Functional programming for optimization problems in Big Data
12 likes10,183 views

Enterprise Data Workflows with Cascading. Silicon Valley Cloud Computing Meetup talk at Cloud Tech IV, 4/20 2013 http://www.meetup.com/cloudcomputing/events/111082032/























![word count – Cascading app in Java
String docPath = args[ 0 ];
String wcPath = args[ 1 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath );
Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath );
// specify a regex to split "document" text lines into token stream
Fields token = new Fields( "token" );
Fields text = new Fields( "text" );
RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ [](),.]" );
// only returns "token"
Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );
// determine the word counts
Pipe wcPipe = new Pipe( "wc", docPipe );
wcPipe = new GroupBy( wcPipe, token );
wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
.addSource( docPipe, docTap )
.addTailSink( wcPipe, wcTap );
// write a DOT file and run the flow
Flow wcFlow = flowConnector.connect( flowDef );
wcFlow.writeDOT( "dot/wc.dot" );
wcFlow.complete();
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M
24](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-24-320.jpg)
![mapreduce
Every('wc')[Count[decl:'count']]
Hfs['TextDelimited[[UNKNOWN]->['token', 'count']]']['output/wc']']
GroupBy('wc')[by:['token']]
Each('token')[RegexSplitGenerator[decl:'token'][args:1]]
Hfs['TextDelimited[['doc_id', 'text']->[ALL]]']['data/rain.txt']']
[head]
[tail]
[{2}:'token', 'count']
[{1}:'token']
[{2}:'doc_id', 'text']
[{2}:'doc_id', 'text']
wc[{1}:'token']
[{1}:'token']
[{2}:'token', 'count']
[{2}:'token', 'count']
[{1}:'token']
[{1}:'token']
word count – generated flow diagram
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M
25](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-25-320.jpg)
![(ns impatient.core
(:use [cascalog.api]
[cascalog.more-taps :only (hfs-delimited)])
(:require [clojure.string :as s]
[cascalog.ops :as c])
(:gen-class))
(defmapcatop split [line]
"reads in a line of string and splits it by regex"
(s/split line #"[[](),.)s]+"))
(defn -main [in out & args]
(?<- (hfs-delimited out)
[?word ?count]
((hfs-delimited in :skip-header? true) _ ?line)
(split ?line :> ?word)
(c/count ?count)))
; Paul Lam
; github.com/Quantisan/Impatient
word count – Cascalog / Clojure
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M
26](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-26-320.jpg)

![import com.twitter.scalding._
class WordCount(args : Args) extends Job(args) {
Tsv(args("doc"),
('doc_id, 'text),
skipHeader = true)
.read
.flatMap('text -> 'token) {
text : String => text.split("[ [](),.]")
}
.groupBy('token) { _.size('count) }
.write(Tsv(args("wc"), writeHeader = true))
}
word count – Scalding / Scala
Document
Collection
Word
Count
Tokenize
GroupBy
token Count
R
M
28](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-28-320.jpg)



























![## train a RandomForest model
f <- as.formula("as.factor(label) ~ .")
fit <- randomForest(f, data_train, ntree=50)
## test the model on the holdout test set
print(fit$importance)
print(fit)
predicted <- predict(fit, data)
data$predicted <- predicted
confuse <- table(pred = predicted, true = data[,1])
print(confuse)
## export predicted labels to TSV
write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"),
quote=FALSE, sep="t", row.names=FALSE)
## export RF model to PMML
saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/"))
Pattern – create a model in R
57](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-57-320.jpg)
![public class Main {
public static void main( String[] args ) {
String pmmlPath = args[ 0 ];
String ordersPath = args[ 1 ];
String classifyPath = args[ 2 ];
String trapPath = args[ 3 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap ordersTap = new Hfs( new TextDelimited( true, "t" ), ordersPath );
Tap classifyTap = new Hfs( new TextDelimited( true, "t" ), classifyPath );
Tap trapTap = new Hfs( new TextDelimited( true, "t" ), trapPath );
// define a "Classifier" model from PMML to evaluate the orders
ClassifierFunction classFunc = new ClassifierFunction( new Fields( "score" ), pmmlPath );
Pipe classifyPipe = new Each( new Pipe( "classify" ), classFunc.getInputFields(), classFunc, Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "classify" )
.addSource( classifyPipe, ordersTap )
.addTrap( classifyPipe, trapTap )
.addSink( classifyPipe, classifyTap );
// write a DOT file and run the flow
Flow classifyFlow = flowConnector.connect( flowDef );
classifyFlow.writeDOT( "dot/classify.dot" );
classifyFlow.complete();
}
}
Pattern – score a model, within an app
58](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-58-320.jpg)









![(defn parse-gis [line]
"leverages parse-csv for complex CSV format in GIS export"
(first (csv/parse-csv line))
)
(defn etl-gis [gis trap]
"subquery to parse data sets from the GIS source tap"
(<- [?blurb ?misc ?geo ?kind]
(gis ?line)
(parse-gis ?line :> ?blurb ?misc ?geo ?kind)
(:trap (hfs-textline trap))
))
discovery
(specify what you require,
not how to achieve it…
80/20 rule of data prep cost)
68](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-68-320.jpg)


![(defn get-trees [src trap tree_meta]
"subquery to parse/filter the tree data"
(<- [?blurb ?tree_id ?situs ?tree_site
?species ?wikipedia ?calflora ?avg_height
?tree_lat ?tree_lng ?tree_alt ?geohash
]
(src ?blurb ?misc ?geo ?kind)
(re-matches #"^s+Private.*Tree ID.*" ?misc)
(parse-tree ?misc :> _ ?priv ?tree_id ?situs ?tree_site ?raw_species)
