fundamentalsofeventdrivenmicroservices11728489736099.pdf
0 likes13 views

Event Driven Architecture


































































![(Almost) self-documenting
{
"type" : "record",
"name" : "User",
"namespace" : "com.example",
"fields" : [
{"name": "username", "type": “string"},
{"name": "phone", "type": [null,"int"], "default" : null},
{"name": "address", "type": "string", "default": “UNKNOWN"},
{"name": "country", "type": "enum", "symbols": ["CA", "US", "OTHER"],
"doc" : "The user's country. Select other if not in list"}
]
}](https://image.slidesharecdn.com/fundamentalsofeventdrivenmicroservices11728489736099-241021085110-2c61dcf9/85/fundamentalsofeventdrivenmicroservices11728489736099-pdf-68-320.jpg)

























































































![[@IndeedEng] Logrepo: Enabling Data-Driven Decisions](https://cdn.slidesharecdn.com/ss_thumbnails/indeedenglogrepo-140210123935-phpapp01-thumbnail.jpg?width=560&fit=bounds)





















Ad
More Related Content
Similar to fundamentalsofeventdrivenmicroservices11728489736099.pdf (20)
Recently uploaded (20)


















Ad
fundamentalsofeventdrivenmicroservices11728489736099.pdf
- 2. Table of Contents Part 1: Problems, Communication, and Event-Driven basics Part 2: Event Modelling, Schemas, & Bootstrapping Domain Data Part 3: Service Modelling, Using the DCL, & Examples
- 3. System Architectures It’s all tradeoffs
- 6. (Near-) Real Time updates
- 7. Coupling
- 8. How do we handle these issues in the real world?
- 9. First, let’s look at Communication Structures
- 10. Communication Structures • Business • Implementation • Data
- 11. Business Communication Structure What do we do to achieve our business goals?
- 15. Implementation Communication Structure How do we optimize the processes that lead to our business goals?
- 17. Data Communication Structures How do we get the data we need for our business processes?
- 19. The Implementation Communication Structure Also, The Data Communication Structure!
- 20. Ad-hoc Data Communication Structures
- 21. Synchronous Services can be used to help solve these problems
- 23. Fan-Out
- 24. Scaling Issues
- 25. Boundary & Implementation Issues
- 26. Where do Synchronous Services work well?
- 27. Many companies succeed with synchronous services! It’s all about tradeoffs
- 29. Events are Business Facts
- 30. Example E-commerce • Stores, Merchants, Products, Users, Accounts Shipping • Warehouses, Orders, Shipments, Drivers, Trucks
- 31. Product A has 100 units of stock User A has placed an order, ID=1234 Merchant 100’s minimum order amount is $50 Publish the Facts
- 33. The Event-Broker stores all events and event streams
- 34. The Event Stream (Immutable Log)
- 35. Partitions for Scalability and Data Locality
- 42. Principle Treat domain event data as a first-class citizen
- 43. Does this mean everything should be written to an event-stream? No
- 44. Event Types & Streams 1) Entity 2) Keyed Event 3) Unkeyed Event
- 45. 1) Entity VIN MAKE MODEL COLOUR A1 Ford F150 Tan B2 Toyota Camry Gold Cars ID FIRST LAST 123 Adam Bellemare 444 Guy Incognito People Key Value An entity has a unique key VIN is Key
- 46. Materialize Entities into Each Service Each event is the current state of a (keyed) entity! Partition 0 Overwrite “9” with “2”
- 47. 2) Keyed Events VIN INFRACTION AMOUNT DATE DRIVER_ID A1 Speeding $150 2018-10-07 123 A1 Parking $25 2018-11-11 123 B2 Parking $25 2018-11-13 444 Tickets Issued Key Value Multiple events with same VIN
- 48. 2) Keyed Events VIN INFRACTION AMOUNT DATE DRIVER_ID A1 Speeding $150 2018-10-07 123 A1 Parking $25 2018-11-11 123 B2 Parking $25 2018-11-13 444 Tickets Issued Key Value Multiple events with same VIN “This ticket belongs to VIN ID X”
