly/connectSV2017 • 6 hands-on workshops • 5 role-based tracks • 30+ technical and business sessions
- 3. 3 Don Chamberlin IBM Fellow, Co-inventor of SQL
- 4. 4
- 5. 5 • Developed Database features for Sybase, Illustra, Informix, IBM • Developed SQL, NoSQL features and products. • Collaborated with IBM Research • Received seven US Patents • Recognized by IBM for outstanding technical Innovations • Wal-Mart on their logistics application • Query Innovations • Received Couchbase President award for impact • Authored three Redbooks, One N1QL book, several papers Keshav Murthy
- 6. AGENDA 1 2 3 4 5 6 SQL: Origins and Motivations SQL Today NoSQL Relational Model to JSON Model SQL to N1QL: The Basics N1QL and JSON : Joy of JSON
- 7. AGENDA 1 2 3 4 5 6 SQL: Origins and Motivations SQL in RDBMS NoSQL Relational Model to JSON Model SQL to N1QL: The Basics N1QL Language
- 8. 1 SQL: ORIGINS AND MOTIVATIONS
- 9. 9 SQL: Origins • Codd developed relational model. "A Relational Model of Data for Large Shared Data Banks” • Relational model was invented to provide complete flexibility in Modeling and querying • E.g. Any two attributes (columns) can be joined without predefined relationship • Codd also proposed a language to manipulate relations (tuples in tables). • This required writing procedural programs to manipulate data • Written using variables and need understanding of predicate calculus. • Don Chamberlin and Raymond Boyce developed SQL • SEQUEL: A STRUCIURD ENGLISH QUERY LANGUAGE, 1974 • Codd, Don, Raymond all worked in IBM Research, San Jose, California.
- 10. 10
- 11. 11
- 12. 12 SQL Structured Query Language is a special-purpose programming language designed for managing data held in a relational database management system (RDBMS). Originally based upon relational algebra and tuple relational calculus, SQL consists of a data definition language, data manipulation language, and a data control language. Source: https://en.wikipedia.org/wiki/SQL
- 13. 2 SQL IN RDBMS
- 14. 14 SQL SQL<
- 15. 15 SQL SQL• Hide the complexity of relational calculus • English Language based access to Data • Language to manipulate data easily • Targeted for developers & professionals • SELECT, INSERT, UPDATE, DELETE, … • Arithmetic and logical operators • Data Types • Schema management • All of original SQL capabilities • ++++++ • Transactions – ACID • Stored procedures, Triggers, Indexes • Views, Materialized Views • Optimizers: Rule & Cost based optimizers • Spatial, Search, integrations • Storage optimizations • SMP, MPP innovations • Performance: TPC • Distributed Query Processing • Two-phase commits • T-SQL, PL/SQL,… • JDBC, ODBC drivers. • Tools Life as we know it depends on SQL & OLTP <
- 16. 16 SQL: Progress • 1970 : Codd developed relational model. "A Relational Model of Data for Large Shared Data Banks” • 1974-1979 : System R with SQL (later SQL) at IBM Research Lab • 1979 : Oracle markets first relational database with SQL • 1986 : ANSI SQL Standard released • 1989, 1992, 1999, 2003, 2008, 2011, 2016: Major ANSI standard updates
- 17. 3 NOSQL
- 19. 19 Why NoSQL? Agility • Schema flexibility • Easier management of change • In the business requirements • In the structure of the data • Change is inevitable
- 20. 20 Why NoSQL? Scalability • Elastic scaling • Size your cluster for today • Scale out on demand • Cost effective scaling • Commodity hardware • On premise or on cloud • Scale OUT instead of just Scale UP
- 21. 21 Why NoSQL? Scalability: Elastic Scaling STORAGE Managed Cache Cluster Manager NoSQL Node STORAGE Managed Cache Cluster Manager NoSQL Node STORAGE Managed Cache Cluster Manager NoSQL Node STORAGE Managed Cache Cluster Manager NoSQL Node STORAGE Managed Cache Cluster Manager NoSQL Node STORAGE Managed Cache Cluster Manager NoSQL Node STORAGE Managed Cache Cluster Manager NoSQL Node Couchbase Cluster
- 22. 22 Why NoSQL? Performance • NoSQL systems are optimized for specific access patterns • Low response time for web & mobile user experience • Millisecond latency • Consistently high throughput to handle growth
- 23. 23 Why NoSQL? Availability • Built-in replication and fail-over • No application downtime when hardware fails • Online maintenance & upgrade • No application downtime
- 24. 24 CAP Theorem - 101 • Each distributed system can only provide two properties simultaneously. • Partition Tolerance is required in our systems • Choice is between Availability and Consistency Availability Partition Tolerance Consistency
- 25. 25 NoSQL: Landscape Document • Couchbase • MongoDB • DynamoDB • DocumentDB Graph • OrientDB • Neo4J • DEX • GraphBase Key-Value • Riak • BerkeleyDB • Redis • … Wide Column • Hbase • Cassandra • Hypertable