((c/comp s/trim s/lower-case) ?raw_species :> ?species)
(tree_meta ?species ?wikipedia ?calflora ?min_height ?max_height)
(avg ?min_height ?max_height :> ?avg_height)
(geo-tree ?geo :> _ ?tree_lat ?tree_lng ?tree_alt)
(read-string ?tree_lat :> ?lat)
(read-string ?tree_lng :> ?lng)
(geohash ?lat ?lng :> ?geohash)
(:trap (hfs-textline trap))
))
discovery
?blurb!! Tree: 412 site 1 at 115 HAWTHORNE AV, on HAWTHORNE AV 22
?tree_id! " 412
?situs"" 115
?tree_site" 1
?species" " liquidambar styraciflua
?wikipedia" http://en.wikipedia.org/wiki/Liquidambar_styraciflua
?calflora http://calflora.org/cgi-bin/species_query.cgi?where-calre
?avg_height" 27.5
?tree_lat" 37.446001565119
?tree_lng" -122.167713417554
?tree_alt" 0.0
?geohash" " 9q9jh0
71](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-71-320.jpg)
![// run analysis and visualization in R
library(ggplot2)
dat_folder <- '~/src/concur/CoPA/out/tree'
data <- read.table(file=paste(dat_folder, "part-00000", sep="/"),
sep="t", quote="", na.strings="NULL", header=FALSE, encoding="UTF8")
summary(data)
t <- head(sort(table(data$V5), decreasing=TRUE)
trees <- as.data.frame.table(t, n=20))
colnames(trees) <- c("species", "count")
m <- ggplot(data, aes(x=V8))
m <- m + ggtitle("Estimated Tree Height (meters)")
m + geom_histogram(aes(y = ..density.., fill = ..count..)) + geom_density()
par(mar = c(7, 4, 4, 2) + 0.1)
plot(trees, xaxt="n", xlab="")
axis(1, labels=FALSE)
text(1:nrow(trees), par("usr")[3] - 0.25, srt=45, adj=1,
labels=trees$species, xpd=TRUE)
grid(nx=nrow(trees))
discovery
72](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-72-320.jpg)





![(defn get-shade [trees roads]
"subquery to join tree and road estimates, maximize for shade"
(<- [?road_name ?geohash ?road_lat ?road_lng
?road_alt ?road_metric ?tree_metric]
(roads ?road_name _ _ _
?albedo ?road_lat ?road_lng ?road_alt ?geohash
?traffic_count _ ?traffic_class _ _ _ _)
(road-metric
?traffic_class ?traffic_count ?albedo :> ?road_metric)
(trees _ _ _ _ _ _ _
?avg_height ?tree_lat ?tree_lng ?tree_alt ?geohash)
(read-string ?avg_height :> ?height)
;; limit to trees which are higher than people
(> ?height 2.0)
(tree-distance
?tree_lat ?tree_lng ?road_lat ?road_lng :> ?distance)
;; limit to trees within a one-block radius (not meters)
(<= ?distance 25.0)
(/ ?height ?distance :> ?tree_moment)
(c/sum ?tree_moment :> ?sum_tree_moment)
;; magic number 200000.0 used to scale tree moment
;; based on median
(/ ?sum_tree_moment 200000.0 :> ?tree_metric)
))
modeling
78](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-78-320.jpg)

![(defn get-gps [gps_logs trap]
"subquery to aggregate and rank GPS tracks per user"
(<- [?uuid ?geohash ?gps_count ?recent_visit]
(gps_logs
?date ?uuid ?gps_lat ?gps_lng ?alt ?speed ?heading
?elapsed ?distance)
(read-string ?gps_lat :> ?lat)
(read-string ?gps_lng :> ?lng)
(geohash ?lat ?lng :> ?geohash)
(c/count :> ?gps_count)
(date-num ?date :> ?visit)
(c/max ?visit :> ?recent_visit)
))
modeling
?uuid ?geohash ?gps_count ?recent_visit
cf660e041e994929b37cc5645209c8ae 9q8yym 7 1972376866448
342ac6fd3f5f44c6b97724d618d587cf 9q9htz 4 1972376690969
32cc09e69bc042f1ad22fc16ee275e21 9q9hv3 3 1972376670935
342ac6fd3f5f44c6b97724d618d587cf 9q9hv3 3 1972376691356
342ac6fd3f5f44c6b97724d618d587cf 9q9hwn 13 1972376690782
342ac6fd3f5f44c6b97724d618d587cf 9q9hwp 58 1972376690965
482dc171ef0342b79134d77de0f31c4f 9q9jh0 15 1972376952532
b1b4d653f5d9468a8dd18a77edcc5143 9q9jh0 18 1972376945348
80](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-80-320.jpg)
![Recommenders often combine multiple signals, via weighted
averages, to rank personalized results:
• GPS of person ∩ road segment
• frequency and recency of visit
• traffic class and rate
• road albedo (sunlight reflection)
• tree shade estimator
Adjusting the mix allows for further personalization at the end use
modeling
(defn get-reco [tracks shades]
"subquery to recommend road segments based on GPS tracks"
(<- [?uuid ?road ?geohash ?lat ?lng ?alt
?gps_count ?recent_visit ?road_metric ?tree_metric]
(tracks ?uuid ?geohash ?gps_count ?recent_visit)
(shades ?road ?geohash ?lat ?lng ?alt ?road_metric ?tree_metric)
))
81](https://image.slidesharecdn.com/cloudtech-130421141715-phpapp01/85/Functional-programming-for-optimization-problems-in-Big-Data-81-320.jpg)

































Ad
More Related Content
What's hot (20)
Similar to Functional programming for optimization problems in Big Data (20)


















Ad
More from Paco Nathan (20)




















Ad
Recently uploaded (20)




















Functional programming for optimization problems in Big Data
- 1. Copyright @2013, Concurrent, Inc. Paco Nathan Concurrent, Inc. San Francisco, CA @pacoid “Functional programming for optimization problems in Big Data” 1
- 2. Cascading: Workflow Abstraction Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Machine Data Cascading Sample Code A Little Theory… Workflows Open Data Example 2
- 3. Q3 1997: inflection point Four independent teams were working toward horizontal scale-out of workflows based on commodity hardware. This effort prepared the way for huge Internet successes in the 1997 holiday season… AMZN, EBAY, Inktomi (YHOO Search), then GOOG MapReduce and the Apache Hadoop open source stack emerged from this. 3
- 4. RDBMS Stakeholder SQL Query result sets Excel pivot tables PowerPoint slide decks Web App Customers transactions Product strategy Engineering requirements BI Analysts optimized code Circa 1996: pre- inflection point 4