- 49. Aggregating State from Keyed Events Keyed by Shape Partition 0 Partition 1 Instance 1 Instance 0 eg: Total Ticket Costs
- 50. 3) Unkeyed Events LICENSE PLATE CAMERA_ID DATETIME IMAGE_URI ZXJ123 123 2020-07-07… s3://… ABC123 234 2020-07-08… hdfs://… ACBZ900 345 2020-07-08… c:/program… Intersection Traffic Camera Value
- 51. 3) Unkeyed Events LICENSE PLATE CAMERA_ID DATETIME IMAGE_URI ZXJ123 123 2020-07-07… s3://… ABC123 234 2020-07-08… hdfs://… ACBZ900 345 2020-07-08… c:/program… Not that Common - Usually have a key! Value May be found in “dumb” data pipelining
- 52. A Simple Enrichment Example Cars Tickets Ticket $ per Car 1) Materialize 1) Aggregate 2) Join 3) Emit
- 53. Break
- 54. Part 2: Event Modelling, Schemas, & Bootstrapping Domain Data
- 55. “The fundamental problem of communication is that of reproducing at one point, either exactly or approximately, a message selected at another point.” - Claude Shannon, Father of Communication Theory
- 56. Modelling Events using Domain-Driven Design
- 57. Modelling Events What business occurrence does this event represent?
- 58. Event Modelling Example SALES FACTS FK ITEM_ID FK STORE_ID PRICE PAYMENT ITEM DIMENSIONS PK ITEM_ID NAME BRAND CATEGORY STORE DIMENSIONS PK STORE_ID STORE_NAME ADDRESS CATEGORY Entity Stream Store Stream Key: Store_Id Event Stream Sales Stream Key: N/A Entity Stream Item Stream Key: Item_Id
- 59. Event Modelling Example - Alternative SALES FACTS PK SALES_ID FK ITEM_ID FK STORE_ID PRICE PAYMENT ITEM DIMENSIONS PK ITEM_ID NAME BRAND CATEGORY STORE DIMENSIONS PK STORE_ID STORE_NAME ADDRESS CATEGORY Entity Stream Store Stream Key: Store_Id Entity Stream Item Stream Key: Item_Id Sales Stream Key: Sales_Id Entity Stream
- 60. Event Modelling Example - Denormalized SALES FACTS PK SALES_ID FK ITEM_ID FK STORE_ID PRICE PAYMENT ITEM DIMENSIONS PK ITEM_ID NAME BRAND CATEGORY STORE DIMENSIONS PK STORE_ID STORE_NAME ADDRESS CATEGORY Enriched Sales Stream Key: Sales_Id Merged Entity Stream Join Join
- 61. Unstructured Data A recipe for disaster
- 63. Real-life bloopers isScreenOn: “yes” “no” 1 0 true false null productId: null 1234 “null” “<null>” “%3cnull%3e” premium: true false 4040 null “null”
- 64. Consumer Pain
- 65. Schemas ID (INTEGER) COLOUR (NULL, STRING) DEFAULT: NULL TIME (DATETIME) 100 Red 2020-08-08… 200 NULL 2020-08-08…
- 66. Producer Responsibility: Create events that match the schema
- 67. Schema Options • Apache Avro • Google’s Protobuf • JSONSchema (not plain JSON!)
- 68. (Almost) self-documenting { "type" : "record", "name" : "User", "namespace" : "com.example", "fields" : [ {"name": "username", "type": “string"}, {"name": "phone", "type": [null,"int"], "default" : null}, {"name": "address", "type": "string", "default": “UNKNOWN"}, {"name": "country", "type": "enum", "symbols": ["CA", "US", "OTHER"], "doc" : "The user's country. Select other if not in list"} ] }
- 69. Schema Evolution
- 70. Consuming & Converting Events
- 71. Backwards Compatible Can convert a V2 event to V3 format at Consumer
- 72. Forwards Compatible Can convert a V3 event to V2 format at Consumer
- 73. Full Transitive
- 75. Schema Registry
- 76. Schema Registry
- 79. Breaking Changes New Streams New offsets Migrating consumers Reprocessing
- 82. Criteria • Performance & Throughput • Indefinite retention • Tiered storage • Security & Access Control • Adoption & Open Source • 3rd-party options and tools
- 84. Indefinite Retention It’s just bytes on disk!
- 85. Tiered Storage Put those bytes in the Cloud!
- 86. Security and Access Control • Secure / Encrypted connections • Data Encryption (Field Level Encryption!) • Access Control Lists (ACLs) • Enforce single-writer principle • Track stream ownership and subscriptions