- 26. NOSQL USE CASES
- 27. 28 ✋ Hon, Where are we going for vacation this summer?S ✔$ $$ $$ 🤔 ! You got a job! Google,friends,books. Suggest 5 ideas 👬 Talk to Family, See trip advisor, Expedia. Select 2 👪 Talk about the $$$. Search alternatives Decision TimeBUY Get confirmation; Book activities Go on vacation Feedback & Social 😎✌ Your Vacation: From Thought to Finish
- 28. 29 ✋ Hon, Where are we going for vacation this summer?S ✔$ $$ $$ 🤔 ! You got a job! Google,friends,books. Suggest 5 ideas 👬 Talk to Family, See trip advisor, Expedia. Select 2 👪 Talk about the $$$. Search alternatives Decision TimeBUY Get confirmation; Book activities Go on vacation Feedback & Social 😎✌ Systems of Engagement Systems of Engagement Systems of Engagement Systems of Engagement Systems of Engagement Systems of Record Systems of Record Systems of Engagement Systems of Record Systems of Engagement Systems of Engagement Your Vacation: From Thought to Finish
- 29. 4 RELATIONAL MODEL TO JSON MODEL
- 30. 31 Properties of Real-World Data • Rich structure • Attributes, Sub-structure • Relationships • To other data • Value evolution • Data is updated • Structure evolution • Data is reshaped Customer Name DOB Billing Connections Purchases
- 31. 32 Modeling Data in Relational World Billing ConnectionsPurchases Contacts Customer Rich structure Normalize & JOIN Queries Relationships JOINS and Constraints Value evolution INSERT, UPDATE, DELETE Structure evolution ALTER TABLE Application Downtime Application Migration Application Versioning
- 32. 33 JSON 101 { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2842-2847-3909", "expiry" : "2019-03" } ], "address" : { "Street" : "10, Downing Street", "City" : "San Francico", "State" : "California", "zip" :94401 } } • Used to represent object data in text • Representation • "Key":"Value" • Data Types: • Number, Strings, Boolean, objects, Arrays, NULL • Hierarchical
- 33. 34 Flexibility from JSON { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2842-2847-3909", "expiry" : "2019-03" } ], "address" : { "Street" : "10, Downing Street", "City" : "San Francico", "State" : "California", "zip" :94401 } } • Document is self describing • Fields can be added or can go missing • Data types can change • Arrays give you flexibility in number of items in an attribute
- 34. 35 Using JSON For Real World Data CustomerID Name DOB CBL2015 Jane Smith 1990-01-30 Table: Customer { "Name" : "Jane Smith", "DOB" : "1990-01-30” } Customer DocumentKey: CBL2015 • The primary (CustomerID) becomes the DocumentKey • Column name-Column value become KEY-VALUE pair. { "Name" : { "fname": "Jane ", "lname": "Smith” } "DOB" : "1990-01-30” } OR
- 35. 36 Using JSON to Store Data CustomerID Name DOB CBL2015 Jane Smith 1990-01-30 Table: Customer { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" } ] } Customer DocumentKey: CBL2015 CustomerID Type Cardnum Expiry CBL2015 visa 5827… 2019-03 Table: Billing • Rich Structure & Relationships – Billing information is stored as a sub-document – There could be more than a single credit card. So, use an array.
- 36. 37 Using JSON to Store Data CustomerID Name DOB CBL2015 Jane Smith 1990-01-30 Table: Customer { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2542-5847-3949", "expiry" : "2018-12" } ] } Customer DocumentKey: CBL2015 CustomerID Type Cardnum Expiry CBL2015 visa 5827… 2019-03 CBL2015 master 6274… 2018-12 Table: Billing Value evolution Simply add additional array element or update a value.
- 37. 38 Using JSON to Store Data CustomerID ConnId Name CBL2015 XYZ987 Joe Smith CBL2015 SKR007 Sam Smith Table: Connections { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2542-5847-3949", "expiry" : "2018-12" } ], "Connections" : [ { "ConnId" : "XYZ987", "Name" : "Joe Smith" }, { "ConnId" : ”SKR007", "Name" : ”Sam Smith" } } Customer DocumentKey: CBL2015 Structure evolution Simply add new key-value pairs No downtime to add new KV pairs Applications can validate data Structure evolution over time. Relations via Reference
- 38. 39 Using JSON to Store Data { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2842-2847-3909", "expiry" : "2019-03" } ], "Connections" : [ { "CustId" : "XYZ987", "Name" : "Joe Smith" }, { "CustId" : "PQR823", "Name" : "Dylan Smith" } { "CustId" : "PQR823", "Name" : "Dylan Smith" } ], "Purchases" : [ { "id":12, item: "mac", "amt": 2823.52 } { "id":19, item: "ipad2", "amt": 623.52 } ] } DocumentKey: CBL2015 CustomerID Name DOB CBL2015 Jane Smith 1990-01-30 CustomerID Type Cardnum Expiry CBL2015 visa 5827… 2019-03 CBL2015 master 6274… 2018-12 CustomerID ConnId Name CBL2015 XYZ987 Joe Smith CBL2015 SKR007 Sam Smith CustomerID item amt CBL2015 mac 2823.52 CBL2015 ipad2 623.52 CustomerID ConnId Name CBL2015 XYZ987 Joe Smith CBL2015 SKR007 Sam Smith Contacts Customer Billing ConnectionsPurchases