- 5. RDBMS Stakeholder SQL Query result sets Excel pivot tables PowerPoint slide decks Web App Customers transactions Product strategy Engineering requirements BI Analysts optimized code Circa 1996: pre- inflection point “Throw it over the wall” 5
- 6. RDBMS SQL Query result sets recommenders + classifiers Web Apps customer transactions Algorithmic Modeling Logs event history aggregation dashboards Product Engineering UX Stakeholder Customers DW ETL Middleware servletsmodels Circa 2001: post- big ecommerce successes 6
- 7. RDBMS SQL Query result sets recommenders + classifiers Web Apps customer transactions Algorithmic Modeling Logs event history aggregation dashboards Product Engineering UX Stakeholder Customers DW ETL Middleware servletsmodels Circa 2001: post- big ecommerce successes “Data products” 7
- 8. Workflow RDBMS near timebatch services transactions, content social interactions Web Apps, Mobile, etc.History Data Products Customers RDBMS Log Events In-Memory Data Grid Hadoop, etc. Cluster Scheduler Prod Eng DW Use Cases Across Topologies s/w dev data science discovery + modeling Planner Ops dashboard metrics business process optimized capacitytaps Data Scientist App Dev Ops Domain Expert introduced capability existing SDLC Circa 2013: clusters everywhere 8
- 9. Workflow RDBMS near timebatch services transactions, content social interactions Web Apps, Mobile, etc.History Data Products Customers RDBMS Log Events In-Memory Data Grid Hadoop, etc. Cluster Scheduler Prod Eng DW Use Cases Across Topologies s/w dev data science discovery + modeling Planner Ops dashboard metrics business process optimized capacitytaps Data Scientist App Dev Ops Domain Expert introduced capability existing SDLC Circa 2013: clusters everywhere “Optimizing topologies” 9
- 10. by Leo Breiman Statistical Modeling: TheTwo Cultures Statistical Science, 2001 bit.ly/eUTh9L references… 10
- 11. Amazon “Early Amazon: Splitting the website” – Greg Linden glinden.blogspot.com/2006/02/early-amazon-splitting-website.html eBay “The eBay Architecture” – Randy Shoup, Dan Pritchett addsimplicity.com/adding_simplicity_an_engi/2006/11/you_scaled_your.html addsimplicity.com.nyud.net:8080/downloads/eBaySDForum2006-11-29.pdf Inktomi (YHOO Search) “Inktomi’s Wild Ride” – Erik Brewer (0:05:31 ff) youtube.com/watch?v=E91oEn1bnXM Google “Underneath the Covers at Google” – Jeff Dean (0:06:54 ff) youtube.com/watch?v=qsan-GQaeyk perspectives.mvdirona.com/2008/06/11/JeffDeanOnGoogleInfrastructure.aspx references… 11
- 12. Cascading: Workflow Abstraction Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Machine Data Cascading Sample Code A Little Theory… Workflows Open Data Example 12
- 13. Cascading – origins API author Chris Wensel worked as a system architect at an Enterprise firm well-known for many popular data products. Wensel was following the Nutch open source project – where Hadoop started. Observation: would be difficult to find Java developers to write complex Enterprise apps in MapReduce – a potential blocker for leveraging new open source technology. 13
- 14. Cascading – functional programming Key insight: MapReduce is based on functional programming – back to LISP in 1970s. Apache Hadoop use cases are mostly about data pipelines, which are functional in nature. To ease staffing problems as “Main Street” Enterprise firms began to embrace Hadoop, Cascading was introduced in late 2007, as a new Java API to implement functional programming for large-scale data workflows: • leverages JVM and Java-based tools without any need to create new languages • allows programmers who have J2EE expertise to leverage the economics of Hadoop clusters 14
- 15. Cascading – functional programming • Twitter, eBay, LinkedIn, Nokia, YieldBot, uSwitch, etc., have invested in open source projects atop Cascading – used for their large-scale production deployments • new case studies for Cascading apps are mostly based on domain-specific languages (DSLs) in JVM languages which emphasize functional programming: Cascalog in Clojure (2010) Scalding in Scala (2012) github.com/nathanmarz/cascalog/wiki github.com/twitter/scalding/wiki Why Adopting the Declarative Programming PracticesWill ImproveYour Return fromTechnology Dan Woods, 2013-04-17 Forbes forbes.com/sites/danwoods/2013/04/17/why-adopting-the-declarative-programming- practices-will-improve-your-return-from-technology/ 15
- 16. Hadoop Cluster source tap source tap sink tap trap tap customer profile DBsCustomer Prefs logs logs Logs Data Workflow Cache Customers Support Web App Reporting Analytics Cubes sink tap Modeling PMML Cascading – definitions • a pattern language for Enterprise Data Workflows • simple to build, easy to test, robust in production • design principles ⟹ ensure best practices at scale 16
- 17. Hadoop Cluster source tap source tap sink tap trap tap customer profile DBsCustomer Prefs logs logs Logs Data Workflow Cache Customers Support Web App Reporting Analytics Cubes sink tap Modeling PMML Cascading – usage • Java API, DSLs in Scala, Clojure, Jython, JRuby, Groovy,ANSI SQL • ASL 2 license, GitHub src, http://conjars.org • 5+ yrs production use, multiple Enterprise verticals 17
- 18. Hadoop Cluster source tap source tap sink tap trap tap customer profile DBsCustomer Prefs logs logs Logs Data Workflow Cache Customers Support Web App Reporting Analytics Cubes sink tap Modeling PMML Cascading – integrations • partners: Microsoft Azure, Hortonworks, Amazon AWS, MapR, EMC, SpringSource, Cloudera • taps: Memcached, Cassandra, MongoDB, HBase, JDBC, Parquet, etc. • serialization: Avro, Thrift, Kryo, JSON, etc. • topologies: Apache Hadoop, tuple spaces, local mode 18