- 87. Adoption & Open Source • Avoid vendor lock-in • Hire talent • Fix own issues • Extended network
- 88. 3rd Party Options & Tools • Schema Registry • Stream Access & Visualization Tooling • Change-Data Capture Tooling • Hosting
- 89. Options Apache Kafka Apache Pulsar AWS Kinesis Azure Event Hub Google Pub Sub Limited Retention (2-52 Weeks) Small Community Tiered Storage Tiered Storage (OSS & Private)
- 90. Populating Event Streams for Data Communication
- 91. What is it that we’re willing to do to provide reliable domain data? Principle: Use the event-broker as the single source of truth
- 94. Forked-Write Anti-Pattern Can’t write to both data stores atomically!
- 99. Forked-Write Anti-Pattern What else can we do?
- 100. Transactional Outbox
- 101. Transactional Outbox
- 102. Transactional Outbox
- 103. Transactional Outbox Works! But can be challenging to set up!
- 104. Pattern: Materialize after Write
- 105. Pattern: Materialize after Write
- 106. Question Won’t these options slow down the application?
- 107. Liberating Data from Legacy Systems
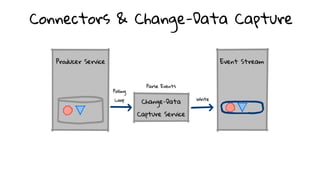
- 108. Connectors & Change-Data Capture
- 109. Connectors & CDC Pros Flexible Scalable Single Source of Truth
- 110. Connectors & CDC Cons Idiosyncracies Overhead Performance Impact Coupling on Internal Data Model Brittle & Reactive
- 111. It’s not one or the other! Point-to-Point or Event-Driven?
- 112. Event Streams are part of the API
- 113. Questions?
- 114. Part 3: Service Modelling, Using Event Streams, & Examples
- 115. The Microservice Tax
- 117. Paying the tax lets your users focus on building the services
- 118. How do you model your services? Use Domain-Driven Design (again)
- 119. Modelling Services Build services around business functions
- 120. Consider the Modular Monolith
- 122. Modelling Services It’s an art as much as a science
- 123. Eg Workflows built from Services
- 124. Let’s look at a subset
- 125. Payment Processing
- 126. Payment Processing
- 127. Payment Processing KEY VALUE OrderId List(ItemId) CustomerInfo KEY VALUE OrderId List(ItemId) CustomerInfo PaymentResults KEY VALUE OrderId PaymentFailureInfo PaymentAPIInfo
- 128. Payment Processing KEY VALUE OrderId List(ItemId) CustomerInfo KEY VALUE OrderId List(ItemId) CustomerInfo KEY VALUE OrderId PaymentInfo KEY VALUE OrderId PaymentResults
- 129. Service Decides Payment Failure Try 3 times Failed 3 times
- 130. Payment Processing: Internal State
- 131. Payment Processing: Internal State
- 134. Reduce Complexity with Field-Level Encryption
- 135. Reduce Complexity with Field-Level Encryption KEY VALUE OrderId List(ItemId) CustomerInfo //Encrypted PaymentInfo (CC, Address, etc) Only Authorized Services can Decrypt the Fields!
- 136. Reduce Complexity with Field-Level Encryption KEY VALUE OrderId List(ItemId) CustomerInfo //Encrypted PaymentInfo (CC, Address, etc) KEY VALUE OrderId PaymentFailureInfo PaymentAPIInfo //Encrypted PaymentResults Only Authorized Services can Decrypt the Fields!
- 138. Expanded
- 139. Schemas KEY VALUE OrderId List(ItemId) CustomerInfo KEY VALUE ItemId Map(Location,Quantity) KEY VALUE OrderId Location FulfimentInfo List(ItemId) CustomerInfo
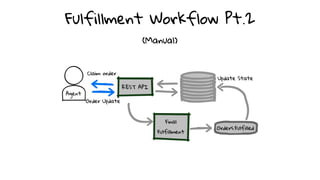
- 140. Fulfillment Workflow Pt.1 (Automated) High-Priority Materialization!
- 142. Unfulfilled?
- 143. Compensation KEY VALUE FulfimentId Location OrderId List(ItemId) CustomerInfo KEY VALUE OrderId State List(ItemId) CustomerInfo
- 145. In Conclusion…
- 146. Event streams as the DCL
- 147. Event Streams: The Data Communication Layer
- 149. Services Align with Business
- 151. Questions, please!