- 39. 40 Models for Representing Data Data Concern Relational Model JSON Document Model (NoSQL) Rich Structure Multiple flat tables Constant assembly / disassembly Documents No assembly required! Relationships Represented Queried (SQL) Represented N1QL, SQL++ Value Evolution Data can be updated Data can be updated Structure Evolution Uniform and rigid Manual change (disruptive) Flexible Dynamic change
- 40. 41 Models for Representing Data Model Relational Model JSON Document Model in Couchbase 1:1 Foreign Key Denormalize Embedded Object (implicit) Document Key Reference 1:N Foreign Key Embedded Array of Objects Document key Reference N:M Foreign Key Embedded Array of Objects Arrays of objects with references
- 41. 5 SQL TO N1QL: MOTIVATION
- 42. 43 Business Use Cases Drive Applications How many new customers we got last month? Process Order Checkout Search stores for the shoe customer is looking for? Generate a list of shipment due today Load the new inventory data Retrieve the customer order Merge the customer lists Progress
- 44. 45 { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847- 3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2842-2847- 3909", "expiry" : "2019-03" } ], "Connections" : [ { "CustId" : "XYZ987", "Name" : "Joe Smith" }, { "CustId" : "PQR823", "Name" : "Dylan Smith" } { "CustId" : "PQR823", "Name" : "Dylan Smith" } ], "Purchases" : [ { "id":12, item: "mac", "amt": 2823.52 } { "id":19, item: "ipad2", "amt": 623.52 } ] } LoyaltyInfo Results Orders CUSTOMER • NoSQL systems provide specialized APIs • Key-Value get and set • Each task requires custom built program • Should test & maintain it
- 45. 46 NoSQL Data Access • NoSQL systems provide specialized APIs • Key-Value get and set • Script based query APIs • Limited declarative query • This provides procedural access to data, JSON by JSON
- 46. 47 Client Side Implementation of Query is Inadequate Find High-Value Customers with Orders > $10000 Query customer objects from database • Complex codes and logic • Inefficient processing on client side For each customer object Find all the order objects for the customer Calculate the total amount for each order Sum up the grand total amount for all orders If grand total amount > $10000, Extract customer data Add customer to the high-value customer list Sort the high-value customer list LOOPING OVER MILLIONS OF CUSTOMERS IN APPLICATION!!!
- 47. 48
- 48. 49 { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2842-2847-3909", "expiry" : "2019-03" } ], "Connections" : [ { "CustId" : "XYZ987", "Name" : "Joe Smith" }, { "CustId" : "PQR823", "Name" : "Dylan Smith" } { "CustId" : "PQR823", "Name" : "Dylan Smith" } ], "Purchases" : [ { "id":12, item: "mac", "amt": 2823.52 } { "id":19, item: "ipad2", "amt": 623.52 } ] } LoyaltyInfo ResultDocuments Orders CUSTOMER
- 49. 50 N1QL = SQL + JSON Give developers and enterprises an expressive, powerful, and complete language for querying, transforming, and manipulating JSON data.
- 50. 51 Why SQL for NoSQL?
- 51. 52 Industry Is Extending SQL to Query JSON • JSON support in SQL – Oracle – PostgreSQL – MySQL • Microsoft: SQL for CosmosDB (DocumentDB) • UC San Diego: SQL++ • Couchbase: N1QL
- 52. N1QL: SQL FOR JSON CONSIDERATIONS
- 53. 54 Considerations: SQL for NoSQL • Flexible Schema – Cannot rely on predefined schema – columns, data types, data comparison • Nested Objects – support scalars, objects and array – SQL operators on nested objects • Work with distributed data store • Query Performance • Optimization – Exploit data store performance – Design right kinds of indices – Optimizer { "Name" : "Jane Smith", "DOB" : "1990-01-30", "Billing" : [ { "type" : "visa", "cardnum" : "5827-2842-2847-3909", "expiry" : "2019-03" }, { "type" : "master", "cardnum" : "6274-2842-2847-3909", "expiry" : "2019-03" } ], "address" : { "Street" : "10, Downing Street", "City" : "San Francico”, “State” : “California”, “zip” :94401 } }
- 54. 55 N1QL: Approach • Flexible Schema – Rely on JSON data interpretation – Define 4-value predicate logic – True, False, NULL, MISSING • Nested Objects – Key name becomes column reference – Use dot-notation and array[] reference • SQL operators on nested objects – select, join, project operators – nest and unnest for arrays & objects • Query Performance Optimization SELECT c.name, c.address.zip, c.phone[0] FROM customer c WHERE c.address.zip = 94587 AND ANY s IN c.status SATISFIES s = 'Premium' END AND purchases IS NOT MISSING;