- 19. Cascading – deployments • case studies: Climate Corp, Twitter, Etsy, Williams-Sonoma, uSwitch, Airbnb, Nokia, YieldBot, Square, Harvard, Factual, etc. • use cases: ETL, marketing funnel, anti-fraud, social media, retail pricing, search analytics, recommenders, eCRM, utility grids, telecom, genomics, climatology, agronomics, etc. 19
- 20. Cascading – deployments • case studies: Climate Corp, Twitter, Etsy, Williams-Sonoma, uSwitch, Airbnb, Nokia, YieldBot, Square, Harvard, Factual, etc. • use cases: ETL, marketing funnel, anti-fraud, social media, retail pricing, search analytics, recommenders, eCRM, utility grids, telecom, genomics, climatology, agronomics, etc. workflow abstraction addresses: • staffing bottleneck; • system integration; • operational complexity; • test-driven development 20
- 21. Cascading: Workflow Abstraction Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Machine Data Cascading Sample Code A Little Theory… Workflows Open Data Example 21
- 22. void map (String doc_id, String text): for each word w in segment(text): emit(w, "1"); void reduce (String word, Iterator group): int count = 0; for each pc in group: count += Int(pc); emit(word, String(count)); The Ubiquitous Word Count Definition: count how often each word appears in a collection of text documents This simple program provides an excellent test case for parallel processing, since it illustrates: • requires a minimal amount of code • demonstrates use of both symbolic and numeric values • shows a dependency graph of tuples as an abstraction • is not many steps away from useful search indexing • serves as a “HelloWorld” for Hadoop apps Any distributed computing framework which can runWord Count efficiently in parallel at scale can handle much larger and more interesting compute problems. Document Collection Word Count Tokenize GroupBy token Count R M count how often each word appears in a collection of text documents 22
- 23. Document Collection Word Count Tokenize GroupBy token Count R M 1 map 1 reduce 18 lines code gist.github.com/3900702 word count – conceptual flow diagram cascading.org/category/impatient 23
- 24. word count – Cascading app in Java String docPath = args[ 0 ]; String wcPath = args[ 1 ]; Properties properties = new Properties(); AppProps.setApplicationJarClass( properties, Main.class ); HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties ); // create source and sink taps Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath ); Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath ); // specify a regex to split "document" text lines into token stream Fields token = new Fields( "token" ); Fields text = new Fields( "text" ); RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ [](),.]" ); // only returns "token" Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS ); // determine the word counts Pipe wcPipe = new Pipe( "wc", docPipe ); wcPipe = new GroupBy( wcPipe, token ); wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL ); // connect the taps, pipes, etc., into a flow FlowDef flowDef = FlowDef.flowDef().setName( "wc" ) .addSource( docPipe, docTap ) .addTailSink( wcPipe, wcTap ); // write a DOT file and run the flow Flow wcFlow = flowConnector.connect( flowDef ); wcFlow.writeDOT( "dot/wc.dot" ); wcFlow.complete(); Document Collection Word Count Tokenize GroupBy token Count R M 24
- 25. mapreduce Every('wc')[Count[decl:'count']] Hfs['TextDelimited[[UNKNOWN]->['token', 'count']]']['output/wc']'] GroupBy('wc')[by:['token']] Each('token')[RegexSplitGenerator[decl:'token'][args:1]] Hfs['TextDelimited[['doc_id', 'text']->[ALL]]']['data/rain.txt']'] [head] [tail] [{2}:'token', 'count'] [{1}:'token'] [{2}:'doc_id', 'text'] [{2}:'doc_id', 'text'] wc[{1}:'token'] [{1}:'token'] [{2}:'token', 'count'] [{2}:'token', 'count'] [{1}:'token'] [{1}:'token'] word count – generated flow diagram Document Collection Word Count Tokenize GroupBy token Count R M 25
- 26. (ns impatient.core (:use [cascalog.api] [cascalog.more-taps :only (hfs-delimited)]) (:require [clojure.string :as s] [cascalog.ops :as c]) (:gen-class)) (defmapcatop split [line] "reads in a line of string and splits it by regex" (s/split line #"[[](),.)s]+")) (defn -main [in out & args] (?<- (hfs-delimited out) [?word ?count] ((hfs-delimited in :skip-header? true) _ ?line) (split ?line :> ?word) (c/count ?count))) ; Paul Lam ; github.com/Quantisan/Impatient word count – Cascalog / Clojure Document Collection Word Count Tokenize GroupBy token Count R M 26
- 27. github.com/nathanmarz/cascalog/wiki • implements Datalog in Clojure, with predicates backed by Cascading – for a highly declarative language • run ad-hoc queries from the Clojure REPL – approx. 10:1 code reduction compared with SQL • composable subqueries, used for test-driven development (TDD) practices at scale • Leiningen build: simple, no surprises, in Clojure itself • more new deployments than other Cascading DSLs – Climate Corp is largest use case: 90% Clojure/Cascalog • has a learning curve, limited number of Clojure developers • aggregators are the magic, and those take effort to learn word count – Cascalog / Clojure Document Collection Word Count Tokenize GroupBy token Count R M 27
- 28. import com.twitter.scalding._ class WordCount(args : Args) extends Job(args) { Tsv(args("doc"), ('doc_id, 'text), skipHeader = true) .read .flatMap('text -> 'token) { text : String => text.split("[ [](),.]") } .groupBy('token) { _.size('count) } .write(Tsv(args("wc"), writeHeader = true)) } word count – Scalding / Scala Document Collection Word Count Tokenize GroupBy token Count R M 28