- 55. N1QL: SQL FOR JSON
- 56. N1QL AGENDA 1 3 4 5 6 Enterprises Using N1QL Features Indexing Architecture Transactions 7 Resources
- 58. 59 Hundreds of Couchbase Deployments with N1QL
- 59. N1QL: FEATURES
- 60. 61 N1QL: SELECT Statement SELECT * FROM customers c WHERE c.address.state = 'NY' AND c.status = 'premium' ORDER BY c.address.zip Project Everything From the bucket customers From the bucket customers Predicate
- 61. 62 N1QL: SELECT Statement SELECT customers.id, customers.NAME.lastname, customers.NAME.firstname Sum(orderline.amount) FROM orders UNNEST orders.lineitems AS orderline INNER JOIN customers ON KEYS orders.custid WHERE customers.state = 'NY' GROUP BY customers.id, customers.NAME.lastname, customers.NAME.firstname HAVING sum(orderline.amount) > 10000 ORDER BY sum(orderline.amount) DESC • Dotted sub-document reference • Names are CASE- SENSITIVE UNNEST to flatten the arrays JOINS with Document KEY of customers
- 62. 63 N1QL: Composable SELECT Statement SELECT * FROM (SELECT a, b, c FROM us_cust WHERE x = 1 ORDER BY x LIMIT 100 OFFSET 0 UNION ALL SELECT a, b, c FROM canada_cust WHERE y = 2 ORDER BY x LIMIT 100 OFFSET 0) AS newtab LEFT OUTER JOIN contacts ON KEYS newtab.c.contactid ORDER BY a, b, c LIMIT 20 OFFSET 100
- 63. 64 N1QL: Examples SELECT d.C_ZIP, SUM(ORDLINE.OL_QUANTITY) AS TOTALQTY FROM CUSTOMER d UNNEST ORDERS as CUSTORDERS UNNEST CUSTORDERS.ORDER_LINE AS ORDLINE WHERE d.C_STATE = ”NY” GROUP BY d.C_ZIP ORDER BY TOTALQTY DESC; INSERT INTO CUSTOMER("PQR847", {"C_ID":4723, "Name":"Joe"}); UPDATE CUSTOMER c SET c.STATE=“CA”, c.C_ZIP = 94501 WHERE c.ID = 4723;
- 64. 65 N1QL: Examples INSERT INTO CUSTOMER VALUES("PQR847", {"C_ID":4723, "Name":"Joe"}); INSERT INTO CUSTOMER VALUES("key1", {"C_ID":4823, "Name":"Sam"}), VALUES("key2", {"C_ID":8282, "Name":"Dan"}), VALUES("key3", {"C_ID":4352, "Name":"Jane"}); INSERT INTO CUSTOMER (KEY “cx::”||custid, VALUE doc) SELECT custid, {custid, name, address, history} doc FROM acmestores;
- 65. 66 N1QL: SELECT Statement Highlights • Querying across relationships – JOINs – Subqueries • Aggregation – MIN, MAX – SUM, COUNT, AVG, ARRAY_AGG [ DISTINCT ] • Combining result sets using set operators – UNION, UNION ALL, INTERSECT, EXCEPT
- 66. 67 N1QL : Query Operators [ 1 of 2 ] • USE KEYS … – Direct primary key lookup bypassing index scans – Ideal for hash-distributed datastore – Available in SELECT, UPDATE, DELETE • JOIN … ON KEYS … – Nested loop JOIN using key relationships – Ideal for hash-distributed datastore – Current implementation supports INNER and LEFT OUTER joins – ANSI JOINs in the roadmap
- 67. 68 N1QL : Query Operators [ 2 of 2 ] • NEST – Special JOIN that embeds external child documents under their parent – Ideal for JSON encapsulation • UNNEST – Flattening JOIN that surfaces nested objects as top-level documents – Ideal for decomposing JSON hierarchies JOIN, NEST, and UNNEST can be chained in any combination
- 68. 69 N1QL : Expressions for JSON Ranging over collections • WHERE ANY c IN children SATISFIES c.age > 10 END • WHERE EVERY r IN ratings SATISFIES r > 3 END Mapping with filtering • ARRAY c.name FOR c IN children WHEN c.age > 10 END Deep traversal, SET, and UNSET • WHERE ANY node WITHIN request SATISFIES node.type = “xyz” END • UPDATE doc UNSET c.field1 FOR c WITHIN doc END Dynamic Construction • SELECT { “a”: expr1, “b”: expr2 } AS obj1, name FROM … // Dynamic object • SELECT [ a, b ] FROM … // Dynamic array Nested traversal • SELECT x.y.z, a[0] FROM a.b.c … IS [ NOT ] MISSING • WHERE name IS MISSING
- 69. 70 N1QL : Data Types from JSON N1QL supports all JSON data types • Numbers { "id": 5, "balance":2942.59 } • Strings { "name": "Joe", "city": "Morrisville" } • Booleans { "premium": true, "balance":2942.59 } • Null { "last_address": null } • Arrays { "hobbies": ["tennis", "skiing", "lego"]} • Objects { address: {"street": "1, Main street", "city": Morrisville, "state":"CA", "zip":"94824"}}
- 70. 71 N1QL : Data Type Handling Non-JSON data types – MISSING – Binary Data type handling • Date functions for string and numeric encodings • Total ordering across all data types – Well defined semantics for ORDER BY and comparison operators • Defined expression semantics for all input data types – No type mismatch errors
- 71. 72 N1QL: Data Modification Statements • UPDATE … SET … WHERE … • DELETE FROM … WHERE … • INSERT INTO … ( KEY, VALUE ) VALUES … • INSERT INTO … ( KEY …, VALUE … ) SELECT … • MERGE INTO … USING … ON … WHEN [ NOT ] MATCHED THEN … Note: Couchbase provides per-document atomicity.
- 72. 73 N1QL: Data Modification Statements INSERT INTO ORDERS (KEY, VALUE) VALUES ("1.ABC.X382", {"O_ID":482, "O_D_ID":3, "O_W_ID":4}); UPDATE ORDERS SET O_CARRIER_ID = ”ABC987” WHERE O_ID = 482 AND O_D_ID = 3 AND O_W_ID = 4 DELETE FROM NEW_ORDER WHERE NO_D_ID = 291 AND NO_W_ID = 3482 AND NO_O_ID = 2483 JSON literals can be used in any expression
- 74. 75 Couchbase Server Cluster Service Deployment STORAGE Couchbase Server 1 SHARD 7 SHARD 9 SHARD 5 SHARDSHARDSHARD Managed Cache Cluster ManagerCluster Manager Managed Cache Storage Data Service STORAGE Couchbase Server 2 Managed Cache Cluster ManagerCluster Manager Data Service STORAGE Couchbase Server 3 SHARD 7 SHARD 9 SHARD 5 SHARDSHARDSHARD Managed Cache Cluster ManagerCluster Manager Data Service STORAGE Couchbase Server 4 SHARD 7 SHARD 9 SHARD 5 SHARDSHARDSHARD Managed Cache Cluster ManagerCluster Manager Query Service STORAGE Couchbase Server 5 SHARD 7 SHARD 9 SHARD 5 SHARDSHARDSHARD Managed Cache Cluster ManagerCluster Manager Query Service STORAGE Couchbase Server 6 SHARD 7 SHARD 9 SHARD 5 SHARDSHARDSHARD Managed Cache Cluster ManagerCluster Manager Index Service Managed Cache Storage Managed Cache Storage Storage STORAGE Couchbase Server 6 SHARD 7 SHARD 9 SHARD 5 SHARDSHARDSHARD Managed Cache Cluster ManagerCluster Manager Index Service Storage Managed Cache Managed Cache SDK SDK
- 75. 76 N1QL: Query Execution Flow Clients 1. Submit the query over REST API 8. Query result 2. Parse, Analyze, create Plan 7. Evaluate: Documents to results 3. Scan Request; index filters 6. Fetch the documents Index Service Query Service Data Service 4. Get qualified doc keys 5. Fetch Request, doc keys SELECT c_id, c_first, c_last, c_max FROM CUSTOMER WHERE c_id = 49165; { "c_first": "Joe", "c_id": 49165, "c_last": "Montana", "c_max" : 50000 }
- 76. 77 N1QL: Inside the Query Service Client FetchParse Plan Join Filter Pre-Aggregate Offset Limit ProjectSortAggregateScan Query Service Index Service Data Service
- 77. TRANSACTIONS
- 78. 79 TRANSACTIONS • Framework to implement business transaction • Defined by the ACID properties • From BEGIN WORK to COMMIT/ROLLBACK WORK there can be multiple statements • Each SQL statement within a transaction can update multiple statements and is atomic • Many databases provide savepoints and rollback to a specific savepoint.
- 79. 80 Consistency Levels • Applicable only for the index scans. • Index is asynchronously maintained • Index data is eventually consistent • Data read from the key-value (KV) service is always consistent. • UNBOUNDED: Equivalent to stale=OK. Best effort. • AT_PLUS: Read Your Own Writes • REQUEST_PLUS: Index snapshot is up to date • Consistency levels is applicable ONLY to index scans
- 80. 81 N1QL Clients Scan Request; with consistency level Index Service Query Service Data Service UPDATE CUSTOMER SET WHERE address.city = ‘ny’ AND sttatus = ‘premium’ RETURNING META().id; “id” : [ ”id": ”cx:39293", ”id": ”cx:49283", ”id": ”cx:942948", ”id": ”cx:492982”, } Snapshot isolation. Implement the consistency levels Consistency Levels Unbounded AT_PLUS REQUEST_PLUS Always CONSISTENT MODIFY THE DOCUMENT UPDATE THE DOCUMENT
- 81. N1QL: INDEXING
- 82. 83 Index Overview Secondary Index can be created on any combination of attribute names. CREATE INDEX idx_cust_cardnum customer(ccInfo.cardNumber, postalcode) Useful in speeding up the queries. Need to have matching indices with right key-ordering (ccInfo.cardExpiry, postalCode) (type, state, lastName, firstName) "customer": { "ccInfo": { "cardExpiry": "2015-11-11", "cardNumber”:"1212-232-1234", "cardType": "americanexpress” }, "customerId": "customer534", "dateAdded": "2014-04-06", "dateLastActive”:"2014-05-02”, "emailAddress”:”[email protected]", "firstName": "Mckayla", "lastName": "Brown", "phoneNumber": "1-533-290-6403", "postalCode": "92341", "state": "VT", "type": "customer" } Document key: “customer534”
- 83. 84 Indexes Primary Index Index on the document key on the whole bucket CREATE PRIMARY INDEX ON CUSTOMER CREATE PRIMARY INDEX idx_customer_p1 ON CUSTOMER Secondary Index Index on the key-value or document-key CREATE INDEX idx_cx_name ON CUSTOMER(name.lastname); Composite Index Index on more than one key-value CREATE INDEX idx_cx2 ON CUSTOMER(state, city, name.lastname) Functional or Expression Index Index on function or expression on key-values CREATE INDEX idx_cxupper on CUSTOMER(UPPER(state), UPPER(city), UPPER(name.lastname)); Partial index Index subset of items in the bucket CREATE INDEX idx_cx3 ON CUSTOMER(state, city, name.lastname) WHERE status = ‘premium’; CREATE INDEX idx_cx4 ON CUSTOMER(state, city, name.lastname) WHERE status = ‘premium’ and member_since > “2010-06-01” ARRAY INDEX Index individual elements of the arrays CREATE INDEX idx_cx5 ON CUSTOMER(ALL ARRAY v FOR v IN hobbies END) CREATE INDEX idx_cx6 ON CUSTOMER(ALL DISTINCT ARRAY v FOR v IN hobbies END) ARRAY INDEX on expressions CREATE INDEX idx_cx6 ON CUSTOMER(ALL DISTINCT ARRAY v FOR v IN TOKENS(hashtags) END) WHERE type = ‘comments’;