- 29. github.com/twitter/scalding/wiki • extends the Scala collections API so that distributed lists become “pipes” backed by Cascading • code is compact, easy to understand • nearly 1:1 between elements of conceptual flow diagram and function calls • extensive libraries are available for linear algebra, abstract algebra, machine learning – e.g., Matrix API, Algebird, etc. • significant investments by Twitter, Etsy, eBay, etc. • great for data services at scale • less learning curve than Cascalog word count – Scalding / Scala Document Collection Word Count Tokenize GroupBy token Count R M 29
- 30. Cascading: Workflow Abstraction Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Machine Data Cascading Sample Code A Little Theory… Workflows Open Data Example 30
- 31. workflow abstraction – pattern language Cascading uses a “plumbing” metaphor in the Java API, to define workflows out of familiar elements: Pipes, Taps, Tuple Flows, Filters, Joins, Traps, etc. Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Data is represented as flows of tuples. Operations within the flows bring functional programming aspects into Java In formal terms, this provides a pattern language 31
- 32. references… pattern language: a structured method for solving large, complex design problems, where the syntax of the language promotes the use of best practices amazon.com/dp/0195019199 design patterns: the notion originated in consensus negotiation for architecture, later applied in OOP software engineering by “Gang of Four” amazon.com/dp/0201633612 32
- 33. workflow abstraction – literate programming Cascading workflows generate their own visual documentation: flow diagrams In formal terms, flow diagrams leverage a methodology called literate programming Provides intuitive, visual representations for apps – great for cross-team collaboration Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R 33
- 34. references… by Don Knuth Literate Programming Univ of Chicago Press, 1992 literateprogramming.com/ “Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.” 34
- 35. workflow abstraction – business process Following the essence of literate programming, Cascading workflows provide statements of business process This recalls a sense of business process management for Enterprise apps (think BPM/BPEL for Big Data) Cascading creates a separation of concerns between business process and implementation details (Hadoop, etc.) This is especially apparent in large-scale Cascalog apps: “Specify what you require, not how to achieve it.” By virtue of the pattern language, the flow planner then determines how to translate business process into efficient, parallel jobs at scale 35
- 36. references… by Edgar Codd “A relational model of data for large shared data banks” Communications of the ACM, 1970 dl.acm.org/citation.cfm?id=362685 Rather than arguing between SQL vs. NoSQL… structured vs. unstructured data frameworks… this approach focuses on what apps do: the process of structuring data 36
- 37. workflow abstraction – functional relational programming The combination of functional programming, pattern language, DSLs, literate programming, business process, etc., traces back to the original definition of the relational model (Codd, 1970) prior to SQL. Cascalog, in particular, implements more of what Codd intended for a “data sublanguage” and is considered to be close to a full implementation of the functional relational programming paradigm defined in: Moseley & Marks, 2006 “Out of theTar Pit” goo.gl/SKspn 37
- 38. workflow abstraction – functional relational programming The combination of functional programming, pattern language, DSLs, literate programming, business process, etc., traces back to the original definition of the relational model (Codd, 1970) prior to SQL. Cascalog, in particular, implements more of what Codd intended for a “data sublanguage” and is considered to be close to a full implementation of the functional relational programming paradigm defined in: Moseley & Marks, 2006 “Out of theTar Pit” goo.gl/SKspn several theoretical aspects converge into software engineering practices which minimize the complexity of building and maintaining Enterprise data workflows 38
- 39. source: National Geographic “A kind of Cambrian explosion” algorithmic modeling + machine data + curation, metadata + Open Data evolution of feedback loops internet of things + complex analytics accelerated evolution, additional feedback loops 39
- 40. A Thought Exercise Consider that when a company like Catepillar moves into data science, they won’t be building the world’s next search engine or social network They will be optimizing supply chain, optimizing fuel costs, automating data feedback loops integrated into their equipment… Operations Research – crunching amazing amounts of data $50B company, in a $250B market segment Upcoming: tractors as drones – guided by complex, distributed data apps 40
- 42. Two Avenues to the App Layer: scale ➞ complexity➞ Enterprise: must contend with complexity at scale everyday… incumbents extend current practices and infrastructure investments – using J2EE, ANSI SQL, SAS, etc. – to migrate workflows onto Apache Hadoop while leveraging existing staff Start-ups: crave complexity and scale to become viable… new ventures move into Enterprise space to compete using relatively lean staff, while leveraging sophisticated engineering practices, e.g., Cascalog and Scalding 42
- 43. Cascading: Workflow Abstraction Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Machine Data Cascading Sample Code A Little Theory… Workflows Open Data Example 43