- 84. 85 Indexing Duplicate indexes Distinct names, but same keys, same order and WHERE clause load balancing High availability In 5.0, simply specify replication factor Covering Index and Covered Query Complete query can be answered by the index Index has the keys and expressions to evaluate predicates and projectoins
- 85. OBJECTS
- 86. 87 Travel-sample: Hotel Document "docid": "hotel_25390" { "address": "321 Castro St", … "city": "San Francisco", "country": "United States", "description": "An upscale bed and breakfast in a restored house.", "directions": "at 16th", "geo": { "accuracy": "ROOFTOP", "lat": 37.7634, "lon": -122.435 }, "id": 25390, "name": "Inn on Castro", "phone": "+1 415 861-0321", "price": "$95–$190", "public_likes": ["John Smith", "Joe Carl", "Jane Smith", "Kate Smith"], "reviews": [ { "author": "Mason Koepp", "content": ”blah-blah", "date": "2012-08-23 16:57:56 +0300", "ratings": { "Check in / front desk": 3, "Cleanliness": 3, Document Key city: Attributes (key-value pairs) geo: Object. 1:1 relationship public_likes: Array of strings: Embedded 1:many relationship reviews: Array of objects: Embedded 1:N relationship ratings: object within an array
- 87. 88 Querying Objects > select h.geo from `travel-sample` h where type = 'hotel' and city = 'San Francisco' and meta().id = "hotel_25390”; [ { "geo": { "accuracy": "ROOFTOP", "lat": 37.7634, "lon": -122.435 } } ] > select h.geo.lat, h.geo.lon from `travel-sample` h where type = 'hotel' and city = 'San Francisco' and meta().id = "hotel_25390" [ { "lat": 37.7634, "lon": -122.435 } ] > select reviews[*].ratings from `travel-sample` h where type = 'hotel' and city = 'San Francisco' and meta().id = "hotel_25390" ; [ { "ratings": [ { "Business service": -1, "Check in / front desk": 3, "Cleanliness": 3, "Location": 4, "Overall": 2, "Rooms": 2, "Service": -1, "Value": 2 } ] } ]
- 88. 89 Querying Objects: Accessing data within Objects >select name, city from `travel-sample` h where geo = { "accuracy": "ROOFTOP", "lat": 37.7634, "lon": -122.435 }; [ { "city": "San Francisco", "name": "Inn on Castro" } ] > select h.geo.lat, h.geo.lon from `travel-sample` h where type = 'hotel' and city = 'San Francisco' and meta().id = "hotel_25390" [ { "lat": 37.7634, "lon": -122.435 } ] select name, city from `travel-sample` h where geo.accuracy = "ROOFTOP" and geo.lat between 37.7 and 37.8 and geo.lon between -122.4 and -122.3; [ { "city": "San Francisco", "name": "Courtyard San Francisco Downtown" }, { "city": "San Francisco", "name": "Hotel Vitale" }, { "city": "San Francisco", "name": "South Park" }, { "city": "San Francisco", "name": "City Kayak" },
- 89. 90 Querying Objects: Indexing objects CREATE INDEX idxgeo1 ON `travel-sample` (geo.accuracy, geo.lat, geo.lon) WHERE type = 'hotel'; EXPLAIN select name, city from `travel- sample` h WHERE type = 'hotel' and geo.accuracy = 'ROOFTOP' and geo.lat between 37.7 and 37.8 and geo.lon between -122.4 and -122.3; "#operator": "IndexScan", "index": "idxgeo1", "index_id": "b2cbf035d2a300e1", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "Range": { "High": [ ""ROOFTOP"", "37.8", "-122.3" ], "Inclusion": 3, "Low": [ ""ROOFTOP"", "37.7", "-122.4" ] } } ]
- 90. 91 Querying Objects: Search WITHIN select COUNT(1) FROM system:dual WHERE ANY v WITHIN {"a":1, "b": "Hello"} SATISFIES v = "Hello" END; [ { "$1": 1 } ] select COUNT(1) FROM system:dual WHERE ANY v WITHIN {"a":1, "b": "World"} SATISFIES v = "Hello" END; [ { "$1": 0 } ] SELECT COUNT(1) FROM system:dual WHERE ANY v WITHIN { "a":1, "b": { "x": "Mercury", "y": "Venus", "z": "Earth” } } SATISFIES v = "Earth" END; [ { "$1": 1 } ]
- 91. 92 OBJECT FUNCTIONS Functions Details OBJECT_LENGTH This function returns the number of name-value pairs in the object. OBJECT_NAMES This function returns an array containing the attribute names of the object, OBJECT_PAIRS This function returns an array of arrays of values which contain the attribute name and value pairs of the object, in N1QL collation order of the names OBJECT_VALUES This function returns an array of values or name-value pairs which contain the attribute values of the object, in N1QL collation order of the corresponding names. OBJECT_ADD This function adds new attributes and values to a given object and returns the updated object. OBJECT_REMOVE This function removes the specified attribute and corresponding values from the given object. OBJECT_PUT This function adds new or updates existing attributes and values to a given object, and returns the updated object. OBJECT_UNWRAP This function enables you to unwrap an object without knowing the name in the name-value pair.
- 92. ARRAYS
- 93. 94 JSON Arrays 94 { "Name" : "Jane Smith", "DOB" : "1990-01-30", "hobbies" : ["lego", "piano", "badminton", "robotics"], "scores" : [3.4, 2.9, 9.2, 4.1], "legos" : [ true, 9292, "fighter 2", { "name" : "Millenium Falcon", "type" : "Starwars" } ] } • Arrays in JSON can contain simply values, or any combination of JSON types within the same array. • No type or structure enforcement within the array.
- 94. 95 JSON Arrays 95 { "Name": "Jane Smith", "DOB" : "1990-01-30", "phones" : [ "+1 510-523-3529", "+1 650-392-4923" ], "Billing": [ { "type": "visa", "cardnum": "5827-2842-2847-3909", "expiry": "2019-03" }, { "type": "master", "cardnum": "6274-2542-5847-3949", "expiry": "2018-12" } ] } Billing has two credit card entries, stored as an ARRAY Two phone number entries
- 95. 96 Array Access: Expressions, Functions and Aggregates. • EXPRESSIONS • ARRAY • ANY • EVERY • IN • WITHIN • Construct [elem] • Slice array[start:end] • Selection array[#pos] • FUNCTIONS • ISARRAY • TYPE • ARRAY_APPEND • ARRAY_CONCAT • ARRAY_CONTAINS • ARRAY_DISTINCT • ARRAY_IFNULL • ARRAY_FLATTEN • ARRAY_INSERT • ARRAY_INTERSECT • ARRAY_LENGTH • ARRAY_POSITION • AGGREGATES • ARRAY_AVG • ARRAY_COUNT • ARRAY_MIN • ARRAY_MAX • FUNCTIONS • ARRAY_PREPEND • ARRAY_PUT • ARRAY_RANGE • ARRAY_REMOVE • ARRAY_REPEAT • ARRAY_REPLACE • ARRAY_REVERSE • ARRAY_SORT • ARRAY_STAR • ARRAY_SUM
- 96. 97 Array predicates 97 • Arrays and Objects: Arrays are compared element- wise. Objects are first compared by length; objects of equal length are compared pairwise, with the pairs sorted by name. • IN clause: Use this when you want to evaluate based on specific field. • WITHIN clause: Use this when you don’t know which field contains the value you’re looking for. The WITHIN operator evaluates to TRUE if the right-side value contains the left-side value as a child or descendant. The NOT WITHIN operator evaluates to TRUE if the right-side value does not contain the left- side value as a child or descendant. SELECT * FROM `travel-sample` WHERE type = 'hotel’ AND ANY r IN reviews SATISFIES r.ratings.`Value` >= 3 END; SELECT * FROM `travel-sample` WHERE type = 'hotel’ AND ANY r WITHIN reviews SATISFIES r LIKE '%Ozella%' END; • EVERY: EVERY is a range predicate that tests a Boolean condition over the elements or attributes of a collection, object, or objects. It uses the IN and WITHIN operators to range through the collection. SELECT * FROM `travel-sample` WHERE type = 'hotel’ AND EVERY r IN reviews SATISFIES r.ratings.Cleanliness >= 4 END;
- 97. 98 ARRAYS: UNNEST • UNNEST : If a document or object contains an array, UNNEST performs a join of the nested array with its parent document. Each resulting joined object becomes an input to the query. UNNEST, JOINs can be chained. 98 SELECT r.author, COUNT(r.author) AS authcount FROM `travel-sample` t UNNEST reviews r WHERE t.type="hotel" GROUP BY r.author ORDER BY COUNT(r.author) DESC LIMIT 5; [ { "authcount": 2, "author": "Anita Baumbach" }, { "authcount": 2, "author": "Uriah Gutmann" }, { "authcount": 2, "author": "Ashlee Champlin" }, { "authcount": 2, "author": "Cassie O'Hara" }, { "authcount": 1, "author": "Zoe Kshlerin" } ]