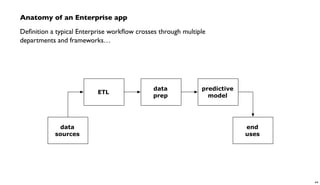
- 44. Anatomy of an Enterprise app Definition a typical Enterprise workflow crosses through multiple departments and frameworks… ETL data prep predictive model data sources end uses 44
- 45. Anatomy of an Enterprise app Definition a typical Enterprise workflow crosses through multiple departments and frameworks… ETL data prep predictive model data sources end uses system integration 45
- 46. Hadoop Cluster source tap source tap sink tap trap tap customer profile DBsCustomer Prefs logs logs Logs Data Workflow Cache Customers Support Web App Reporting Analytics Cubes sink tap Modeling PMML Cascading workflows – taps • taps integrate other data frameworks, as tuple streams • these are “plumbing” endpoints in the pattern language • sources (inputs), sinks (outputs), traps (exceptions) • text delimited, JDBC, Memcached, HBase, Cassandra, MongoDB, etc. • data serialization: Avro, Thrift, Kryo, JSON, etc. • extend a new kind of tap in just a few lines of Java schema and provenance get derived from analysis of the taps 46
- 47. Anatomy of an Enterprise app Definition a typical Enterprise workflow crosses through multiple departments and frameworks… ETL data prep predictive model data sources end uses ANSI SQL for ETL 47
- 48. Hadoop Cluster source tap source tap sink tap trap tap customer profile DBsCustomer Prefs logs logs Logs Data Workflow Cache Customers Support Web App Reporting Analytics Cubes sink tap Modeling PMML Cascading workflows – ANSI SQL • collab with Optiq – industry-proven code base • ANSI SQL parser/optimizer atop Cascading flow planner • JDBC driver to integrate into existing tools and app servers • relational catalog over a collection of unstructured data • SQL shell prompt to run queries • enable analysts without retraining on Hadoop, etc. • transparency for Support, Ops, Finance, et al. a language for queries – not a database, but ANSI SQL as a DSL for workflows 48
- 49. Lingual – shell prompt, catalog cascading.org/lingual 49
- 51. # load the JDBC package library(RJDBC) # set up the driver drv <- JDBC("cascading.lingual.jdbc.Driver", "~/src/concur/lingual/lingual-local/build/libs/lingual-local-1.0.0-wip-dev-jdbc.jar") # set up a database connection to a local repository connection <- dbConnect(drv, "jdbc:lingual:local;catalog=~/src/concur/lingual/lingual-examples/ tables;schema=EMPLOYEES") # query the repository: in this case the MySQL sample database (CSV files) df <- dbGetQuery(connection, "SELECT * FROM EMPLOYEES.EMPLOYEES WHERE FIRST_NAME = 'Gina'") head(df) # use R functions to summarize and visualize part of the data df$hire_age <- as.integer(as.Date(df$HIRE_DATE) - as.Date(df$BIRTH_DATE)) / 365.25 summary(df$hire_age) library(ggplot2) m <- ggplot(df, aes(x=hire_age)) m <- m + ggtitle("Age at hire, people named Gina") m + geom_histogram(binwidth=1, aes(y=..density.., fill=..count..)) + geom_density() Lingual – connecting Hadoop and R 51
- 52. > summary(df$hire_age) Min. 1st Qu. Median Mean 3rd Qu. Max. 20.86 27.89 31.70 31.61 35.01 43.92 Lingual – connecting Hadoop and R cascading.org/lingual 52
- 53. Anatomy of an Enterprise app Definition a typical Enterprise workflow crosses through multiple departments and frameworks… ETL data prep predictive model data sources end usesJ2EE for business logic 53
- 54. Cascading workflows – business logic Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R 54
- 55. Anatomy of an Enterprise app Definition a typical Enterprise workflow crosses through multiple departments and frameworks… ETL data prep predictive model data sources end uses SAS for predictive models 55
- 56. Hadoop Cluster source tap source tap sink tap trap tap customer profile DBsCustomer Prefs logs logs Logs Data Workflow Cache Customers Support Web App Reporting Analytics Cubes sink tap Modeling PMML Pattern – model scoring • migrate workloads: SAS,Teradata, etc., exporting predictive models as PMML • great open source tools – R, Weka, KNIME, Matlab, RapidMiner, etc. • integrate with other libraries – Matrix API, etc. • leverage PMML as another kind of DSL cascading.org/pattern 56
- 57. ## train a RandomForest model f <- as.formula("as.factor(label) ~ .") fit <- randomForest(f, data_train, ntree=50) ## test the model on the holdout test set print(fit$importance) print(fit) predicted <- predict(fit, data) data$predicted <- predicted confuse <- table(pred = predicted, true = data[,1]) print(confuse) ## export predicted labels to TSV write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"), quote=FALSE, sep="t", row.names=FALSE) ## export RF model to PMML saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/")) Pattern – create a model in R 57
- 58. public class Main { public static void main( String[] args ) { String pmmlPath = args[ 0 ]; String ordersPath = args[ 1 ]; String classifyPath = args[ 2 ]; String trapPath = args[ 3 ]; Properties properties = new Properties(); AppProps.setApplicationJarClass( properties, Main.class ); HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties ); // create source and sink taps Tap ordersTap = new Hfs( new TextDelimited( true, "t" ), ordersPath ); Tap classifyTap = new Hfs( new TextDelimited( true, "t" ), classifyPath ); Tap trapTap = new Hfs( new TextDelimited( true, "t" ), trapPath ); // define a "Classifier" model from PMML to evaluate the orders ClassifierFunction classFunc = new ClassifierFunction( new Fields( "score" ), pmmlPath ); Pipe classifyPipe = new Each( new Pipe( "classify" ), classFunc.getInputFields(), classFunc, Fields.ALL ); // connect the taps, pipes, etc., into a flow FlowDef flowDef = FlowDef.flowDef().setName( "classify" ) .addSource( classifyPipe, ordersTap ) .addTrap( classifyPipe, trapTap ) .addSink( classifyPipe, classifyTap ); // write a DOT file and run the flow Flow classifyFlow = flowConnector.connect( flowDef ); classifyFlow.writeDOT( "dot/classify.dot" ); classifyFlow.complete(); } } Pattern – score a model, within an app 58
- 59. Customer Orders Classify Scored Orders GroupBy token Count PMML Model M R Failure Traps Assert Confusion Matrix Pattern – score a model, using pre-defined Cascading app cascading.org/pattern 59
- 60. PMML – vendor coverage 60
- 61. ETL data prep predictive model data sources end uses Lingual: DW → ANSI SQL Pattern: SAS, R, etc. → PMML business logic in Java, Clojure, Scala, etc. sink taps for Memcached, HBase, MongoDB, etc. source taps for Cassandra, JDBC, Splunk, etc. Anatomy of an Enterprise app Cascading allows multiple departments to integrate their workflow components into one app, one JAR file 61
- 62. Cascading: Workflow Abstraction Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R Machine Data Cascading Sample Code A Little Theory… Workflows Open Data Example 62
- 63. Palo Alto is quite a pleasant place • temperate weather • lots of parks, enormous trees • great coffeehouses • walkable downtown • not particularly crowded On a nice summer day, who wants to be stuck indoors on a phone call? Instead, take it outside – go for a walk And example open source project: github.com/Cascading/CoPA/wiki 63
- 64. 1. Open Data about municipal infrastructure (GIS data: trees, roads, parks) ✚ 2. Big Data about where people like to walk (smartphone GPS logs) ✚ 3. some curated metadata (which surfaces the value) 4. personalized recommendations: “Find a shady spot on a summer day in which to walk near downtown Palo Alto.While on a long conference call. Sipping a latte or enjoying some fro-yo.” Scrub token Document Collection Tokenize Word Count GroupBy token Count Stop Word List Regex token HashJoin Left RHS M R 64
- 65. The City of Palo Alto recently began to support Open Data to give the local community greater visibility into how their city government operates This effort is intended to encourage students, entrepreneurs, local organizations, etc., to build new apps which contribute to the public good paloalto.opendata.junar.com/dashboards/7576/geographic-information/ discovery 65
- 66. GIS about trees in Palo Alto: discovery 66
- 67. Geographic_Information,,, "Tree: 29 site 2 at 203 ADDISON AV, on ADDISON AV 44 from pl"," Private: -1 Tree ID: 29 Street_Name: ADDISON AV Situs Number: 203 Tree Site: 2 Species: Celtis australis Source: davey tree Protected: Designated: Heritage: Appraised Value: Hardscape: None Identifier: 40 Active Numeric: 1 Location Feature ID: 13872 Provisional: Install Date: ","37.4409634615283,-122.15648458861,0.0 ","Point" "Wilkie Way from West Meadow Drive to Victoria Place"," Sequence: 20 Street_Name: Wilkie Way From Street PMMS: West Meadow Drive To Street PMMS: Victoria Place Street ID: 598 (Wilkie Wy, Palo Alto) From Street ID PMMS: 689 To Street ID PMMS: 567 Year Constructed: 1950 Traffic Count: 596 Traffic Index: residential local Traffic Class: local residential Traffic Date: 08/24/90 Paving Length: 208 Paving Width: 40 Paving Area: 8320 Surface Type: asphalt concrete Surface Thickness: 2.0 Base Type Pvmt: crusher run base Base Thickness: 6.0 Soil Class: 2 Soil Value: 15 Curb Type: Curb Thickness: Gutter Width: 36.0 Book: 22 Page: 1 District Number: 18 Land Use PMMS: 1 Overlay Year: 1990 Overlay Thickness: 1.5 Base Failure Year: 1990 Base Failure Thickness: 6 Surface Treatment Year: Surface Treatment Type: Alligator Severity: none Alligator Extent: 0 Block Severity: none Block Extent: 0 Longitude and Transverse Severity: none Longitude and Transverse Extent: 0 Ravelling Severity: none Ravelling Extent: 0 Ridability Severity: none Trench Severity: none Trench Extent: 0 Rutting Severity: none Rutting Extent: 0 Road Performance: UL (Urban Local) Bike Lane: 0 Bus Route: 0 Truck Route: 0 Remediation: Deduct Value: 100 Priority: Pavement Condition: excellent Street Cut Fee per SqFt: 10.00 Source Date: 6/10/2009 User Modified By: mnicols Identifier System: 21410 ","-122.1249640794,37.4155803115645,0.0 -122.124661859039,37.4154224594993,0.0 -122.124587720719,37.4153758330704,0.0 -122.12451895942,37.4153242300888,0.0 -122.124456098457,37.4152680432944,0.0 -122.124399616238,37.4152077003122,0.0 -122.124374937753,37.4151774433318,0.0 ","Line" discovery (unstructured data…) 67
- 68. (defn parse-gis [line] "leverages parse-csv for complex CSV format in GIS export" (first (csv/parse-csv line)) ) (defn etl-gis [gis trap] "subquery to parse data sets from the GIS source tap" (<- [?blurb ?misc ?geo ?kind] (gis ?line) (parse-gis ?line :> ?blurb ?misc ?geo ?kind) (:trap (hfs-textline trap)) )) discovery (specify what you require, not how to achieve it… 80/20 rule of data prep cost) 68
- 69. discovery (ad-hoc queries get refined into composable predicates) Identifier: 474 Tree ID: 412 Tree: 412 site 1 at 115 HAWTHORNE AV Tree Site: 1 Street_Name: HAWTHORNE AV Situs Number: 115 Private: -1 Species: Liquidambar styraciflua Source: davey tree Hardscape: None 37.446001565119,-122.167713417554,0.0 Point 69