- 98. 99 ARRAYS: NEST • NEST is the inverse of UNNEST. • Nesting is conceptually the inverse of unnesting. Nesting performs a join across two keyspaces. But instead of producing a cross-product of the left and right inputs, a single result is produced for each left input, while the corresponding right inputs are collected into an array and nested as a single array- 99 SELECT * FROM `travel-sample` route NEST `travel-sample` airline ON KEYS route.airlineid WHERE route.type = ‘airline' LIMIT 1; [ { "airline": [ { "callsign": "AIRFRANS", "country": "France", "iata": "AF", "icao": "AFR", "id": 137, "name": "Air France", "type": "airline" } ], "route": { "airline": "AF", "airlineid": "airline_137", "destinationairport": "MRS", "distance": 2881.617376098415, "equipment": "320", "id": 10000, "schedule": [ { "day": 0, "flight": "AF198", "utc": "10:13:00" }, { "day": 0, "flight": "AF547", "utc": "19:14:00" }, { "day": 0, "flight": "AF943",
- 99. 6 N1QL AND JSON : TRANSFORMATIONS
- 100. 101
- 101. 102
- 102. 103 Field names in the dataset SELECT meta.`view`.columns[*].fieldName FROM datagov; [ { "fieldName": [ ":sid", ":id", ":position", ":created_at", ":created_meta", ":updated_at", ":updated_meta", ":meta", "brth_yr", "gndr", "ethcty", "nm", "cnt", "rnk" ] } ]
- 103. 104 Transform ARRAYS into FLAT JSON documents INSERT INTO nynames (KEY UUID(), VALUE kname) SELECT { ":sid":d[0], ":id":d[1], ":position":d[2], ":created_at":d[3], ":created_meta":d[4], ":updated_at":d[5], ":updated_meta":d[6], ":meta":d[7],"brth_yr":d[8], "brth_yr":d[9], "ethcty":d[10], "nm":d[11], "cnt":d[12], "rnk":d[13]} kname FROM (SELECT d FROM datagov UNNEST data d) as u1;
- 104. 105 Transform ARRAYS into FLAT JSON documents INSERT INTO nynames ( KEY UUID(), value o ) SELECT o FROM ( SELECT meta.`view`.columns[*].fieldName f, data FROM datagov) d UNNEST data d1 LET o = OBJECT p:d1[ARRAY_POSITION(d.f, p)] FOR p IN d.f END ;
- 105. ✔ SQL AND N1QL
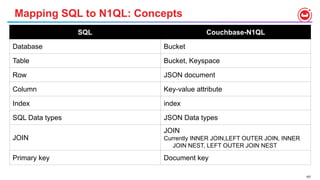
- 106. 107 Mapping SQL to N1QL: Concepts SQL Couchbase-N1QL Database Bucket Table Bucket, Keyspace Row JSON document Column Key-value attribute Index index SQL Data types JSON Data types JOIN JOIN Currently INNER JOIN,LEFT OUTER JOIN, INNER JOIN NEST, LEFT OUTER JOIN NEST Primary key Document key
- 107. 108 Mapping SQL to N1QL SQL Couchbase-N1QL CREATE TABLE couchbase-cli bucket-create ALTER TABLE UPDATE customer SET, UNSET CREATE INDEX i1 on t(a, b, c DESC); CREATE INDEX i1 on t(a, b, c DESC); INSERT INTO INSERT INTO SELECT SELECT JOINS JOIN – INNER JOIN, LEFT OUTER JOIN GROUP BY, HAVING GROUP BY, HAVING ORDER BY a ASC, b DESC ORDER BY a ASC, b DESC OFFSET, LIMIT OFFSET, LIMIT Subqueries Subqueries DELETE FROM DELETE FROM UPDATE UPDATE MERGE MERGE
- 108. 109 Mapping SQL to N1QL 109 SQL N1QL PREPARE PREPARE EXECUTE EXECUTE GRANT GRANT ROLE REVOKE REVOKE ROLE EXPLAIN EXPLAIN DESCRIBE INFER
- 109. 110 Bringing SQL to NoSQL Query Features SQL on RDBMS N1QL Statements SELECT, INSERT, UPDATE, DELETE, MERGE SELECT, INSERT, UPDATE, DELETE, MERGE Query Operations Select, Join, Project, Subqueries Strict Schema Strict Type checking Select, Join, Project, Subqueries Nest & Unnest Look Ma! No Type Mismatch Errors! JSON keys act as columns Schema Predetermined Columns Fully addressable JSON Flexible document structure Data Types SQL Data types Conversion Functions JSON Data types Conversion Functions Query Processing INPUT: Sets of Tuples OUPUT: Set of Tuples INPUT: Sets of JSON OUTPUT: Set of JSON
- 110. 111
- 111. * CALL TO ACTION
- 113. At Connect, we’ll show you how to use the most revolutionary technology in the world to create amazing customer experiences. Register at http://bit.ly/connectSV2017 • 6 hands-on workshops • 5 role-based tracks • 30+ technical and business sessions
- 115. 116 RESOURCES • http://couchbase.com • http://query.couchbase.com • http://forums.couchbase.com • http://dzone.com • http://blog.couchbase.com • N1QL Book : https://blog.couchbase.com/n1ql-practical-guide/