- 71. (defn get-trees [src trap tree_meta] "subquery to parse/filter the tree data" (<- [?blurb ?tree_id ?situs ?tree_site ?species ?wikipedia ?calflora ?avg_height ?tree_lat ?tree_lng ?tree_alt ?geohash ] (src ?blurb ?misc ?geo ?kind) (re-matches #"^s+Private.*Tree ID.*" ?misc) (parse-tree ?misc :> _ ?priv ?tree_id ?situs ?tree_site ?raw_species) ((c/comp s/trim s/lower-case) ?raw_species :> ?species) (tree_meta ?species ?wikipedia ?calflora ?min_height ?max_height) (avg ?min_height ?max_height :> ?avg_height) (geo-tree ?geo :> _ ?tree_lat ?tree_lng ?tree_alt) (read-string ?tree_lat :> ?lat) (read-string ?tree_lng :> ?lng) (geohash ?lat ?lng :> ?geohash) (:trap (hfs-textline trap)) )) discovery ?blurb!! Tree: 412 site 1 at 115 HAWTHORNE AV, on HAWTHORNE AV 22 ?tree_id! " 412 ?situs"" 115 ?tree_site" 1 ?species" " liquidambar styraciflua ?wikipedia" http://en.wikipedia.org/wiki/Liquidambar_styraciflua ?calflora http://calflora.org/cgi-bin/species_query.cgi?where-calre ?avg_height" 27.5 ?tree_lat" 37.446001565119 ?tree_lng" -122.167713417554 ?tree_alt" 0.0 ?geohash" " 9q9jh0 71
- 72. // run analysis and visualization in R library(ggplot2) dat_folder <- '~/src/concur/CoPA/out/tree' data <- read.table(file=paste(dat_folder, "part-00000", sep="/"), sep="t", quote="", na.strings="NULL", header=FALSE, encoding="UTF8") summary(data) t <- head(sort(table(data$V5), decreasing=TRUE) trees <- as.data.frame.table(t, n=20)) colnames(trees) <- c("species", "count") m <- ggplot(data, aes(x=V8)) m <- m + ggtitle("Estimated Tree Height (meters)") m + geom_histogram(aes(y = ..density.., fill = ..count..)) + geom_density() par(mar = c(7, 4, 4, 2) + 0.1) plot(trees, xaxt="n", xlab="") axis(1, labels=FALSE) text(1:nrow(trees), par("usr")[3] - 0.25, srt=45, adj=1, labels=trees$species, xpd=TRUE) grid(nx=nrow(trees)) discovery 72
- 73. discovery sweetgum analysis of the tree data: 73
- 75. 9q9jh0 geohash with 6-digit resolution approximates a 5-block square centered lat: 37.445, lng: -122.162 modeling 75
- 76. Each road in the GIS export is listed as a block between two cross roads, and each may have multiple road segments to represent turns: " -122.161776959558,37.4518836690781,0.0 " -122.161390381489,37.4516410983794,0.0 " -122.160786011735,37.4512589903357,0.0 " -122.160531178368,37.4510977281699,0.0 modeling ( lat0, lng0, alt0 ) ( lat1, lng1, alt1 ) ( lat2, lng2, alt2 ) ( lat3, lng3, alt3 ) NB: segments in the raw GIS have the order of geo coordinates scrambled: (lng, lat, alt) 76
- 77. 9q9jh0 X X X Filter trees which are too far away to provide shade. Calculate a sum of moments for tree height × distance, as an estimator for shade: modeling 77
- 78. (defn get-shade [trees roads] "subquery to join tree and road estimates, maximize for shade" (<- [?road_name ?geohash ?road_lat ?road_lng ?road_alt ?road_metric ?tree_metric] (roads ?road_name _ _ _ ?albedo ?road_lat ?road_lng ?road_alt ?geohash ?traffic_count _ ?traffic_class _ _ _ _) (road-metric ?traffic_class ?traffic_count ?albedo :> ?road_metric) (trees _ _ _ _ _ _ _ ?avg_height ?tree_lat ?tree_lng ?tree_alt ?geohash) (read-string ?avg_height :> ?height) ;; limit to trees which are higher than people (> ?height 2.0) (tree-distance ?tree_lat ?tree_lng ?road_lat ?road_lng :> ?distance) ;; limit to trees within a one-block radius (not meters) (<= ?distance 25.0) (/ ?height ?distance :> ?tree_moment) (c/sum ?tree_moment :> ?sum_tree_moment) ;; magic number 200000.0 used to scale tree moment ;; based on median (/ ?sum_tree_moment 200000.0 :> ?tree_metric) )) modeling 78
- 79. M tree Join Calculate distance shade Filter height Sum moment REstimate traffic R road Filter distance M M Filter sum_moment (flow diagram, shade) modeling 79
- 80. (defn get-gps [gps_logs trap] "subquery to aggregate and rank GPS tracks per user" (<- [?uuid ?geohash ?gps_count ?recent_visit] (gps_logs ?date ?uuid ?gps_lat ?gps_lng ?alt ?speed ?heading ?elapsed ?distance) (read-string ?gps_lat :> ?lat) (read-string ?gps_lng :> ?lng) (geohash ?lat ?lng :> ?geohash) (c/count :> ?gps_count) (date-num ?date :> ?visit) (c/max ?visit :> ?recent_visit) )) modeling ?uuid ?geohash ?gps_count ?recent_visit cf660e041e994929b37cc5645209c8ae 9q8yym 7 1972376866448 342ac6fd3f5f44c6b97724d618d587cf 9q9htz 4 1972376690969 32cc09e69bc042f1ad22fc16ee275e21 9q9hv3 3 1972376670935 342ac6fd3f5f44c6b97724d618d587cf 9q9hv3 3 1972376691356 342ac6fd3f5f44c6b97724d618d587cf 9q9hwn 13 1972376690782 342ac6fd3f5f44c6b97724d618d587cf 9q9hwp 58 1972376690965 482dc171ef0342b79134d77de0f31c4f 9q9jh0 15 1972376952532 b1b4d653f5d9468a8dd18a77edcc5143 9q9jh0 18 1972376945348 80
- 81. Recommenders often combine multiple signals, via weighted averages, to rank personalized results: • GPS of person ∩ road segment • frequency and recency of visit • traffic class and rate • road albedo (sunlight reflection) • tree shade estimator Adjusting the mix allows for further personalization at the end use modeling (defn get-reco [tracks shades] "subquery to recommend road segments based on GPS tracks" (<- [?uuid ?road ?geohash ?lat ?lng ?alt ?gps_count ?recent_visit ?road_metric ?tree_metric] (tracks ?uuid ?geohash ?gps_count ?recent_visit) (shades ?road ?geohash ?lat ?lng ?alt ?road_metric ?tree_metric) )) 81
- 82. ‣ addr: 115 HAWTHORNE AVE ‣ lat/lng: 37.446, -122.168 ‣ geohash: 9q9jh0 ‣ tree: 413 site 2 ‣ species: Liquidambar styraciflua ‣ est. height: 23 m ‣ shade metric: 4.363 ‣ traffic: local residential, light traffic ‣ recent visit: 1972376952532 ‣ a short walk from my train stop ✔ apps 82
- 83. Enterprise DataWorkflows with Cascading O’Reilly, 2013 amazon.com/dp/1449358721 references… 83
- 84. blog, dev community, code/wiki/gists, maven repo, commercial products, career opportunities: cascading.org zest.to/group11 github.com/Cascading conjars.org goo.gl/KQtUL concurrentinc.com drill-down… Copyright @2013, Concurrent, Inc.Hiring for Java API developers in SF! 84